









二次排序
-》第一点组合key,key是一个组合的字段(自定义数据类型) -》继承WrtiableComparable
-》第二点保证原来的分区不变,需要自定义分区规则 -》继承partitioner
-》第三点保证原来的分组不变,需要自定义分组规则 -》继承RawComparator
创建文件路径
bin/hdfs dfs -mkdir -p sort/input
创建测试数据
vi /opt/datas/sort.txt
- 上传测试数据
bin/hdfs dfs -put /opt/datas/sort.txt /user/beifeng/sort/input
- 一次排序之后的结果,没有二次排序
- 主要代码解释
- Mapper端
- Reducer端
- Driver端
- PairWritable
- FirstGroupingComparator 分组类
- FirstPartitioner分区类
- Mapper端
- 二次排序后的结果
中间运行时一直出不来正确的结果,最后发现是// reduce number 设置为了2 //job.setNumReduceTasks(2);
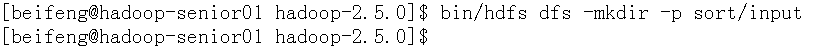











Join
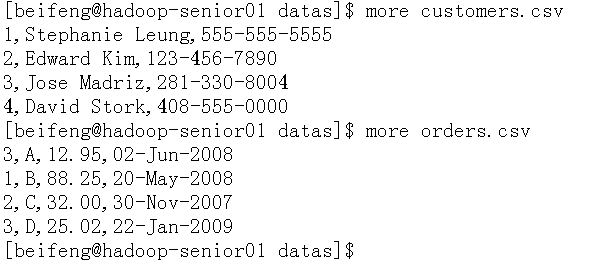
- 上传测试数据到/opt/datas
- 创建hdfs文件路径
bin/hdfs dfs -mkdir -p order/input - 上传文件到hdfs中
bin/hdfs dfs -put /opt/datas/orders.csv /opt/datas/customers.csv /user/beifeng/order/input
- 原始数据格式
- 运行程序
- 查看结果
- 代码解释
- Mapper端
- Reducer端
- Mapper端







具体代码
二次排序代码
package com.ibeifeng.bigdata.senior.hadoop.mapreduce.sort;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* @author beifeng
*
*/
public class SecondarySortMapReduce extends Configured implements Tool {
// step 1 : Mapper Class
public static class SortMapper extends
Mapper<LongWritable, Text, PairWritable, IntWritable> {
private PairWritable mapOutputKey = new PairWritable();
private IntWritable mapOutputValue = new IntWritable();
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// line value
String lineValue = value.toString();
// split
String[] strs = lineValue.split(",");
// invalidate
if (2 != strs.length) {
return;
}
// set map output key
mapOutputKey.set(strs[0], Integer.valueOf(strs[1]));
mapOutputValue.set(Integer.valueOf(strs[1]));
// output
context.write(mapOutputKey, mapOutputValue);
}
}
// step 2 : Reducer Class
public static class SortReducer extends
Reducer<PairWritable, IntWritable, Text, IntWritable> {
private Text outputKey = new Text();
@Override
protected void reduce(PairWritable key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
// iterator
for (IntWritable value : values) {
outputKey.set(key.getFirst());
context.write(outputKey, value);
}
}
}
/**
*
* @param args
* @return
* @throws Exception
* int run(String [] args) throws Exception;
*/
// step 3 : Driver
public int run(String[] args) throws Exception {
Configuration configuration = this.getConf();
Job job = Job.getInstance(configuration, this.getClass().getSimpleName());
job.setJarByClass(SecondarySortMapReduce.class);
// set job
// input
Path inpath = new Path(args[0]);
FileInputFormat.addInputPath(job, inpath);
// output
Path outpath = new Path(args[1]);
FileOutputFormat.setOutputPath(job, outpath);
// Mapper
job.setMapperClass(SortMapper.class);
job.setMapOutputKeyClass(PairWritable.class);
job.setMapOutputValueClass(IntWritable.class);
// partitioner
job.setPartitionerClass(FirstPartitioner.class);
// group
job.setGroupingComparatorClass(FirstGroupingComparator.class);
// Reducer
job.setReducerClass(SortReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// reduce number
// job.setNumReduceTasks(2);
// submit job
boolean isSuccess = job.waitForCompletion(true);
return isSuccess ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
args = new String[] {
"hdfs://hadoop-senior01.ibeifeng.com:8020/user/beifeng/sort/input",
"hdfs://hadoop-senior01.ibeifeng.com:8020/user/beifeng/sort/output2" };
// run job
int status = ToolRunner.run(configuration,
new SecondarySortMapReduce(), args);
// exit program
System.exit(status);
}
}
package com.ibeifeng.bigdata.senior.hadoop.mapreduce.sort;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class PairWritable implements WritableComparable<PairWritable> {
private String first;
private int second;
public PairWritable() {
}
public PairWritable(String first, int second) {
this.set(first, second);
}
public void set(String first, int second) {
this.setFirst(first);
this.setSecond(second);
}
public String getFirst() {
return first;
}
public void setFirst(String first) {
this.first = first;
}
public int getSecond() {
return second - Integer.MAX_VALUE;
}
public void setSecond(int second) {
this.second = second + Integer.MAX_VALUE;
}
public void write(DataOutput out) throws IOException {
out.writeUTF(first);
out.writeInt(second);
}
public void readFields(DataInput in) throws IOException {
this.first = in.readUTF();
this.second = in.readInt();
}
public int compareTo(PairWritable o) {
// compare first
int comp = this.first.compareTo(o.getFirst());
// equals
if (0 != comp) {
return comp;
}
// compare second
return Integer.valueOf(getSecond()).compareTo(
Integer.valueOf(o.getSecond()));
}
@Override
public String toString() {
return first + "\t" + second;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((first == null) ? 0 : first.hashCode());
result = prime * result + second;
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
PairWritable other = (PairWritable) obj;
if (first == null) {
if (other.first != null)
return false;
} else if (!first.equals(other.first))
return false;
if (second != other.second)
return false;
return true;
}
/** A Comparator optimized for LongWritable. */
public static class Comparator extends WritableComparator {
public Comparator() {
super(PairWritable.class);
}
@Override
public int compare(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
long thisValue = readLong(b1, s1);
long thatValue = readLong(b2, s2);
return (thisValue<thatValue ? -1 : (thisValue==thatValue ? 0 : 1));
}
}
}
package com.ibeifeng.bigdata.senior.hadoop.mapreduce.sort;
import org.apache.hadoop.io.RawComparator;
import org.apache.hadoop.io.WritableComparator;
public class FirstGroupingComparator implements RawComparator<PairWritable> {
public int compare(PairWritable o1, PairWritable o2) {
return o1.getFirst().compareTo(o2.getFirst());
}
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return WritableComparator.compareBytes(b1, 0, l1 - 4, b2, 0, l2 - 4);
}
}
package com.ibeifeng.bigdata.senior.hadoop.mapreduce.sort;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class FirstPartitioner extends Partitioner<PairWritable, IntWritable> {
@Override
public int getPartition(PairWritable key, IntWritable value,
int numPartitions) {
return (key.getFirst().hashCode() & Integer.MAX_VALUE) % numPartitions;
}
}
Mapreduce Join代码
package com.ibeifeng.bigdata.senior.hadoop.mapreduce.join;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* @author beifeng
*
*/
public class DataJoinMapReduce extends Configured implements Tool {
// step 1 : Mapper Class
public static class DataJoinMapper extends
Mapper<LongWritable, Text, LongWritable, DataJoinWritable> {
// map output key
private LongWritable mapOutputKey = new LongWritable();
// map output value
private DataJoinWritable mapOutputValue = new DataJoinWritable();
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
}
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// line value
String linevalue = value.toString();
// split
String[] vals = linevalue.split(",");
int length = vals.length;
if ((length != 3) && (length != 4)) {
return;
}
// get cid
long cid = Long.valueOf(vals[0]);
// get name
String name = vals[1];
// set customer
if (3 == length) {
String phone = vals[2];
mapOutputKey.set(cid);
mapOutputValue.set("customer", name + "," + phone);
}
// set order
if (4 == length) {
String price = vals[2];
String date = vals[3];
mapOutputKey.set(cid);
mapOutputValue.set("order", name + "," + price + "," + date);
}
//output
context.write(mapOutputKey, mapOutputValue);
}
@Override
protected void cleanup(Context context) throws IOException,
InterruptedException {
}
}
// step 2 : Reducer Class
public static class DataJoinReducer extends
Reducer<LongWritable, DataJoinWritable, NullWritable, Text> {
private Text outputValue = new Text();
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
}
@Override
protected void reduce(LongWritable key,
Iterable<DataJoinWritable> values, Context context)
throws IOException, InterruptedException {
String customerInfo = null;
List<String> orderList = new ArrayList<String>();
// iterator
for (DataJoinWritable value : values) {
if ("customer".equals(value.getTag())) {
customerInfo = value.getData();
} else if ("order".equals(value.getTag())) {
orderList.add(value.getData());
}
}
// output
for (String order : orderList) {
// set output value
outputValue.set(key.get() + "," + customerInfo + "," + order);
// output
context.write(NullWritable.get(), outputValue);
}
}
@Override
protected void cleanup(Context context) throws IOException,
InterruptedException {
}
}
/**
*
* @param args
* @return
* @throws Exception
* int run(String [] args) throws Exception;
*/
// step 3 : Driver
public int run(String[] args) throws Exception {
Configuration configuration = this.getConf();
Job job = Job.getInstance(configuration, this.getClass()
.getSimpleName());
job.setJarByClass(DataJoinMapReduce.class);
// set job
// input
Path inpath = new Path(args[0]);
FileInputFormat.addInputPath(job, inpath);
// output
Path outpath = new Path(args[1]);
FileOutputFormat.setOutputPath(job, outpath);
// Mapper
job.setMapperClass(DataJoinMapper.class);
// TODD
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(DataJoinWritable.class);
// Reducer
job.setReducerClass(DataJoinReducer.class);
// TODD
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
// submit job
boolean isSuccess = job.waitForCompletion(true);
return isSuccess ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
// 传递两个参数,设置路径
args = new String[] {
"hdfs://hadoop-senior01.ibeifeng.com:8020/user/beifeng/order/input",
"hdfs://hadoop-senior01.ibeifeng.com:8020/user/beifeng/order/output3" };
// run job
int status = ToolRunner.run(configuration, new DataJoinMapReduce(),
args);
// exit program
System.exit(status);
}
}
package com.ibeifeng.bigdata.senior.hadoop.mapreduce.join;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class DataJoinWritable implements Writable {
//makr,customer /oder
private String tag;
//info
private String data;
public DataJoinWritable(){
}
public DataJoinWritable(String tag, String data) {
this.set(tag, data);
}
public void set(String tag, String data){
this.setTag(tag);
this.setData(data);
}
public String getTag() {
return tag;
}
public void setTag(String tag) {
this.tag = tag;
}
public String getData() {
return data;
}
public void setData(String data) {
this.data = data;
}
public void write(DataOutput out) throws IOException {
out.writeUTF(this.getTag());
out.writeUTF(this.getData());
}
public void readFields(DataInput in) throws IOException {
this.setTag(in.readUTF());
this.setData(in.readUTF());
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((data == null) ? 0 : data.hashCode());
result = prime * result + ((tag == null) ? 0 : tag.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
DataJoinWritable other = (DataJoinWritable) obj;
if (data == null) {
if (other.data != null)
return false;
} else if (!data.equals(other.data))
return false;
if (tag == null) {
if (other.tag != null)
return false;
} else if (!tag.equals(other.tag))
return false;
return true;
}
@Override
public String toString() {
return tag + "," + data ;
}
}

















 1051
1051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









