







1.Storm简介
Storm是Twitter开源的一个分布式实时计算系统,用于数据的实时分析,持续计算,人不是RPC等等。
实时计算需要解决的一些问题:
(1)最显而易见的就是实时推荐系统,比如在淘宝等电商购物网站买东西时,我们会在网页旁边或者底端看到与自己所需商品相关的系列产品。这就是使用类似Storm实时计算去做的。Hadoop只是做离线的数据分析,无法做到实时分析计算。
(2)车流量的实时计算,可以利用Storm计算每一个路段的拥挤度等相关路况信息。
(3)股票系统也是一种实时计算的机制。
Storm实时计算系统具备的特性:
(1)低延迟:都说了是实时计算系统了,延迟是一定要低的。
(2)高性能:可以使用几台普通的服务器建立环境,节约成本。
(3)分布式:Stom非常适合于分布式场景,大数据的实时计算。
(4)可扩展:伴随着业务的发展,数据量和计算了可能会越来越大,所以希望该系统是可扩展的。
(5)容错:这是分布式系统中通用问题,一个节点挂了不能影响应用。Storm可以轻松的做到在节点挂了的时候实现任务转移,并且在节点重启的时候(重新投入生产环境时),自动平衡任务。
(6)可靠性:可靠的消息处理。Storm保证每个消息至少能得到一次完整处理。任务失败时,它会负责从消息源重试消息。
(7)快速:系统的设计保证消息能够得到快速的处理,使用ZeroMQ作为其底层消息队列。
(8)本地模式:Storm有一个“本地模式”,可以在处理过程中完全模拟Storm集群。这可以让我们快速进行开发和单元测试。
Storm架构图:
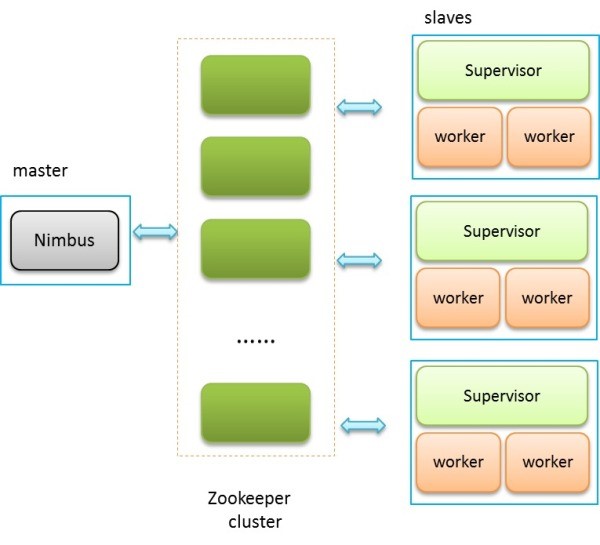
Nimbus:控制节点,用于提交、分配任务、集群监控等。
主节点通常运行一个后台程序——Nimbus,用于响应分布在集群中的节点,分配任务和监测故障。
Zookeeper:协调公有数据的存放(如心跳信息、集群状态、配置信息等),Nimbus将分配给Supervisor的任务写在Zookeeper中。
Zookeeper是完成Supervisor和Nimbus之间协调的服务。而应用程序实现实时的逻辑则被封装到Storm中的“topology”。topology则是一组由Spouts(数据源)和Bolts(数据操作)通过Stream Groupings进行连接的图。
Supervisor:负责接收Nimbus分配的任务,管理属于自己的worker进程。
工作节点同样运行一个后台程序——Supervisor,用于收听工作指派并基于要求运行工作进程。每个工作节点都是topology中一个子集的实现。而Nimbus和Supervisor之间的协调则通过Zookeeper系统或者集群。
worker:运行具体逻辑的进程。
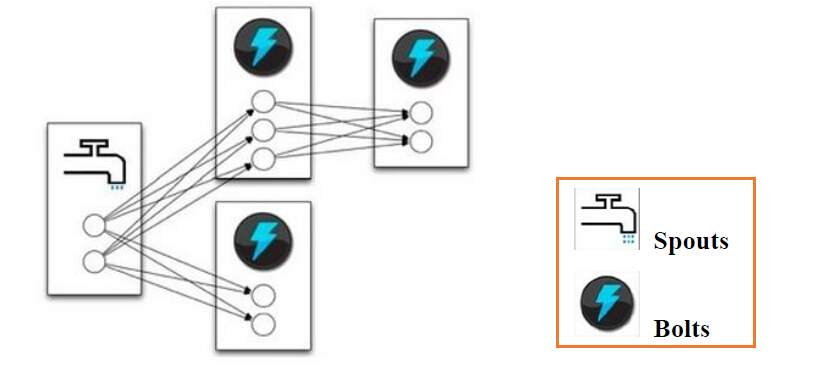
Storm Topology(拓扑)结构图
Storm中运行的一个实时应用程序,因为各个组件间的消息流动形成逻辑上的一个拓扑结构。一个topology是spouts和bolts组成的图,通过stream groupings将图中的spouts和bolts连接起来,如下图:
2.Storm环境搭建
(1)下载storm,我这里使用的是1.0.2的版本。
(2)使用tar -zxvf 命令解压。
(3)使用命令cd /usr/local/apache-storm-1.0.2/conf,这里是我放置storm的目录,大家需要进入自己的目录。使用vim storm.yaml命令,修改storm的配置文件,如下图所示:
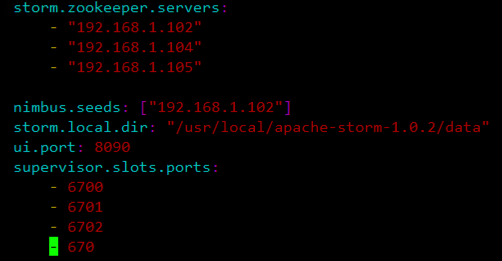
storm.zookeeper.servers:zookeeper服务器的地址,不需要配置端口号,默认使用2181。
nimbus.seeds:storm的nimbus主节点地址。
storm.local.dir:storm存放数据的目录。
ui.port:storm ui管控台的端口号。
supervisor.slots.ports:storm工作进程的端口。
(3)使用命令cd /usr/local/apache-storm-1.0.2进入storm的主目录,mkdir data创建storm存放数据的目录。
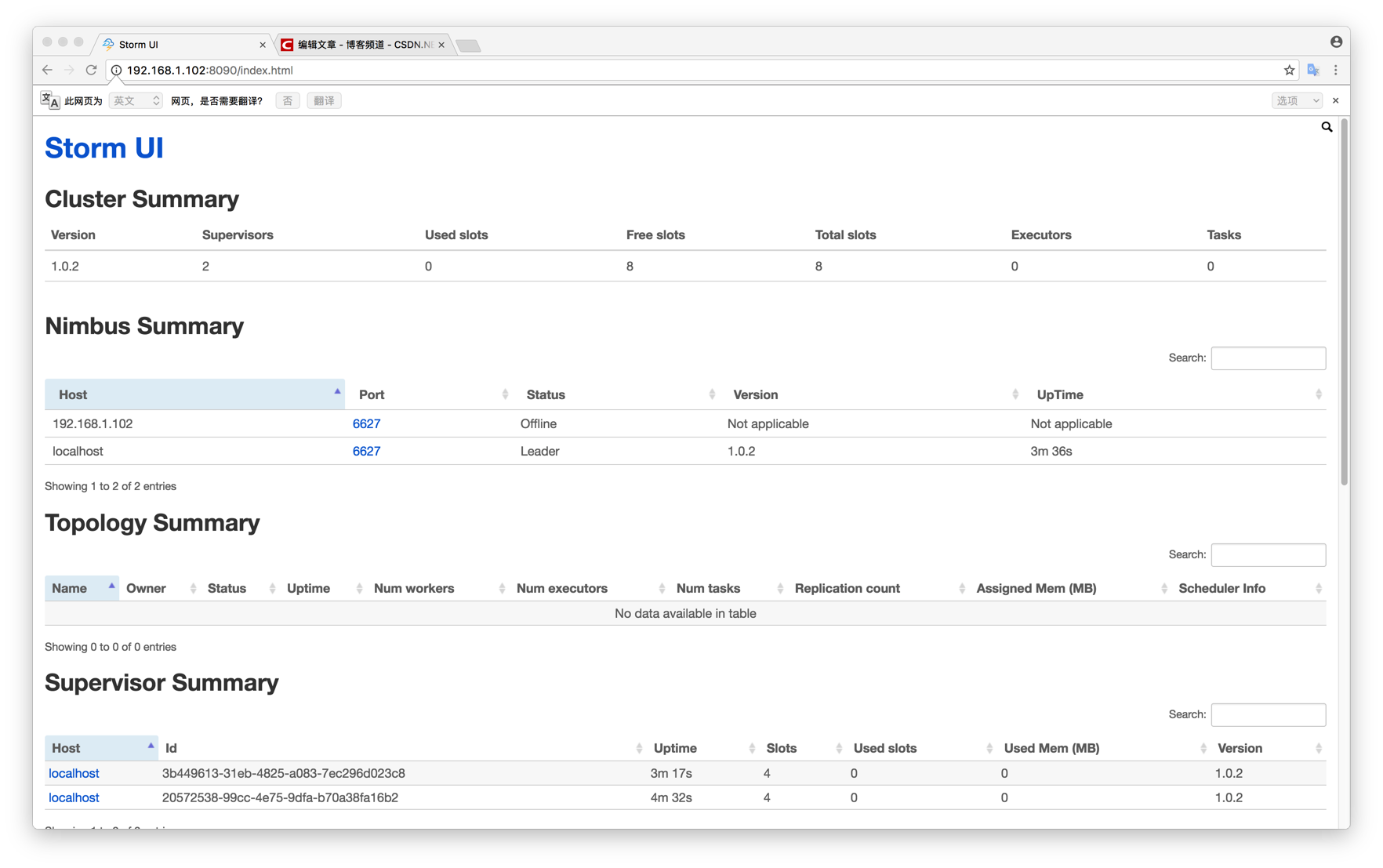
(4)配置完成后,使用命令storm nimbus &后台启动storm主节点,使用命令storm supervisor &后台启动storm从节点,在storm的主节点服务器也就是使用命令storm nimbus &启动storm的那台服务器上,使用命令storm ui &后台启动storm管控台,界面如下:















 6134
6134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









