







1.什么是正则表达式??
正则表达式定义字符串的搜索模式 ,正则表达式的英文全称是regular expression。搜索模式可以是简单字符,固定字符串或包含描述模式的特殊字符的复杂表达式的任何内容 ,由正则表达式定义的 pattern 可以同时匹配一个或多个,或者一个都没匹配到。
正则表达式有两个特殊的符号'^'和'$'。他们的作用是分别指出一个字符串的开始和结束,下面进行语法的详细介绍:
一、行定位符(^和$)
行定位符就是用来描述字串的边界。“^”表示行的开始;“$”表示行的结尾。如:
^tm : 该表达式表示要匹配字串tm的开始位置是行头,如tm equal Tomorrow Moon就可以匹配
tm$ : 该表达式表示要匹配字串tm的位置是行尾,Tomorrow Moon equal tm匹配。
如果要匹配的字串可以出现在字符串的任意部分,那么可以直接 写成 :tm
二、单词定界符(\b、\B)
单词分界符\b,表示要查找的字串为一个完整的单词。如:\btm\b
还有一个大写的\B,意思和\b相反。它匹配的字串不能是一个完整的单词,而是其他单词或字串的一部分。如:\Btm\B
三、字符类([ ])
方括号表示某些字符允许在一个字符串中的某一特定位置出现:
注意事项:
1.特殊字符需要转义才能匹配
"^.$()¦*+?{\"这些字符前加上转移字符'\'.
2.在方括号中,不需要转义字符,
3.正则表达式是区分大小写的。
若要忽略大小写可使用方括号表达式“[]”。只要匹配的字符出现在方括号内,即可表示匹配成功。但要注意:一个方括号只能匹配一个字符。例如,要匹配的字串tm不区分大小写,那么该表达式应该写作如下格式:[Tt][Mm]
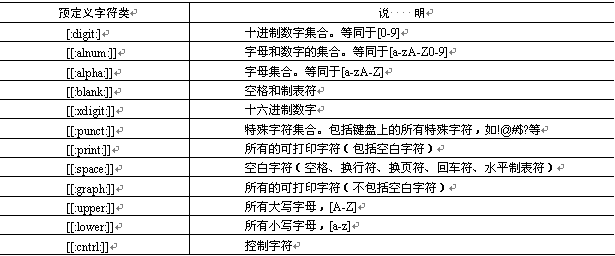
POSIX风格的预定义字符类如表所示:
四、选择字符(|)
还有一种方法可以实现上面的匹配模式,就是使用选择字符(|)。该字符可以理解为“或”,如上例也可以写成 (T|t)(M|m),该表达式的意思是以字母T或t开头,后面接一个字母M或m。
使用“[]”和使用“|”的区别在于“[]”只能匹配单个字符,而“|”可以匹配任意长度的字串。如果不怕麻烦,上例还可以写为 :TM|tm|Tm|tM
五、连字符(-)
变量的命名规则是只能以字母和下划线开头。但这样一来,如果要使用正则表达式来匹配变量名的第一个字母,要写为 :[a,b,c,d…A,B,C,D…]
这无疑是非常麻烦的,正则表达式提供了连字符“-”来解决这个问题。连字符可以表示字符的范围。如上例可以写成 :[a-zA-Z]
六、排除字符([^])
上面的例子是匹配符合命名规则的变量。现在反过来,匹配不符合命名规则的变量,正则表达式提供了“^”字符。这个元字符在前面出现过,表示行的开始。而这里将会放到方括号中,表示排除的意思。
例如:[^a-zA-Z],该表达式匹配的就是不以字母和下划线开头的变量名。
七、限定符(? * + {n,m})
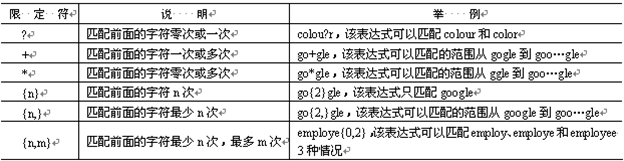
对于重复出现字母或字串,可以使用限定符来实现匹配。限定符主要有6种,如表所示:
例如:
"ab*":表示一个字符串有一个a后面跟着零个或若干个b。("a", "ab", "abbb",……);
"ab+":表示一个字符串有一个a后面跟着至少一个b或者更多;
"ab?":表示一个字符串有一个a后面跟着零个或者一个b;
"a?b+$":表示在字符串的末尾有零个或一个a跟着一个或几个b。也可以使用{}来表示
其实:'*','+'和 '?'相当于"{0,}","{1,}"和"{0,1}"。
八、点号字符(.)
点字符(.)可以匹配出换行符外的任意一个字符。
注意:是除了换行符外的、任意的一个字符。如匹配以s开头、t结尾、中间包含一个字母的单词。
格式如下: ^s.t$,匹配的单词包括:sat、set、sit等。
再举一个实例,匹配一个单词,它的第一个字母为r,第3个字母为s,最后一个字母为t。能匹配该单词的正则表达式为:^r.s.*t$
九、转义字符(\)
正则表达式中的转移字符(\)和PHP中的大同小异,都是将特殊字符(如“.”、“?”、“\”等)变为普通的字符。举一个IP地址的实例,用正则表达式匹配诸如127.0.0.1这样格式的IP地址。如果直接使用点字符,格式为:[0-9]{1,3}(.[0-9]{1,3}){3}
这显然不对,因为“.”可以匹配一个任意字符。这时,不仅是127.0.0.1这样的IP,连127101011这样的字串也会被匹配出来。所以在使用“.”时,需要使用转义字符(\)。修改后上面的正则表达式格式为: [0-9]{1,3}(\.[0-9]{1,3}){3}
十、反斜线(\)
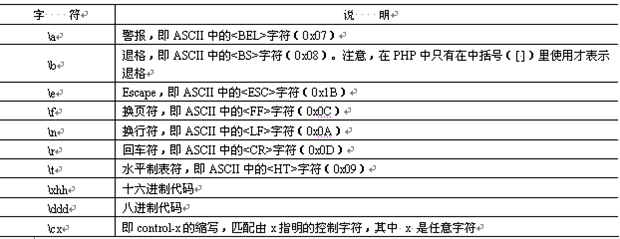
除了可以做转义字符外,反斜线还有其他一些功能。反斜线可以将一些不可打印的字符显示出来,如表所示:
还可以指定预定义字符集,如表所示:

反斜线还有一种功能,就是定义断言,其中已经了解过了\b、\B,其他如表所示:

十一、括号字符(())
小括号字符的第一个作用就是可以改变限定符的作用范围,如“|”、“*”、“^”等。来看下面的一个表达式。
(thir|four)th,这个表达式的意思是匹配单词thirth或fourth,如果不使用小括号,那么就变成了匹配单词thir和fourth了。
小括号的第二个作用是分组,也就是子表达式。如(\.[0-9]{1,3}){3},就是对分组(\.[0-9]{1,3})进行重复操作。后面要学到的反向引用和分组有着直接的关系。
十二、反向引用
十三、模式修饰符
模式修饰符的作用是设定模式。也就是规定正则表达式应该如何解释和应用。
不同的语言都有自己的模式设置,PHP中的主要模式如表所示:

重要点:
1.\w:用于匹配字母,数字或下划线字符
例如:/校验密码:只能输入6-20个字母、数字、下划线
2.\d:用于匹配从0到9的数字
例如:校验普通电话、传真号码:可以“+”或数字开头,可含有“-” 和 “ ”
3. //校验纯中文字符 /^[\u4E00-\u9FA5]+$/
"^\d+$" //非负整数(正整数 + 0)
"^[0-9]*[1-9][0-9]*$" //正整数
"^((-\d+)|(0+))$" //非正整数(负整数 + 0)
"^-[0-9]*[1-9][0-9]*$" //负整数
"^-?\d+$" //整数
"^\d+(\.\d+)?$" //非负浮点数(正浮点数 + 0)
"^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$" //正浮点数
"^((-\d+(\.\d+)?)|(0+(\.0+)?))$" //非正浮点数(负浮点数 + 0)
"^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$" //负浮点数
"^(-?\d+)(\.\d+)?$" //浮点数
"^[A-Za-z]+$" //由26个英文字母组成的字符串
"^[A-Z]+$" //由26个英文字母的大写组成的字符串
"^[a-z]+$" //由26个英文字母的小写组成的字符串
"^[A-Za-z0-9]+$" //由数字和26个英文字母组成的字符串
"^\w+$" //由数字、26个英文字母或者下划线组成的字符串
"^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$" //email地址
"^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$" //url
/^(d{2}|d{4})-((0([1-9]{1}))|(1[1|2]))-(([0-2]([1-9]{1}))|(3[0|1]))$/ // 年-月-日
/^((0([1-9]{1}))|(1[1|2]))/(([0-2]([1-9]{1}))|(3[0|1]))/(d{2}|d{4})$/ // 月/日/年
"^([w-.]+)@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.)|(([w-]+.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(]?)$" //Emil
"(d+-)?(d{4}-?d{7}|d{3}-?d{8}|^d{7,8})(-d+)?" //电话号码
"^(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5])$" //IP地址
^([0-9A-F]{2})(-[0-9A-F]{2}){5}$ //MAC地址的正则表达式
^[-+]?\d+(\.\d+)?$ //值类型正则表达式
最后,介绍下JAVA中正则表达式的使用:
java中提供了两个类来支持正则表达式的操作,
分别是java.util.regex下的Pattern类和Matcher类,以下为这两个类的介绍与使用:
Pattern类:使用Pattern类进行字符串的拆分,使用的方法是String[] split(CharSequence input)
Matcher类:使用Matcher类进行字符串的验证和替换,
匹配使用的方法是boolean matches();替换使用的方法是 String replaceAll(String replacement)
Pattern类的构造方法是私有的
所以我们使用Pattern p = Pattern.compile("a*b");进行实例化
Matcher类的实例化依赖Pattern类的对象Matcher m = p.matcher("aaaaab");
Pattern与Matcher的使用:
首先创建一个定义正则表达式的Pattern对象。此Pattern对象允许您为给定的字符串创建Matcher对象。这个Matcher对象然后允许你对String进行正则表达式操作
//验证email是否正确
public static void main(String[] args) {
// 要验证的字符串
String str = "service@xsoftlab.net";
// 邮箱验证规则
String regEx = "[a-zA-Z_]{1,}[0-9]{0,}@(([a-zA-z0-9]-*){1,}\\.){1,3}[a-zA-z\\-]{1,}";
// 编译正则表达式
Pattern pattern = Pattern.compile(regEx);
// 忽略大小写的写法
// Pattern pat = Pattern.compile(regEx, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(str);
// 字符串是否与正则表达式相匹配
boolean rs = matcher.matches();
System.out.println(rs);
}但在实际的开发中,为了方便我们很少直接使用Pattern类或Matcher类,而是使用String类下的方法
验证:boolean matches(String regex)
拆分: String[] split(String regex)
替换: String replaceAll(String regex, String replacement)















 856
856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









