









一、Map Shuffle主要做了哪些事?哪些可以设置及如何设置?
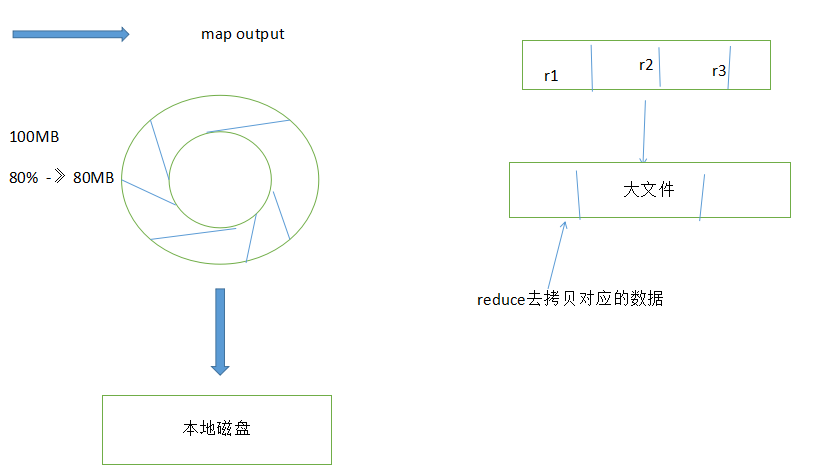
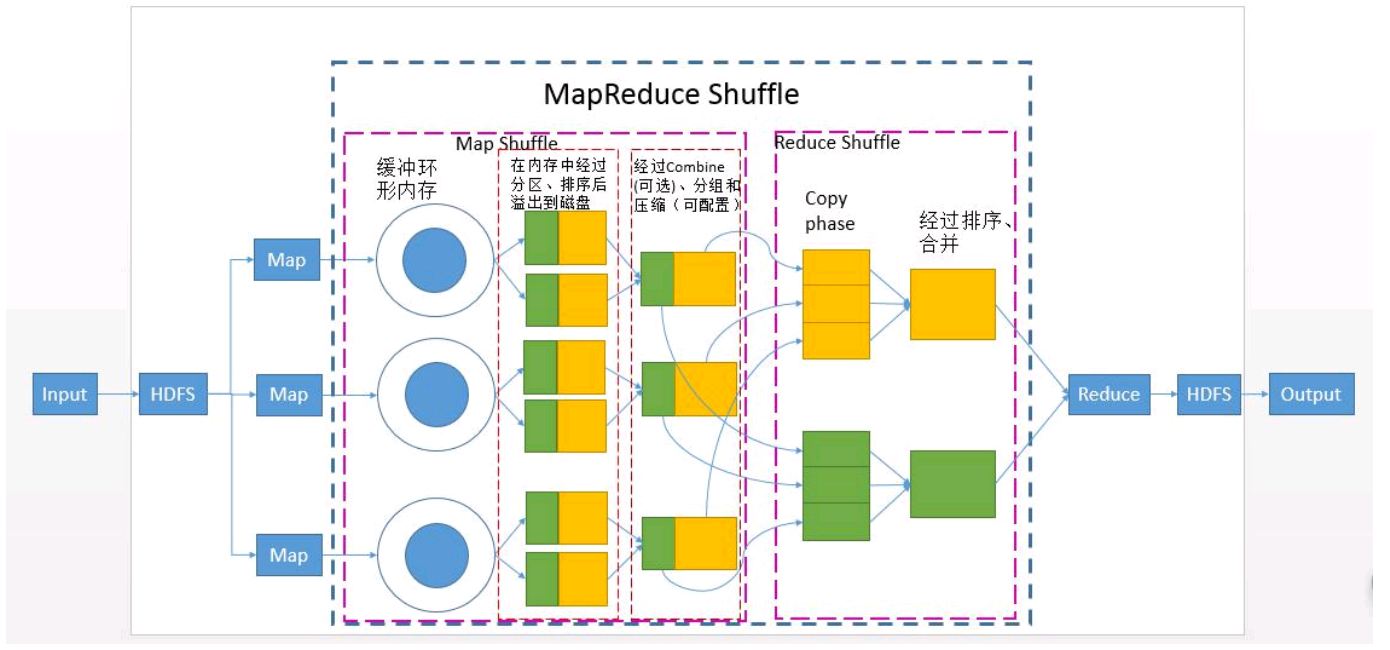
1. 分区partitioner ->>可以自定义规则
线程首先根据最终要传的reducer把数据划分成相应的分区(partition)。
-》决定了map输出的数据,被哪个reduce任务进行处理
-》方便与reduce拷贝数据,直接拷贝划分好的区域数据就可以了
2. 排序sort->>可以自定义规则
在每个分区中,后台线程按键进行内排序,如果有一个combiner,它就在排序后的输出上运行。
-》对于每个分区中的数据进行排序,内存排序速度较快
3. 溢写spill-》溢写本地磁盘-》溢写文件
每个map任务都有一个环形内存缓冲区用于存储任务输出。默认情况下,缓冲区的大小为100MB,此值可以通过改变io.sort.mb属性来调整。一旦缓冲内容达到阈值(io.sort.spill.percent,默认为80%),一个后台线程便开始把内容溢出(spill)到磁盘。
4. 数据量很大的情况下-》小文件很多-》合并
5. 合并merge->>可以自定义规则
-》将各个分区的合并在一起
-》合并以后每一个分区里的数据要进行排序,默认按照key排序
-》最后形成一个文件
二、Reduce Shuffle主要做了哪些事?哪些可以设置及如何设置?
- reduce会去拷贝map端的数据,去本地磁盘拉取各自要处理的数据
- 一开始也是放在内存中,内存也是有大小
- 溢写spill-》溢写本地磁盘-》
一旦内存缓冲区达到阈值大小(由mapred.job.shuffle.merge.percent决定)或者达到map输出阈值(由mapred.inmen.merge.threshold控制),则合并后溢出写到磁盘中 - 合并
如果指定combiner,则在合并期间运行它以降低写入磁盘的数据量。 - 排序
- 分组:将相同key的value放在一起
- 最后形成一个文件(合并、排序、分组)
三、在Shuffle阶段中的Comparator如何理解作用?
不管是排序还是分组,都需要自定义排序器comparable
Comparator类继承WritableComparator

而WritableComparator完成接口RawComparator
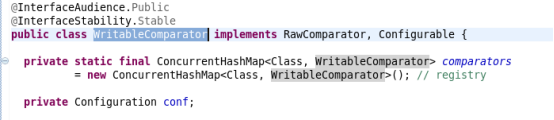
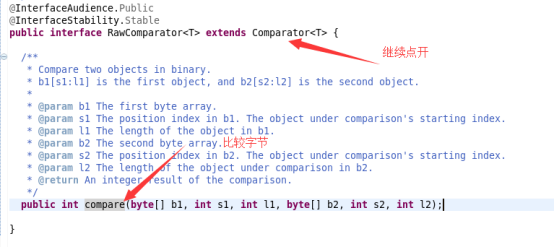
在RawComparator中

四、MapReduce执行过程中中间数据的压缩配置
Ctrl + Shift + T: 打开Open Type查找类文件:输入DefaultCodec
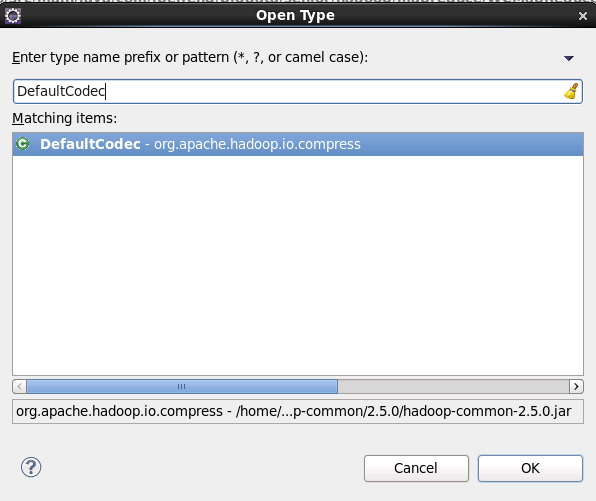
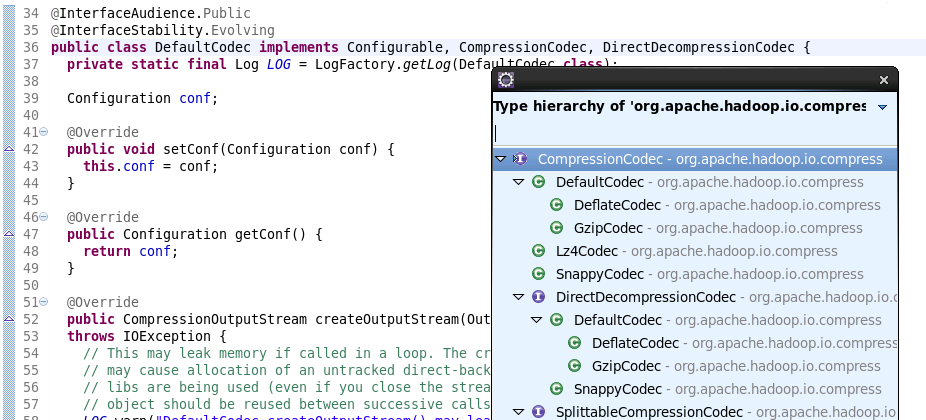
在CompressionCodec上按 Ctrl+T 快捷键查询所支持的类型
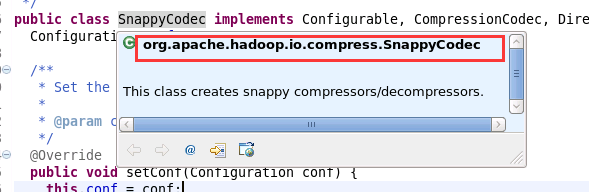
选中后,鼠标放到SnappyCodec上,看压缩类型所在的包
Configuration configuration = new Configuration();
//开启压缩
configuration.set("mapreduce.map.output.compress", "true");
//设定压缩的类型
configuration.set("mapreduce.map.output.compress.codec", "org.apache.hadoop.io.compress.SnappyCodec");














 4530
4530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









