









一、克隆虚拟机
- 注意点
- 必须先关机(关闭所有的服务进程)
- 选择完整的克隆
- 修改IP、主机名、映射
- 修改主机名
sudo vi /etc/sysconfig/network - 修改IP
- 把eth1改为eth0
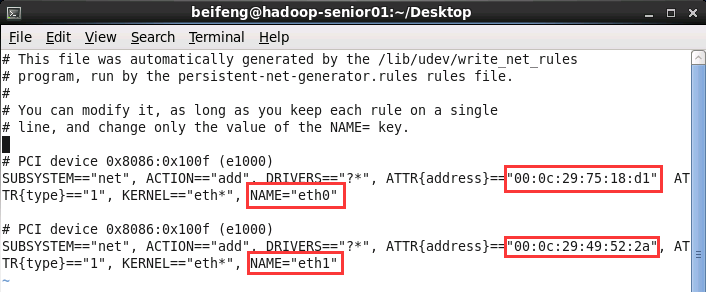
sudo vi /etc/udev/rules.d/70-persistent-net.rules
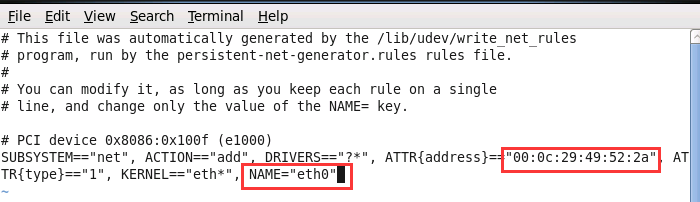
- 将eth0的那一条删掉,把mac地址拷贝出来00:0c:29:49:52:2a,将eth1修改为eth0
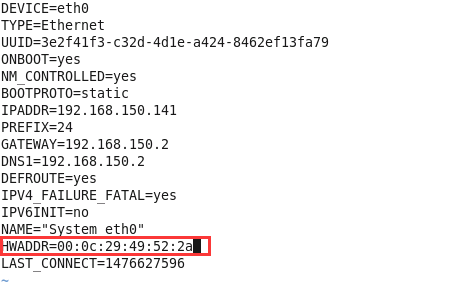
sudo vi /etc/sysconfig/network-scripts/ifcfg-eth0- 替换其中的mac地址
- 重启:
sudo service network restart
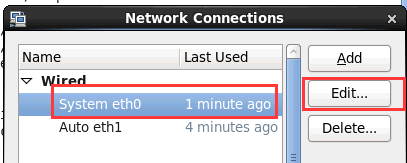
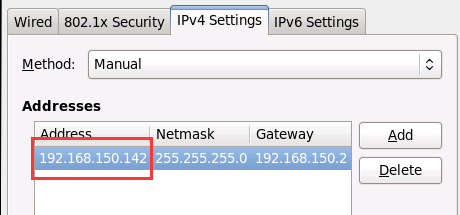
- 1修改IP
- NetWork配置
- 将IP从192.168.150.141 修改为182.168.150.142
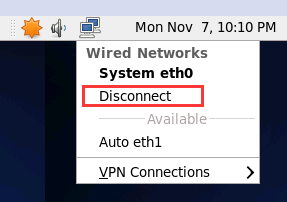
- 修改完成之后重新断开重新连接一下
- NetWork配置
- 把eth1改为eth0
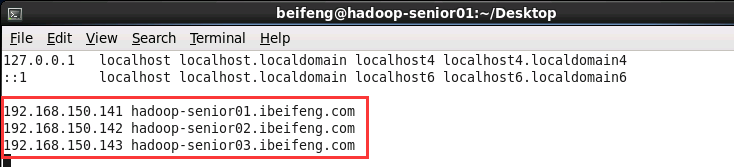
- 修改映射
sudo vi /etc/hosts
- 同理配置第三台,第一台只需要修改一下映射
- 修改Windows主机映射
- C:\Windows\System32\drivers\etc\hosts
- C:\Windows\System32\drivers\etc\hosts

二、集群部署和节点部署
机器配置
Hadoop-senior01 Hadoop-senior02 Hadoop-senior03 内存:4G 内存:4G 内存:4G CPU:4核 CPU:4核 CPU:4核 硬盘容量:1TB 硬盘容量:1TB 硬盘容量:1TB 集群服务组件的规划
Hadoop-senior01 Hadoop-senior02 Hadoop-senior03 NameNode ResourceManager SecondaryNameNode DataNode(磁盘) DataNode DataNode NodeManager(资源) NodeManager NodeManager MRhistoryServer
NameNode,ResourceManager,SecondaryNameNode:这三个是主节点,消耗内存不建议放在同一台机器上
三、Hadoop 2.x完全分布式环境搭建
- 创建一个用于存放分布式环境的目录
- 之前的伪分布放在 /opt/modules/目录下
- 在/opt目录下创建app文件夹,将完全分布式的环境放在app目录下
- 解压Hadoop
tar -zxf /opt/software/hadoop-2.5.0.tar.gz -C /opt/app/
- 删除hadoop-2.5.0/share/doc目录以减少分发节点拷贝的过程时间:进入share目录:
rm -rf ./doc/
- 指定JAVA——HOME的安装路径(3个文件都需要-env.sh)
- 使用Notepad++进入/opt/app/hadoop-2.5.0/etc/hadoop目录下
- (hadoop-env.sh,mapred-env.sh,yarn-env.sh):
export JAVA_HOME=/opt/modules/jdk1.7.0_67
修改core-site.xml自定义文件
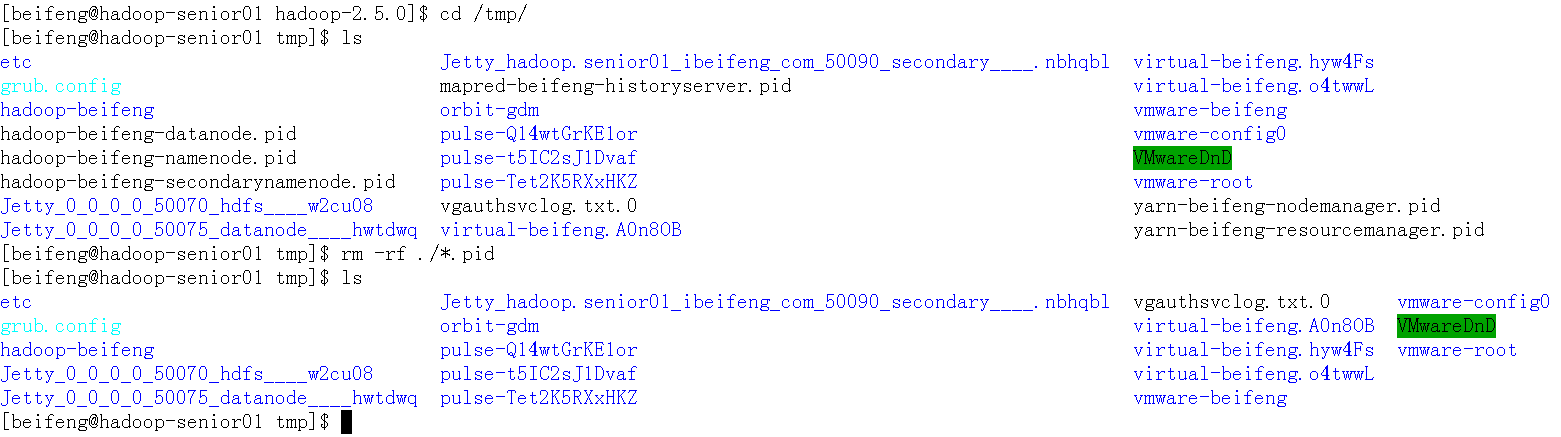
- 进入/tmp/目录下把所有带有pid的文件删掉
指定 namenode 主节点所在的位置以及交互端口号
<property> <name>fs.defaultFS</name> <value>hdfs://hadoop-senior01.ibeifeng.com:8020</value> </property>重新创建tmp目录的路径:mkdir -p data/tmp
<property> <name>hadoop.tmp.dir</name> <value>/opt/app/hadoop-2.5.0/data/tmp</value> </property>- 如果有logs目录就删除掉:rm -rf logs
- 进入/tmp/目录下把所有带有pid的文件删掉
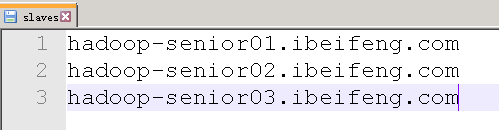
修改slaves文件,指定节点
hadoop-senior01.ibeifeng.com
hadoop-senior02.ibeifeng.com
hadoop-senior03.ibeifeng.com
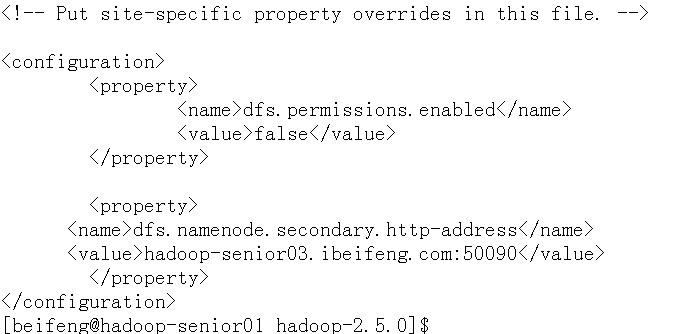
修改hdfs-site.xml文件,修改SNN(SecondaryNameNode)位置
<property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop-senior03.ibeifeng.com:50090</value> </property>修改yarn-site.xml
//设置reduce 的获取数据的方式 <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> //指定 ResourceManager 的位置 <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop-senior02.ibeifeng.com</value> </property> //开启日志聚集功能 <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> //设置日志在 HDFS 上保留的时间期限 <property> <name>yarn.log-aggregation.retain-seconds</name> <value>106800</value> </property>配置mapred-site.xml, 将 mapred-site.xml.template 改名为 mapred-site.xml
//指定 MapReduce 运行在 YARN 上 <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> //配置 JobhistoryServer 历史服务器 <property> <name>mapreduce.jobhistory.address</name> <value>hadoop-senior01.ibeifeng.com:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop-senior01.ibeifeng.com:19888</value> </property>设置不启用 HDFS 文件系统的权限检查
配置hdfs-site.xml
<property> <name>dfs.permissions.enabled</name> <value>false</value> </property>配置core-site.xml
<property> <name>hadoop.http.staticuser.user</name> <value>beifeng</value> </property>
将配置文件分发到各个节点上去
- 在其余两台上先创建目录
sudo mkdir app - 设置权限
sudo chown -R beifeng:beifeng app/
- 发送:
scp -r hadoop-2.5.0/ hadoop-senior03.ibeifeng.com:/opt/app/
- 在其余两台上先创建目录
- 格式化NameNode
bin/hdfs namenode -format- 格式化之后生成初始化的fsimage和edits文件
启动守护进程
hadoop-senior01
sbin/hadoop-daemon.sh start namenode sbin/hadoop-daemon.sh start datanode sbin/yarn-daemon.sh start nodemanager sbin/mr-jobhistory-daemon.sh start historyserverhadoop-senior02
sbin/hadoop-daemon.sh start datanode sbin/yarn-daemon.sh start resourcemanager sbin/yarn-daemon.sh start nodemanagerhadoop-senior03
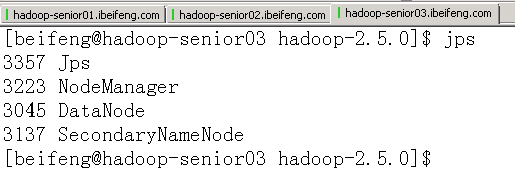
sbin/hadoop-daemon.sh start datanode sbin/hadoop-daemon.sh start secondarynamenode sbin/yarn-daemon.sh start nodemanager
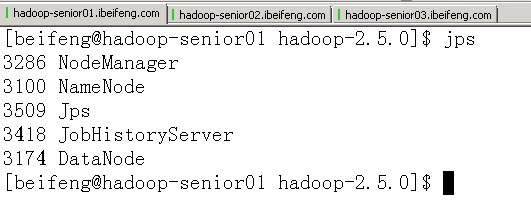
页面查看进程
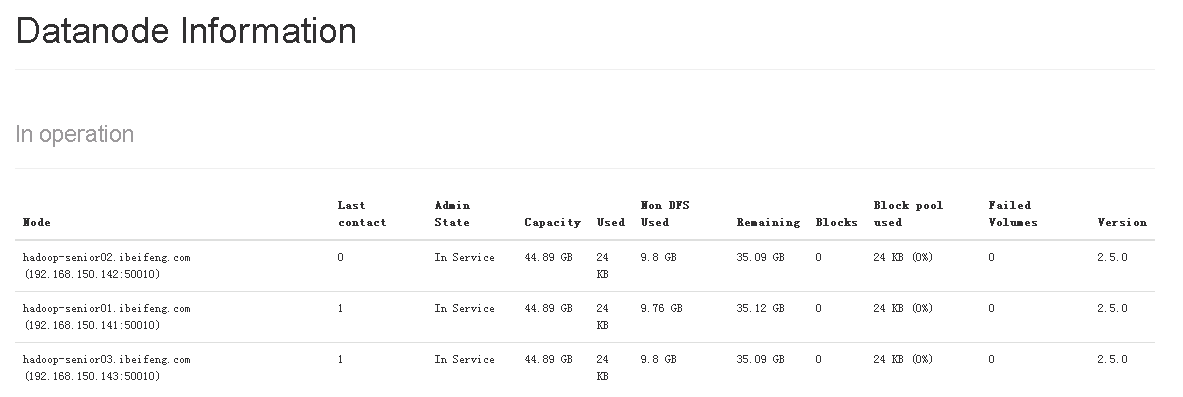
- 查看节点DataNode:http://hadoop-senior01.ibeifeng.com:50070/
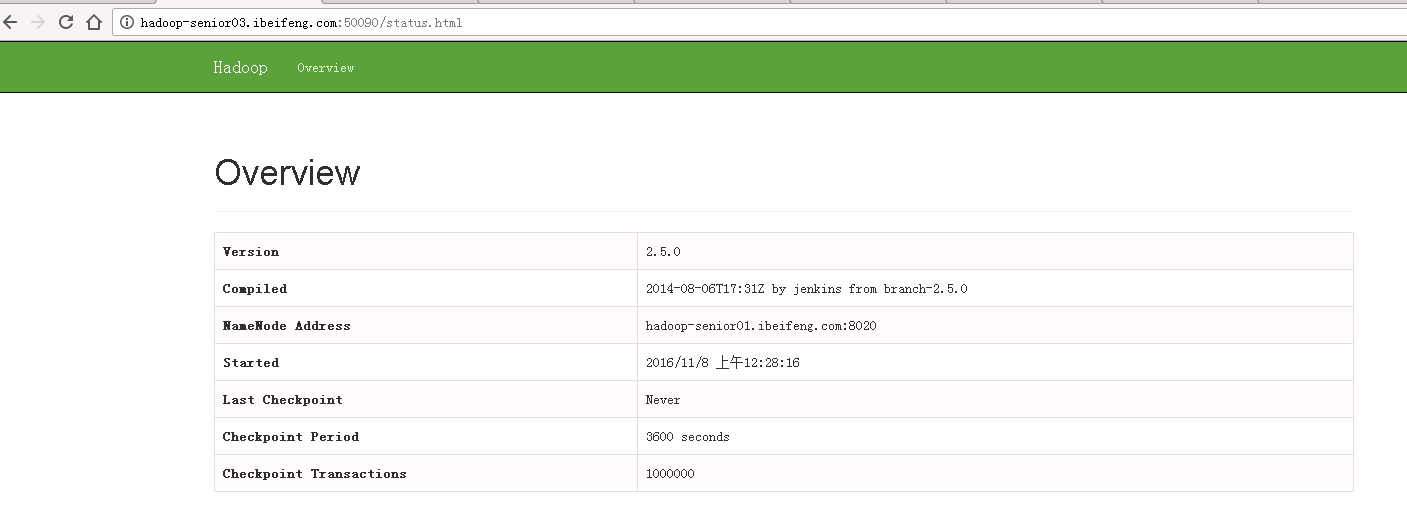
- SecondaryNameNode:http://hadoop-senior03.ibeifeng.com:50090/
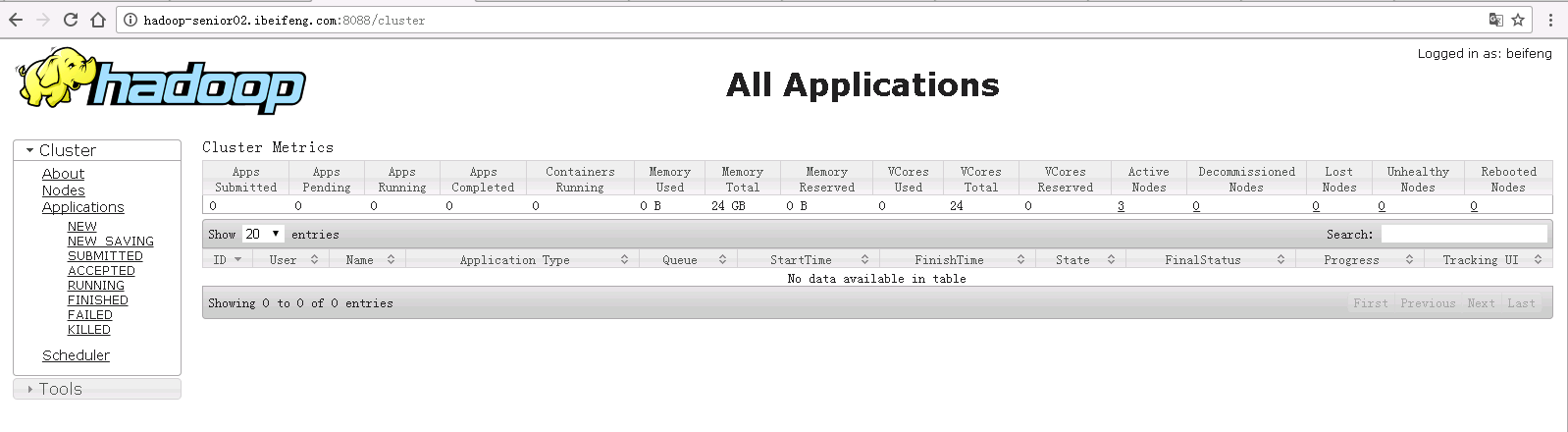
- 查看Yarn:http://hadoop-senior02.ibeifeng.com:8088/
- 三台服务器对应的进程
- 查看节点DataNode:http://hadoop-senior01.ibeifeng.com:50070/
- 测试集群
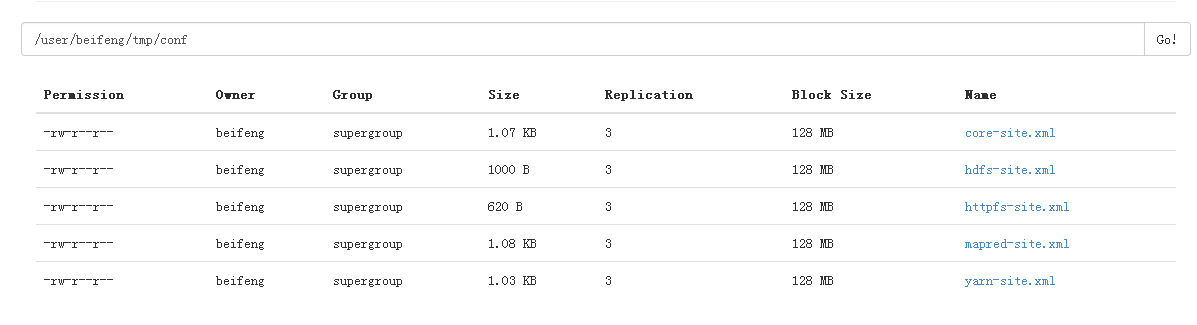
- 创建目录:
bin/hdfs dfs -mkdir -p tmp/conf
- 上传:
bin/hdfs dfs -put etc/hadoop/*-site.xml tmp/conf
- 查看:
bin/hdfs dfs -text /user/beifeng/tmp/conf/hdfs-site.xml
- 在YARN上运行MR程序
- 创建输入路径:
bin/hdfs dfs -mkdir tmp/input - 上传WordCount测试数据:
bin/hdfs dfs -put /opt/datas/wc.input /user/beifeng/tmp/input bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/beifeng/tmp/input /user/beifeng/tmp/output
- 创建输入路径:
- 创建目录:




















 1321
1321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









