







目录
1.引言
面向对象分析(OOA)、面向对象设计(00D)和面向对象编程(OOP)是面向对象开发的3个主要环节。
在以往的工作中,作者发现,很多软件工程师,尤其是初级软件工程师,他们没有太多的项目经验,或者在参与的项目中,基本是基于开发框架编写CRUD代码,导致欠缺代码的分析、设计能力。当他们拿到笼统的开发需求时,往往不知道从何入手。
如何做需求分析?如何做职责划分?需要定义哪些类?每个类应该具有哪些属性和方法?类之间应该如何交互?如何将类组装成一个可执行的程序?对于上述问题的解决,他们往往没有清晰的思路,更别提利用成熟的设计原则、设计模式开发出具有高内聚、低耦合、易扩展、易读等特性的高质量代码了。
因此,本节通过一个开发案例,介绍基础的需求分析、职责划分、类的定义、交互和组装运行,进而帮助读者了解如何进行面向对象分析、面向对象设计和面向对象编程,并为后面的设计原则和设计模式的学习打好基础。
2.案例介绍和难点剖析
假设我们正在参与一个微服务的开发。微服务通过 HTTP 暴露接口给其他系统调用,换句话说,其他系统通过 URL调用微服务的接口。某天,项目管理者对我们说:“为了保证接口调用的安全性,需要设计和实现接口调用的鉴权功能,只有经过认证的系统,才能调用微服务的接口。希望你们负责这个任务,争取尽快上线这个功能。”这个时候,我们可能感到无从下手原因有下列两点。
(1)需求不明确
项目管理者提出的需求有些模糊和笼统,不够具体和细化,与落地进行设计和编码还有一定的距离。人的大脑不擅长思考过于抽象的问题,而真实的软件开发中的需求几乎都不太明确。
前面讲过,面向对象分析的主要分析对象是“需求”,因此,我们可以将面向对象分析看作“需求分析”。实际上,无论是需求分析还是面向对象分析,首先要做的是将笼统的需求细化到足够清晰和可执行。为了达到这个目的,我们需要进行沟通、挖掘、分析、假设和梳理弄清楚有哪些具体需求、哪些需求是现在要实现的、哪些需求是未来可能要实现的和哪些需求是不必考虑的。
(2)缺少锻炼,经验不足
相比单纯的业务 CRUD开发,鉴权功能的开发更有难度。鉴权是一个与具体业务无关的功能,我们可以把它开发成一个独立的框架,集成到很多业务系统中。而作为被很多系统复用的通用框架,相比普通的业务代码,对代码质量的要求更高。
开发这样的通用框架,对工程师的需求分析能力、设计能力、编码能力,甚至逻辑思维能力的要求,都比较高。如果读者平时进行的是简单的CRUD业务开发,那么对这些能力的训练肯定不会太多,一旦遇到过于笼统的开发需求,可能因为经验不足而不知从何入手。
3.如何进行面向对象分析
实际上,需求分析工作琐碎,没有固定章法可寻,因此,作者不打算介绍用处不大的方法论,而是通过鉴权功能开发案例,给读者展示需求分析的完整思路,希望读者能够举一反三。需求分析的过程是一个不断迭代优化的过程。对于需求分析,我们不要试图立即给出完善的解决方案,而是先给出一个粗糙的基础方案,这样就有了迭代的基础,然后慢慢优化,这种思路能够让我们摆脱无从下手的窘境。我们把整个需求分析过程分为循序渐进的4个步骤,最后形成一个可执行、可落地的需求列表。
(1)基础分析
简单、常用的鉴权方式是使用用户名和密码进行认证。我们给每个允许访问接口的调用方派发一个 AppID(相当于用户名)和密码。调用方在进行接口请求时,会“携带”自己的AppID 和密码。微服务在接收到接口调用请求之后,解析出AppID 和密码,并与存储在微服务端的 AppID 和密码进行比对,如果一致,则认证成功,允许接口调用请求;否则,拒绝接口调用请求。
(2)第一轮分析优化
不过,基于用户名和密码的鉴权方式,每次都要明文传输密码,密码容易被截获。如果我们先借助加密算法(如SHA)对密码进行加密,再传递到微服务端验证,那么是不是就安全了呢?实际上,这样也是不安全的,因为 AppID 和加密之后的密码照样可以被未认证系统(或者“黑客”)截获。未认证系统可以“携带”这个加密之后的密码和对应的APID,伪装成已认证系统来访问接口。这就是经典的“重放攻击”。
先提出问题,再解决问题,这是一个非常好的达代优化方法、对于上面的密码传输安全问题,我们可以借助Qauth验证的思路来解决。调用方法请求接口的URL与AppID、密码拼接,然后进行加密,生成一个Token。在进行接口请求时,调用方法将这个Token和AppID与URL一起传递给微服务端。微服务端接收这些数据之后,根据AppID从数据库中取出对应的密码,并通过同样的Token生成算法,生成另一个Token。然后,使用这个新生成的Token与调用方传递过来的Token进行对比, 如果一致,则允许接口调用请求; 否则,拒绝接口调用请求,优化之后的鉴权过程如下图所示。

(3)第二轮分析优化
不过,上述设计仍然存在重放攻击风险,还是不够安全。每个URL拼接AppID、密码生成的Token 都是固定的。未认证系统截获URL、Token和AppID之后,仍然可以通过重放攻击的方式,伪装成认证系统,调用这个 URL对应的接口。
为了解决这个问题,我们可以进一步优化Token生成算法,即引入一个随机变量,让每次接口请求生成的 Token 都不一样。我们可以选择时间戳作为随机变量。原来的 Token 是通过对URL、AppID 和密码进行加密而生成的,现在,我们通过对URL、AppID、密码和时间戳进行加密来生成 Token。在进行接口请求时,调用方将Token、AppID、时间戳与URL 一起传递给微服务端。
微服务端在收到这些数据之后,会验证当前时间戳与传递过来的时间戳是否在有效时间窗口内(如1分钟)。如果超过有效时间,则判定Token 过期,拒绝接口请求。如果没有超过有效时间,则说明Token 没有过期,然后通过同样的Token生成算法,在微服务端生成新的Token,并与调用方传递过来的Token比对,如果一致,则允许接口调用请求;否则,拒绝接口调用请求。优化之后的鉴权过程如下图所示。

(4)第三轮分析优化
不过,上述设计还是不够安全,因为未认证系统仍然可以在Token 时间窗口(如1分钟)失效之前,通过截获请求和重放请求调用我们的接口!
攻与防之间博弈,本来就没有绝对的安全,我们能做的就是尽量提高攻击的成本。上面的方案虽然还有漏洞,但是实现简单,而且不会过多影响接口本身的性能(如响应时间)。权衡安全性、开发成本和对系统性能的影响,我们认为这个折中方案是比较合理的。
实际上,还有一个细节需要考虑,那就是如何在微服务端存储每个授权调用方的 AppID和密码。当然,这个问题不难解决。我们容易想到的解决方案是将它们存储到数据库中,如MySQL。不过,对于鉴权这样的非业务功能开发,尽量不要与具体的第三方系统过度耦合对于 AppID 和密码的存储,理想的情况是灵活地支持各种不同的存储方式,如 ZooKeeper、本地配置文件、自研配置中心、MySQL和Redis 等。我们不需要对每种存储方式都进行代码实现,但起码留有扩展点,保证系统有足够的灵活性和扩展性,能够在切换存储方式时,尽可能减少代码的改动。
4.如何进行面向对象设计
面向对象分析的产出是详细的需求描述,面向对象设计的产出是类。在面向对象设计环节,我们将需求描述转化为具体的类的设计,我们对面向对象设计环节进行拆解,分为以下4个步骤:
1)划分职责进而识别有哪些类:
2)定义类及其属性和方法;
3)定义类之间的交互关系;
4)将类组装起来并提供执行入口。
接下来,我们按照上述4个细节步骤,介绍如何对鉴权功能进行面向对象设计。
(1) 划分职责进而识别有哪些类
面向对象有关的图书中经常讲到:类是对现实世界中十五的建模。但是,并不是每个需求都能映射到现实世界,也并不是每个类都与现实世界中的事物一一对应。对于一些抽象的概念,我们是无法通过映射现实世界中的事物的方式来定义类的。大多数介绍面向对象的图书都会提到一种识别类的方法,那就是先把需求描述中的名词罗列出来,作为可能的候选类,再进行筛选。对于初学者,这种方法简单、明确,可以直接照着做。
不过,作者更喜欢先根据需求描述,把其中涉及的功能点一个个罗列出来,再去检查哪些功能点的职责相近、操作同样的属性,判断可否归为同一个类。针对鉴权功能开发案例,我们来看一下具体如何来做。
上面章节已经给出了详细的需求描述,我们重新梳理并罗列。
1) 调用方进行接口请求时,将URL、AppD、密码和时间戳进行拼接,通过加密算法生成Token,并将 Token、AppID 和时间戳拼接在 URL中,一并发送到微服务端。
2) 微服务端接收调用方的接口请求后,从请求中拆解出Token、AppID 和时间戳。
3) 微服务端先检查传递过来的时间戳与当前时间戳是否在Token 有效时间窗口内,如果已经超过有效时间,那么接口调用鉴权失败,拒绝接口调用请求。
4) 如果 Token 验证没有过期失效,那么微服务端再从自己的存储中取出 AppID 对应的密码,通过同样的 Token生成算法,生成另一个Token,并与调用方传递过来的 Token 进行匹配,如果二者一致,则鉴权成功,允许接口调用; 否则,拒绝接口调用。
接下来,我们将上面的需求描述拆解成“单一职责”(3.1节将会介绍)的功能点,也就是说,拆解出来的每个功能点的职责要尽可能小。下面是将上述需求描述拆解后的功能点列表。
1)把 URL、AppID、密码和时间戳拼接为一个字符串。
2)通过加密算法对字符串加密生成 Token。
3)将 Token、AppID 和时间戳拼接到 URL 中,形成新的 URL。
4)解析 URL,得到 Token、AppID 和时间戳。
5)从存储中取出 AppID 和对应的密码。
6)根据时间戳判断 Token 是否过期失效。
7)验证两个 Token 是否匹配。
从上述功能点列表中,我们发现,1)、2)、6)和7)都与 Token 有关,即负责 Token的生成和验证;3)和4)是在处理URL,即负责URL的拼接和解析;5)是操作 AppID 和密码,负责从存储中读取AppID和密码。因此,我们可以大致得到3个核心类:AuthToken、Url 和CredentialStorage。其中,AuthToken类负责实现1)、2)、6)和7)这4个功能点; Url 类负责实现3)和 4)两个功能点;CredentialStorage 类负责实现5)这个功能点。
当然,这只是类的初步划分,其他一些非核心的类,我们可能暂时没办法罗列全面,但也没有关系,面向对象分析、面向对象设计和面向对象编程本来就是一个循环选代与不断优化的过程。根据需求,我们先给出一个“粗糙”的设计方案,再在这个基础上进行迭代优化,这样的话,思路会更加清晰。
不过,这里需要强调一点,接口调用鉴权功能开发的需求比较简单,因此,对应的面向对象设计并不复杂,识别出来的类也并不多。但是,如果我们面对的是大型软件的开发,需求会更加复杂,涉及的功能点和对应的类会更多。如果我们像上面那样根据需求逐个罗列功能点,那么会得到一个很长的列表,会显得凌乱和没有规律。针对复杂的需求开发,首先通行模块划分,将需求简单地划分成若干小的、独立的功能模块,然后再在模块内部,运用上面介绍的方法进行面向对象设计,而模块的划分和识别与类的划分和识别可以使用相同的处理方法。
(2) 定义类及其属性和方法
在上文中,通过分析需求描述,识别出了3个核心类:AuthToken、Url和 CredentialStorage 现在,我们看一下每个类中有哪些属性和方法。我们继续对功能点列表进行挖据。
AuthToken 类相关的功能点有以下4个:
1)把 URL、AppID、密码和时间戳拼接为一个字符串;
2)通过加密算法对字符串加密生成 Token;
3)根据时间戳判断 Token 是否过期失效;
4)验证两个 Token 是否匹配。
对于方法的识别,很多面向对象相关的图书中会这样介绍:先将识别出的需求描述中的动词作为候选的方法,再进一步过滤和筛选。类比方法的识别,我们可以把功能点中涉及的名称为候选属性,然后进行过滤和筛选。
通过上述思路,根据功能点描述,我们可以识别出AuhToken类的属性和方法(函数)如下图所示。

通过上图,我们发现了下列3个细节。
细节一: 并不是所有的名词都被定义为类的属性,如 URL、AppDD、密码和时间戳,我们把它们作为方法的参数。
细节二: 我们循要挖据一些没有出现在功能点描述中的用属性,如createTime和expiredTimeInterval, 它们用在isExpired()函数中,用来判定Token是否过期失效。
细节三: AuthToken 类中添加了一个功能点描述里没有提到的方法getToken()。
通过细节一,我们可以知道,从业务模型上来说,不属于这个类的属性和方法不应该放到这个类中。对于URL、AppID, 从业务模型上来说,不应该属于AuthToken类,因此不应该放到这个类中。
通过细节二和细节三,我们可以知道,类具有哪些属性和方法不能仅依靠当下的需求进行开发,还要分析这个类在业务模型上应该具有哪些属性和方法。这样既可以保证类定义的完整性,又能为未来的需求开发做好了准备。
Url类相关的功能点有两个:
1)将 Token、AppID 和时间戳拼接到 URL 中,形成新的 URL:
2)解析 URL,得到 Token、AppID 和时间戳。
虽然在需求描述中,我们都是以 URL 代指接口请求,但是,接口请求并不一定是URL 的形式,还有可能是 RPC等其他形式。为了让这个类通用,命名更加贴切,我们接下来把它命名为ApiRequest。下图是根据功能点描述设计的 ApiRequest 类。

CredentialStorage类的功能点只有一个:从存储中取出AppID和对应的密码。因此CredentialStorage类非常简单,类图如下图所示。为了做到封装具体的存储方式,我们将CredentialStorage 设计成接口,基于接口而非具体的实现编程。

(3)定义类之间的交互关系
类之间存在哪些交互关系呢?UML(统一建模语言)中定义了类之间的6种关系:泛化、实现、聚合、组合、关联和依赖。类之间的关系较多,而且有些比较相似,如聚合和组合,接下来,我们逐一讲解。
1)泛化(generalizaion)可以被简单地理解为继承关系。Java 代码示例如下所示:
public class A{...}
public class B extends A{...}2)实现(realization)一般是指接口和实现类之间的关系。Java 代码示例如下所示:
public interface A{...)
public class B implements A{...}3)聚合(aggregation)是一种包含关系。A类的对象包含B类的对象,B 类的对象的命周期可以不依赖A类的对象的生命周期,也就是说,可以单独销毁A类的对象而不影响B类的对象,如课程与学生之间的关系。Java代码示例如下所示。
public class A{
private B b;//外部传入
public A(B b){
this.b = b;
}
}4)组合(composition)也是一种包含关系。A类的对象包含B类的对象,B类的对象的生命周期依赖A类的对象的生命周期,B类的对象不可单独存在,如鸟与膀之间的关系Java 代码示例如下所示。
public class A{
private B b;//内部创建
public A(){
this.b=new B();
}
}5)关联(associaon)是一种非常弱的关系,包含聚合和组合两种关系。具体到代码层面,如果B类的对象是A类的成员变量,那么B类和A类之间就是关联关系。Java代码示例如所示。
public class A{
private B b;
public A(B b){
this.b = b;
}
}或者
public class A{
Private B b;
public A(){
this.b = new B();
}
}6) 依赖(dependency)是一种比关联关系更弱的关系,包含关联关系。无论是B类的对象为A类的对象的成员变量,还是A类的方法将B类的对象作为参数,或者返回值、局部变量,只要B类的对象和A类的对象有任何使用关系,我们都称它们有依赖关系。Java 代码示例如下所示。
public class A{
private B b;
public A(B b){
this.b = b;
}
}或者
public class a {
private B b;
public A(){
this.b=new B();
}
}抑或
public class A{
public void func(B b){...}
}看完了上述 UML中定义的类的6种关系,读者有何感受?作者个人认为,这6种关系分类有点太细,增加了读者的学习成本,对指导编程没有太大意义。因此,作者从更加贴近编程的角度出发,对类之间的关系做了调整,只保留了其中的4种关系:泛化、实现、组合和依赖。
其中,泛化、实现和依赖的定义不变,组合关系替代UML中定义的组合、聚合和关联3种关系,相当于将关联关系重新命名为组合关系,并且不再区分UML中定义的组合和聚合两种关系。之所以这样重新命名,是为了与我们前面提到的“多用组合,少用继承”设计原则中的“组合”统一含义。只要B类的对象是A类的对象的成员变量,我们就称A类与B类是组合关系。
相关理论介绍完毕,我们看一下上面定义的类之间存在哪些关系。因为目前只有3个核心类,所以只用到了实现关系,即CredentialStorage类和 MysqICredentialStorage 类之间的关系。接下来,在介绍组装类时,我们还会用到依赖关系、组合关系。注意,泛化关系在本案例中并没有用到。
在类以及类之间的交互关系设计好之后,接下来,我们将所有的类组装在一起,并提供个执行入口。这个入口可能是一个main()函数,也可能是一组提供给外部调用的API。通过这个入口,我们能够触发代码的执行。
(4)将类组装起来并提供执行入口
因为接口鉴权并不是一个独立运行的系统,而是一个集成在系统上运行的组件,所以,我们封装所有的实现细节,设计了一个顶层的接口类(ApiAuthenticator类),并暴露一组提供给外部调用者使用的API,作为触发执行鉴权逻辑的入口。ApiAuthenticator类的详细设计如下图所示。
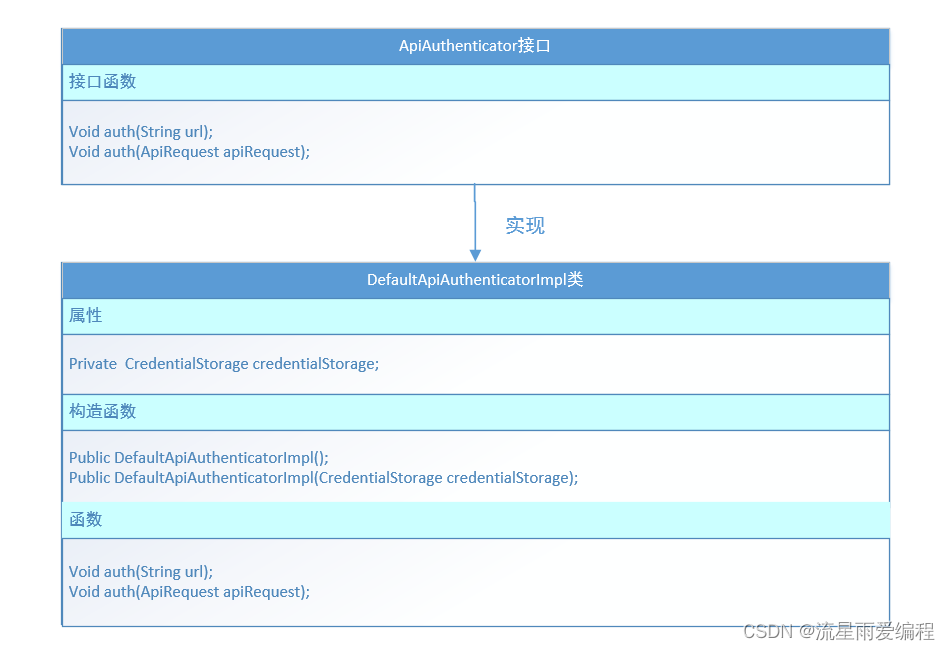
5.如何进行面向对象编程
在面向对象设计完成之后,我们已经定义了类、属性、方法和类之间的交互,并且将有的类组装起来,提供了统一的执行入口。接下来,面向对象编程的工作就是将这些设计思路“翻译”成代码。有了前面的类图,这部分工作就简单了。因此,这里只给出复杂的ApiAuthenticator 类的代码实现。
public interface ApiAuthenticator{
void auth(String ur);
void auth(ApiRequest apiRequest);
}
public calss DefaultApiAuthenticatorImpl implement ApiAuthenticator{
private CredentialStorage credentialStorage;
public DefaultApiAuthenticator(){
this.credentialStorage = new MysqlcredentialStorage();
}
publis DefaultApiAuthenticator(CredentialStorage credentialStorage)
this.credentialStorage = credentialStorage;
}
@Override
public void auth(String url){
ApiRequest apiRequest = ApiRequest.buildFromUrl(url);
auth(apiRequest);
}
@Override
public void auth(ApiRequest apiRequest){
String appId=apiRequest.getAppId();
String token= apiReqest.getToken();
long timestamp=apiRequest.getTimestamp();
String originalUrl=apiRequest.getOriginalUrl();
AuthToken clientAuthToken = new AuthToken(token, timestamp);
if(clientAuthToken.isExpired()){
throw new RuntimeException("Token is expired.");
}
String password = credentialStorage.getPasswordByAppId(appId);
AuthToken serverAuthToken = AuthToken.generate(originalUrl,appId, password, timestamp);
if(!serverAuthToken.match(clientAuthToken)){
throw new RuntimeException("Token verifcation failed.");
}
}
}在前面的讲解中,对于面向对象的分析、设计和编程,每个环节的界限划分清楚。而且,面向对象设计和面向对象编程基本上是按照功能点的描述逐句进行的。这样做的好处是,先做什么和后做什么非常清晰与明确,有章可循,即便是没有太多设计经验的初级工程师,也可以参照这个流程按部就班地进行面向对象的分析、设计和编程。
不过,在平时的工作中,大部分程序员往往都是在脑子里或草稿纸上完成面向对象的分析和设计,然后立即开始写代码,一边写,一边优化和重构,并不会严格地按照固定的流程来执行。在写代码之前,即便我们花很多时间进行面向对象的分析和设计,绘制了相当好的类图、UML图,也不可能把每个细节、交互都想清楚。在落实到代码时,我们还是需要反复迭代、重构,甚至推倒重写。毕竟,软件开发本来就是一个不断迭代、修补,以及遇到问题并解决问题的过程,是一个不断重构的过程。我们无法严格地按照顺序执行各个步骤。
6.总结
软件设计的自由度很大,这也是软件设计的复杂之处。不同的人对类的划分、定义,以及类之间交互的设计,可能都不一样。对于鉴权组件的设计,除本节给出的设计思路以外,读者有没有其他设计思路呢?















 1852
1852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









