






Hadoop 分为三部分 : Common、HDFS 、Yarn、MapReduce
Hadoop生态圈:除了hadoop技术以外,还有hive、zookeeper、flume、sqoop、datax、azkaban等一系列技术。这里我们主要简单介绍一下HDFS和安装搭建流程。
HDFS (Hadoop Distributed File System) 是 Apache Hadoop 生态系统中的一个核心组件,用于存储和管理大规模数据集。HDFS 旨在处理大规模数据并提供高可靠性、高容错性的数据存储解决方案。它的设计灵感来源于 Google 的 Google File System (GFS)。
HDFS 采用了主从架构,其中包括一个主节点(NameNode)和多个数据节点(DataNode)。NameNode 负责管理文件系统元数据(如目录结构、文件名称、权限等),而 DataNode 负责存储实际的数据块。数据被分成固定大小的块并存储在不同的数据节点上,从而实现数据的分布式存储和处理。
HDFS 具有以下主要特点:
- 高容错性:数据存储在多个数据节点上,即使某个节点出现故障也不会导致数据丢失。
- 高扩展性:可以很容易地扩展集群规模来适应不断增长的数据量。
- 高吞吐量:适合存储大文件和进行批处理操作,能够提供高速数据读取和写入。
- 简单的文件模型:HDFS 提供类似传统文件系统的接口,易于用户理解和操作。
HDFS 在大数据处理场景中得到广泛应用,常用于存储海量数据、支持大规模数据处理任务(如 MapReduce、Spark 等)、构建数据湖等用途。
HDFS(Hadoop Distributed File System)有三种不同的部署模式:选择适合的部署模式取决于您的需求和实际场景,可以根据具体情况选择单节点模式、伪分布式模式或完全分布式模式来部署HDFS。
1、单节点模式(Single Node Mode)
单节点模式(又称本地模式),HDFS运行在单个节点上,适用于开发、测试和调试环境。在这种模式下,HDFS的NameNode和DataNode都在同一个节点上运行。此模式安装比较简单,具体步骤如下:
我们首先从官网下载安装包:这里我们用的3.3.1版本Index of /hadoop/common![]() https://downloads.apache.org/hadoop/common/
https://downloads.apache.org/hadoop/common/

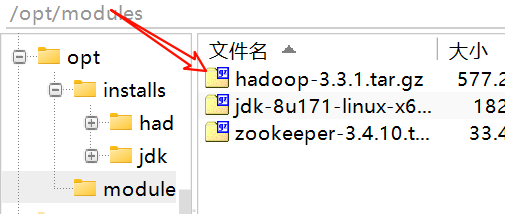
1、上传压缩包到虚拟机,这里我们把压缩包放到了/opt/modules目录下
2、解压到install文件夹
tar -zxvf hadoop-3.3.1.tar.gz -C /opt/installs/
3、重命名为hadoop
cd /opt/installs/
mv hadoop-3.3.1 hadoop
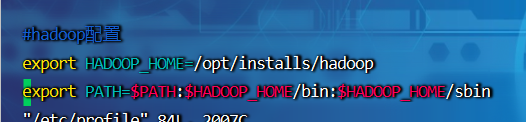
4、输入vi /etc/profile在文件最底部配置环境变量export HADOOP_HOME=/opt/installs/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
5、刷新配置文件
source /etc/profile
6、验证hadoop命令是否可以识别
hadoop version

2、伪分布式模式(Pseudo-Distributed Mode)
伪分布:按照分布式的步骤搭建,但是呢,服务器只有一台。
在伪分布式模式下,HDFS模拟了一个完整的分布式环境,每个组件都在不同的进程中运行。虽然各个组件在不同的进程中运行,但它们仍然在同一台机器上。这种模式适合用于测试和学习,以及小规模数据处理任务。
进行搭建之前的准备工作需要:
环境准备⼯作:
1、安装了jdk
2、安装了hadoop
3、关闭了防⽕墙
systemctl status firewalld
4、免密登录
⾃⼰对⾃⼰免密
ssh-copy-id bigdata01 选择yes 输⼊密码
测试免密是否成功: ssh bigdata01
5、修改linux的⼀个安全机制
vi /etc/selinux/config
修改⾥⾯的 SELINUX=disabled
6、设置host映射
准备工作完成后进行如下操作:
首先vim /opt/installs/hadoop/etc/hadoop进入目录下
以下圈住的都是比较重要的文件:

在core-site.xml底部加入下面代码(注意删掉原本的<configuration></configuration>,)
<configuration>
<!-- 设置namenode节点 -->
<!-- 注意: hadoop1.x时代默认端⼝9000 hadoop2.x时代默认端⼝8020 hadoop3.x时 代默认端⼝ 9820 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9820</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的⼀个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/installs/hadoop/tmp</value>
</property>
</configuration>在hdfs-site.xml底部加入下面代码
<configuration>
<property>
<!--备份数量-->
<name>dfs.replication</name>
<value>1</value>
</property>
<!--secondarynamenode守护进程的http地址:主机名和端⼝号。参考守护进程布局 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata01:9868</value>
</property>
<!-- namenode守护进程的http地址:主机名和端⼝号。参考守护进程布局 -->
<property>
<name>dfs.namenode.http-address</name>
<value>bigdata01:9870</value>
</property>
</configuration>在hadoop-env.sh中配置:
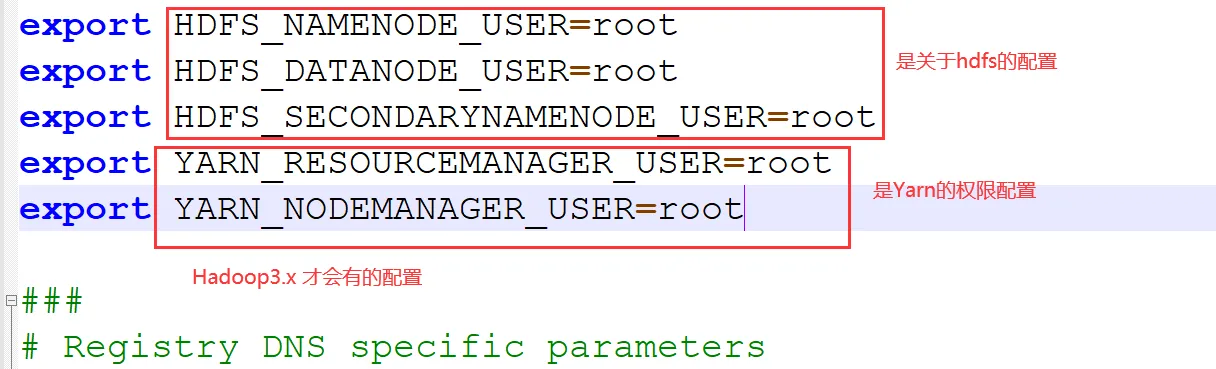
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=rootexport JAVA_HOME=/opt/installs/jdk (根据自己的Java路径)
修改workers 文件:
vi workers
修改里面的内容为: bigdata01(自己的虚拟机名字)然后保存
对整个集群进行namenode格式化:
hdfs namenode -format
注意:
格式化其实就是创建了一系列的文件夹:
这个文件夹的名字是 logs tmp
假如你想格式化第二次,需要先删除这两个文件夹,然后再格式化
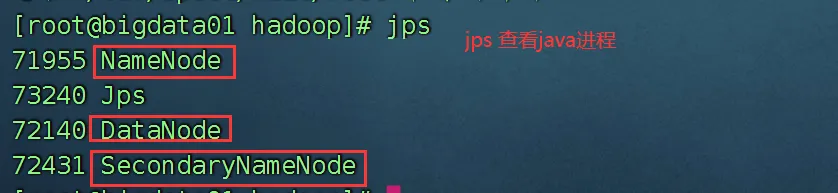
格式化之后就可以启动集群了:start-dfs.sh
通过网址访问hdfs集群:
http://192.168.233.128:9870/(这里是我的网址(192.168.233.128),你的可以输入命令:ip addr查看)
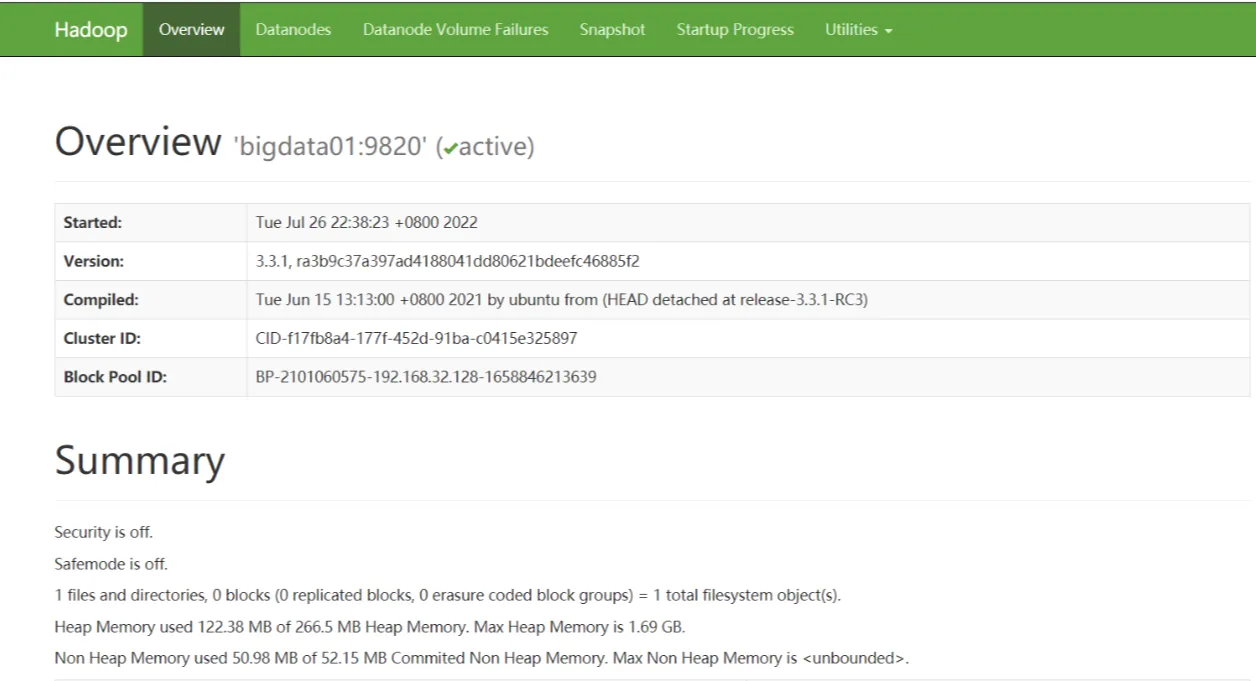
如果访问不到:可以检查防火墙是否关闭。
至此,HDFS伪分布式就搭建好了。
伪分布模式,只会获取hdfs上的数据,将来的结果也放入到hdfs上,不会获取本地数据:
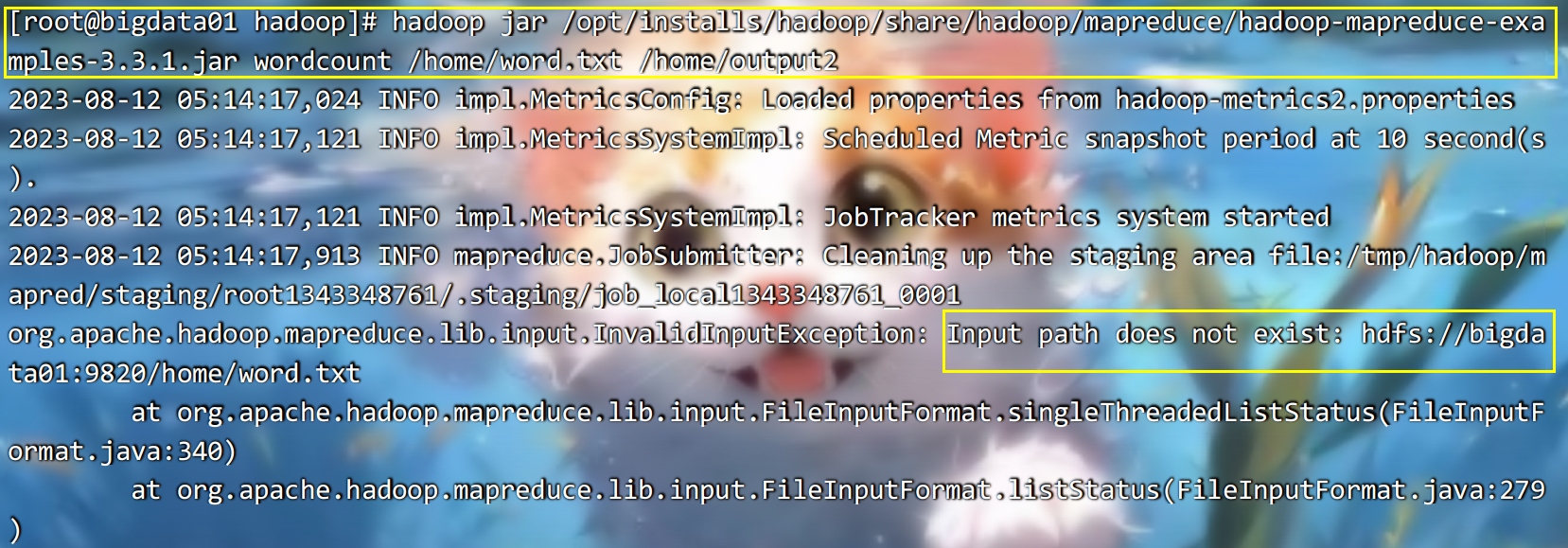
3、完全分布式模式(Fully-Distributed Mode)
在完全分布式模式下,HDFS运行在一个由多台计算机组成的集群中,每台计算机都可能承担不同的角色,如NameNode、DataNode、Secondary NameNode等。这种模式适用于大规模数据处理和生产环境,能够提供高可用性和可伸缩性。
全分布模式:必须至少有三台以上的Linux
1、前期准备工作:
检查是否满足以下要求:
环境准备⼯作:
1、安装了jdk
2、设置host映射(这里是我的ip地址及虚拟机名称,你可以设置为你自己的)
192.168.32.128 bigdata01
192.168.32.129 bigdata02
192.168.32.130 bigdata03
远程拷贝:(拷贝文件到另两台虚拟机上)
scp -r /etc/hosts root@bigdata02:/etc/
scp -r /etc/hosts root@bigdata03:/etc/
3、免密登录
bigdata01 免密登录到bigdata01 bigdata02 bigdata03
ssh-copy-id bigdata03
4、第一台安装了hadoop
5、关闭了防⽕墙
systemctl status firewalld
6、修改linux的⼀个安全机制
vi /etc/selinux/config
修改⾥⾯的 SELINUX=disabled
2、检查各项内容是否到位
如果以前安装的有伪分布模式,服务要关闭。 stop-dfs.sh
3、修改bigdata01配置文件
路径:/opt/installs/hadoop/etc/hadoop
在core-site.xml底部加入下面代码(注意删掉原本的<configuration></configuration>)
<configuration>
<!-- 设置namenode节点 -->
<!-- 注意: hadoop1.x时代默认端⼝9000 hadoop2.x时代默认端⼝8020 hadoop3.x时 代默认端⼝ 9820 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9820</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的⼀个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/installs/hadoop/tmp</value>
</property>
</configuration>在hdfs-site.xml底部加入下面代码
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--secondarynamenode守护进程的http地址:主机名和端⼝号。参考守护进程布局 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata02:9868</value>
</property>
<!-- namenode守护进程的http地址:主机名和端⼝号。参考守护进程布局 -->
<property>
<name>dfs.namenode.http-address</name>
<value>bigdata01:9870</value>
</property>
</configuration>在hadoop-env.sh中配置:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=rootexport JAVA_HOME=/opt/installs/jdk (根据自己的Java路径)
修改workers 文件:
bigdata01
bigdata02
bigdata03
拷贝前删除Hadoop下的logs和tmp文件(后面进行格式化,可能会影响)

4、修改完了第一台的配置文件,开始分发到其他两台上去。
假如前面没有将bigdata01上的hadoop 拷贝给 02 和 03
那么就远程拷贝:
scp -r /opt/installs/hadoop/ bigdata02:/opt/installs/
scp -r /opt/installs/hadoop/ bigdata03:/opt/installs/
如果以前已经拷贝过了,只需要拷贝刚修改过的配置文件即可:
只需要复制配置文件即可
scp -r /opt/installs/hadoop/etc/hadoop/ root@bigdata02:/opt/installs/hadoop/etc/
scp -r /opt/installs/hadoop/etc/hadoop/ root@bigdata03:/opt/installs/hadoop/etc/
对整个集群进行namenode格式化:
hdfs namenode -format
在主节点启动集群
start-dfs.sh
启动后jps,看到
| bigdata01 | bigdata02 | bigdata03 |
| namenode | secondaryNameNode | x |
| datanode | datanode | datanode |
web访问:namenode 在哪一台,就访问哪一台。http://bigdata01:9870
到这里就配置完成了,如果启动不成功可以查看你的防火墙是否关闭,以及配置文件是否正确
如果有什么不懂可以评论留言,大家相互讨论!
总结:
1、start-dfs.sh 在第一台启动,不意味着只使用了第一台,而是启动了集群。
stop-dfs.sh 其实是关闭了集群
2、一台服务器关闭后再启动,上面的服务是需要重新启动的。
这个时候可以先停止集群,再启动即可。也可以使用单独的命令,启动某一个服务。
hadoop-daemon.sh start namenode # 只开启NameNode
hadoop-daemon.sh start secondarynamenode # 只开启SecondaryNameNode
hadoop-daemon.sh start datanode # 只开启DataNode
hadoop-daemon.sh stop namenode # 只关闭NameNode
hadoop-daemon.sh stop secondarynamenode # 只关闭SecondaryNameNode
hadoop-daemon.sh stop datanode # 只关闭DataNodenamenode 格式化有啥用:
相当于在整个集群中,进行了初始化,其实就是创建文件夹。
你的hadoop安装目录下创建了:logs tmp

















 1676
1676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









