






如今是大数据时代,大量数据需要处理,便越来越需要跟优秀的算法。
算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出。如果一个算法有缺陷,或不适合于某个问题,执行这个算法将不会解决这个问题。不同的算法可能用不同的时间,空间或效率来完成同样的任务。
一个算法的优劣可以用空间复杂度与时间复杂度来衡量。 时间复杂度主要衡量的是一个算法的运行速度,而空间复杂度主要衡量一个算法所需要的额外空间,在计算机发展的早期,计算机的存储容量很小。所以对空间复杂度很是在乎。
经过计算机行业的迅速发展,计算机的存储容量已经达到了很高的程度。所以我们如今已经不需要再特别关注一个算法的空间复杂度,反而常常牺牲一定存储空间,提高时间复杂度。即优秀的算法是指时间复杂度最低的条件下,空间复杂度越低,执行效率越高的算法。
排序算法是最经典的算法知识。因为其实现代码短,应用范围面广,更能锻练个人逻辑能力,熟悉并了解排序算法更有可能推陈出新。在1959年前,排序算法的时间复杂度均不低于,但当希尔排序出现后,紧跟着出现了好几种突破
的算法。
希尔排序是希尔(Donald Shell)于1959年提出的一种排序算法。希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为缩小增量排序,同时该算法是冲破
的第一批算法之一。它与插入排序的不同之处在于,它会优先比较距离较远的元素。希尔排序又叫缩小增量排序。
模拟需要排序的数组,做成顺序表
//数据类型抽象
#if 0
typedef struct data
{
int id;
char name[32];
}data_t;
#else
typedef int data_t;
#endif
#define MAXSIZE 10 //用于排序数组的最大个数
//顺序表抽象
typedef struct
{
data_t arr[MAXSIZE + 1]; //用于存储排序数组,arr[0]用作临时变量
int last; //用于指向最后一个元素的位置,即保存排序数组当前个数
} SqList;由于排序最常用到的操作是数组两元素交换,将它们写成函数
//交换函数
void swap(SqList *L, int i, int j)
{
data_t temp = L->arr[i];
L->arr[i] = L->arr[j];
L->arr[j] = temp;
}一、插入排序
一、概念及其介绍
插入排序(InsertionSort),一般也被称为直接插入排序。
对于少量元素的排序,它是一个有效的算法。插入排序是一种最简单的排序方法,它的基本思想是将一个记录插入到已经排好序的有序表中,从而一个新的、记录数增 1 的有序表
。在其实现过程使用双层循环,外层循环对除了第一个元素之外的所有元素,内层循环对当前元素前面有序表进行待插入位置查找,并进行移动。
二、适用说明
插入排序的平均时间复杂度也是 O(n^2),空间复杂度为常数阶 O(1),具体时间复杂度和数组的有序性也是有关联的。
插入排序中,当待排序数组是有序时,是最优的情况,只需当前数跟前一个数比较一下就可以了,这时一共需要比较 N-1 次,时间复杂度为 O(N)。最坏的情况是待排序数组是逆序的,此时需要比较次数最多,最坏的情况是 O(n^2)。
三、过程图示
假设前面 n-1(其中 n>=2)个数已经是排好顺序的,现将第 n 个数插到前面已经排好的序列中,然后找到合适自己的位置,使得插入第n个数的这个序列也是排好顺序的。
按照此法对所有元素进行插入,直到整个序列排为有序的过程,称为插入排序。
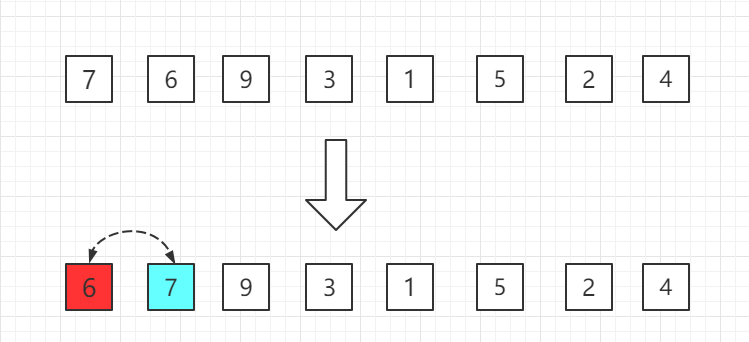
从小到大的插入排序整个过程如图示:
第一轮:从第二位置的 6 开始比较,比前面 7 小,交换位置。
第二轮:第三位置的 9 比前一位置的 7 大,无需交换位置。
第三轮:第四位置的 3 比前一位置的 9 小交换位置,依次往前比较。
第四轮:第五位置的 1 比前一位置的 9 小,交换位置,再依次往前比较。
......
就这样依次比较到最后一个元素。



C语言实现代码如下:
//插入排序
void InsertSort(SqList *L)
{
int i, j;
for (i = 2; i <= L->last; i++)
{
if (L->arr[i] < L->arr[i - 1])
{
L->arr[0] = L->arr[i];
for (j = i - 1; L->arr[j] > L->arr[0]; j--)
L->arr[j + 1] = L->arr[j];
L->arr[j + 1] = L->arr[0];
}
}
}
二、希尔排序
一、概念及其介绍
希尔排序(Shell Sort)是插入排序的一种,它是针对直接插入排序算法的改进。
希尔排序又称缩小增量排序,因 DL.Shell 于 1959 年提出而得名。
它通过比较相距一定间隔的元素来进行,各趟比较所用的距离随着算法的进行而减小,直到只比较相邻元素的最后一趟排序为止。
二、适用说明
希尔排序时间复杂度是 O(n^(1.3-2)),空间复杂度为常数阶 O(1)。希尔排序没有时间复杂度为 O(n(logn)) 的快速排序算法快 ,因此对中等大小规模表现良好,但对规模非常大的数据排序不是最优选择,总之比一般 O(n^2 ) 复杂度的算法快得多。
三、过程图示
希尔排序目的为了加快速度改进了插入排序,交换不相邻的元素对数组的局部进行排序,并最终用插入排序将局部有序的数组排序。
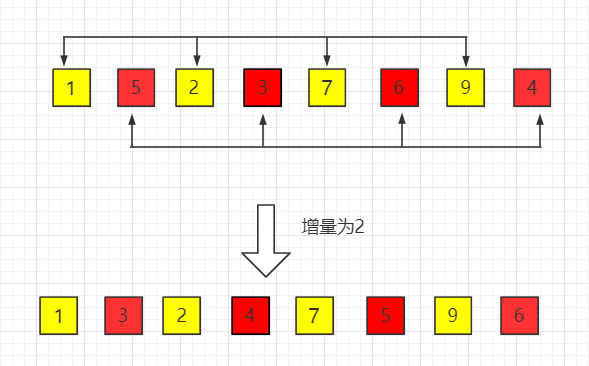
在此我们选择增量 gap=length/2,缩小增量以 gap = gap/2 的方式,用序列 {n/2,(n/2)/2...1} 来表示。
如图示例:
(1)初始增量第一趟 gap = length/2 = 4
(2)第二趟,增量缩小为 2
(3)第三趟,增量缩小为 1,得到最终排序结果


C语言实现代码如下:
//希尔排序
void ShellSort(SqList *L)
{
int i, j, increment = L->last;
do
{
increment = increment / 3 + 1;
for (i = increment + 1; i <= L->last; i++)
{
if (L->arr[i] < L->arr[i - increment])
{
L->arr[0] = L->arr[i];
for (j = i - increment; j > 0 && L->arr[0] < L->arr[j]; j -= increment)
L->arr[j + increment] = L->arr[j];
L->arr[j + increment] = L->arr[0];
}
}
} while (increment > 1);
}














 530
530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









