






前言
提示:这里可以添加本文要记录的大概内容:
牛客网数据分析题,练习python。其中主要练习的为pandas。
提示:以下是本篇文章正文内容,下面案例可供参考
一、查看数据
DA1 用pandas查看牛客网用户数据
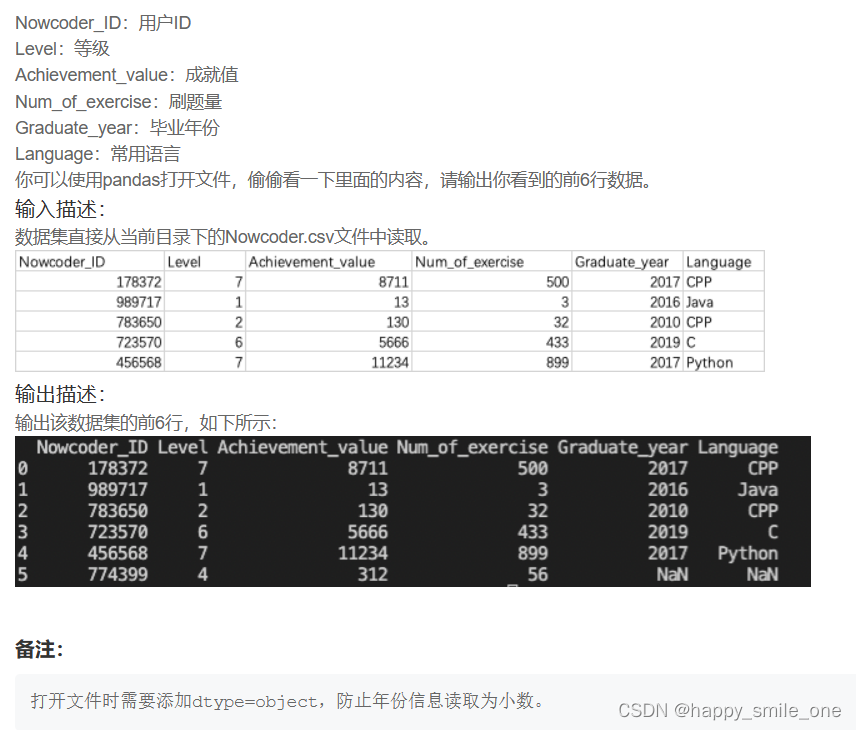
import pandas as pd
df = pd.read_csv('Nowcoder.csv',dtype=object)
print(df.head(6)) #读取前六行
注意备注信息,如果不添加dtype=object,会出现如下错误:

DA2 牛客网用户数据集的大小
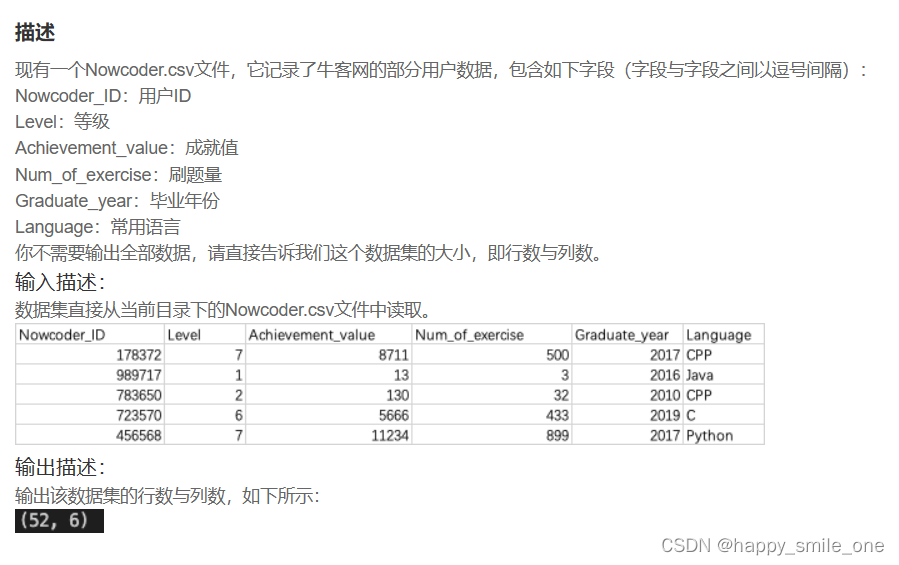 df.shape 显示数据的行数和列数。
df.shape 显示数据的行数和列数。
import pandas as pd
df=pd.read_csv('Nowcoder.csv')
print(df.shape)
DA3 牛客网的第10位用户
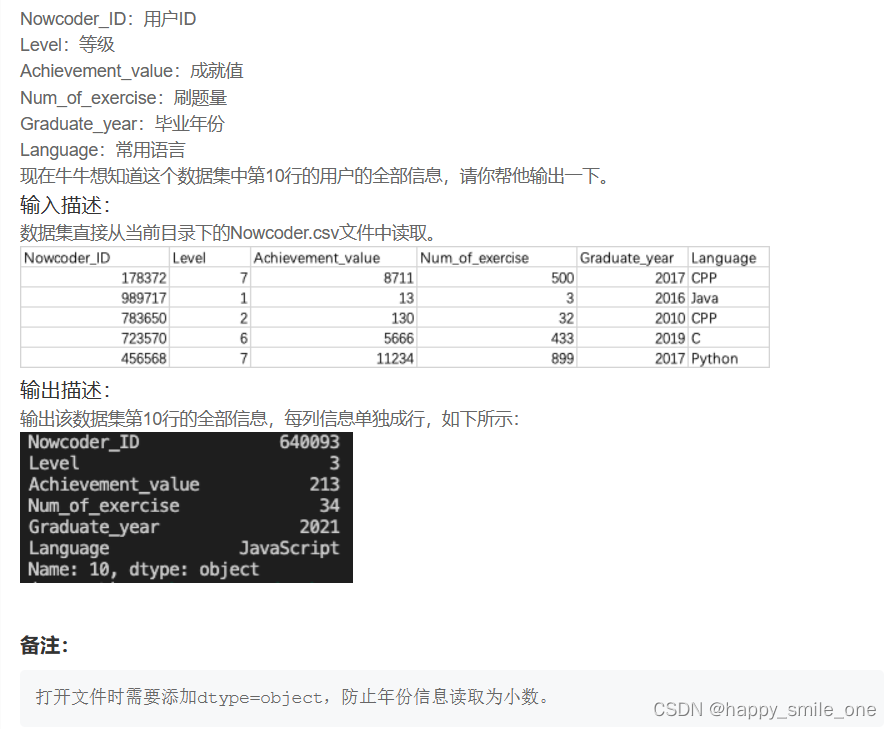
import pandas as pd
df=pd.read_csv('Nowcoder.csv',dtype=object)
print(df.loc[10]) #输出第几行,注意是中括号
DA4 统计牛客网部分用户使用语言
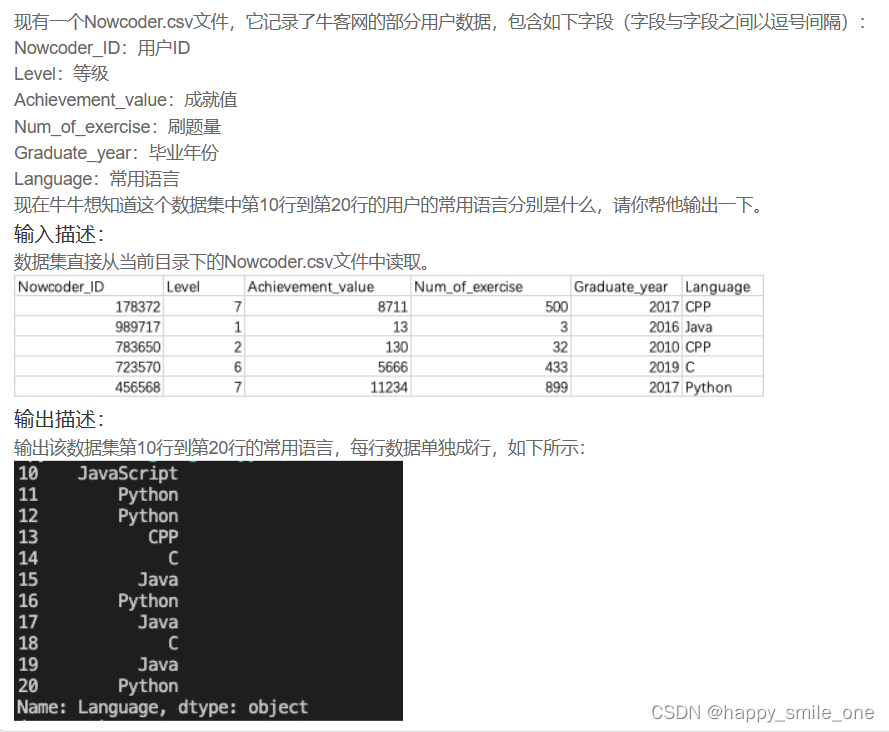
import pandas as pd
df=pd.read_csv('Nowcoder.csv')
print(df.loc[10:20,'Language'])
【python】pandas中 loc & iloc用法及区别
1)loc:通过标签或布尔数组获得一组行和列。
2)iloc:通过整数位置获得行和列的数据。
一、loc :通过标签或布尔数组获得一组行和列。
2-1先定义一个DataFrame:
import pandas as pd
df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
index=['cobra', 'viper', 'sidewinder'],
columns=['max_speed', 'shield'])
DataFrame结果:
max_speed shield
cobra 1 2
viper 4 5
sidewinder 7 8
2-2.loc选定index标签,获取某一行,.loc[],中括号里面是先行后列,以逗号分割,行和列分别是行标签和列标签
1、通过行名称获取整行数据:
获得’cobra’所在的行:
df.loc['viper']
执行结果:
max_speed 1
shield 2
2、通过行名称,列名称定位数据:
df.loc['cobra', 'shield']
执行结果:
2
3、通过切片行标签和单个标签列,获取一组数据:
df.loc['cobra':'viper', 'max_speed']
执行结果:
cobra 1
viper 4
4、通过条件筛选数据:
#先筛选到’shield’这一列大于6所在的数据,并且筛选出对应的这几行
df.loc[df['shield'] > 6]
执行结果:
max_speed shield
sidewinder 7 8
二、iloc :通过整数位置获得行和列的数据。
先定义一个DataFrame
import pandas as pd
df = pd.DataFrame([[1,2,3,4], [100,200,300,400], [1000,2000,3000,4000]],
columns=['a', 'b','c','d'])
DataFrame结果:
a b c d
0 1 2 3 4
1 100 200 300 400
2 1000 2000 3000 4000
1、通过行索引获取数据
#获取index 为0 所在的行数据
df.iloc[0]
执行结果:
a 1
b 2
c 3
d 4
2、通过行索引获取多行数据
df.iloc[[0, 1]]
执行结果:
a b c d
0 1 2 3 4
1 100 200 300 400
3、通过切片index来获取数据
df.iloc[:3]
执行结果:
a b c d
0 1 2 3 4
1 100 200 300 400
2 1000 2000 3000 4000
4、通过切片行和列来获取一组数据
#iloc[]中先行后列,同loc
df.iloc[1:3, 0:3]
执行结果:
a b c
1 100 200 300
2 1000 2000 3000
二、数据索引
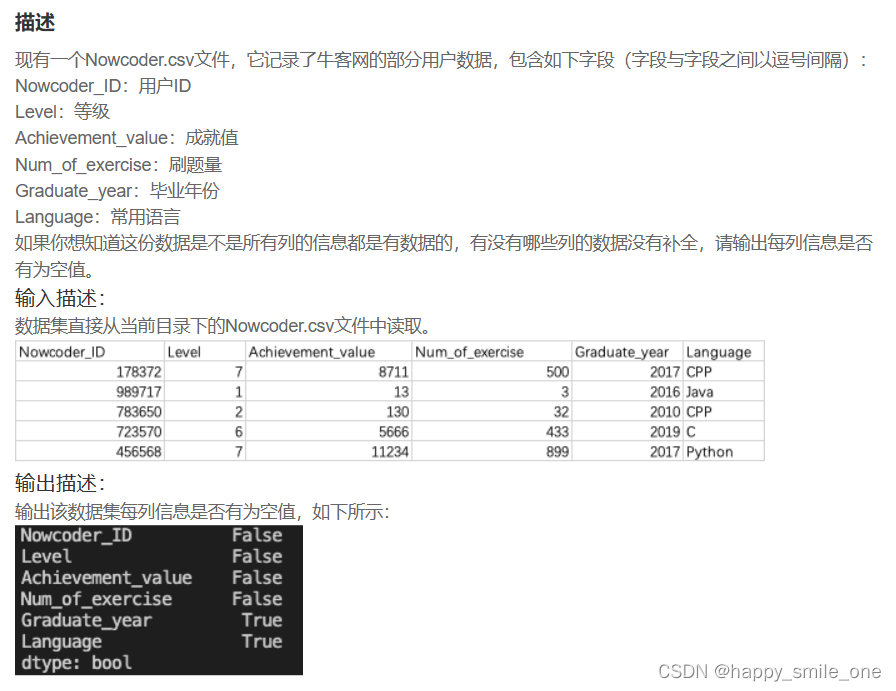
DA5 牛客网用户没有补全的信息
import pandas as pd
df=pd.read_csv('Nowcoder.csv')
print(df.isnull().all())
如果df.isnull()后面接all()函数,就会对数据集每一列的全部数值进行空值判断。只有该列全部数值都为空值,这一列才会返回True;否则就返回False。
pandas 判断指定列是否有(全部是)空值(NaN)
1、判断某列是否有NaN
df['col'].isnull().any()
2、判断某列是否全部为NaN
df['col'].isnull().all()
3、查看表格哪些列是否全为NaN
df.isnull().all()
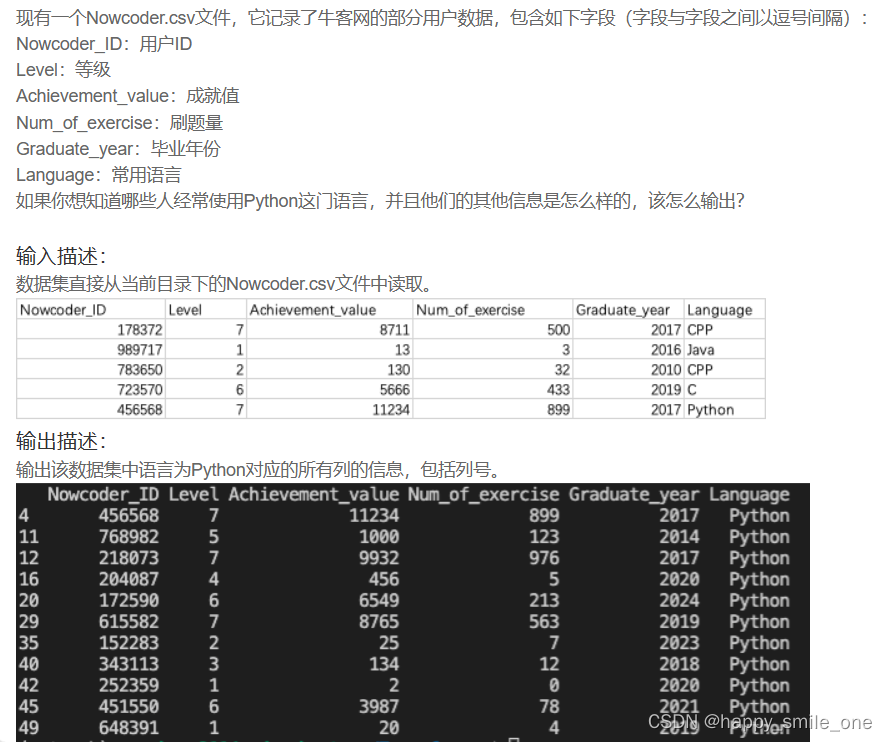
DA6 查看牛客网哪些用户使用Python
备注:
打开文件时需要添加dtype=object,防止年份信息读取为小数。
import pandas as pd
df=pd.read_csv('Nowcoder.csv',dtype=object)
print(df.loc[df['Language'] =='Python']) #Language列为python的行
dtype=object作用
在 df = pd.read_csv(“Nowcoder.csv”, dtype=object) 代码中,dtype 参数用于指定读取 CSV 文件时应该使用的数据类型。通过将 dtype 设置为 object,您告诉 Pandas 将所有列的数据类型解释为通用的 Python 对象类型。
通常,当读取 CSV 文件时,Pandas 会自动尝试推断每列的数据类型。它会根据列中的数据内容进行类型推断,例如将包含数字的列解释为整数或浮点数,将日期时间格式的列解释为日期时间对象,将字符串列解释为字符串类型等。
但是,有时候希望将所有的列都解释为 Python 对象类型(即 object 类型)。这种情况通常出现在以下情况下:
1.数据集中的列具有混合类型,即每列的数据类型不一致。
2.希望保留所有数据的原始表示,而不做类型转换。
通过将 dtype 设置为 object,您可以确保所有列被读取为通用的 Python 对象类型,即字符串或其他可变数据类型。这样可以避免类型转换和数据丢失的问题,但也可能导致一些操作的性能下降。
请注意,根据数据集的大小和类型,将所有列解释为 object 类型可能会导致内存消耗增加。因此,在选择将所有列设置为 object 类型时,请确保您了解数据的特征并仔细考虑后续操作的要求。
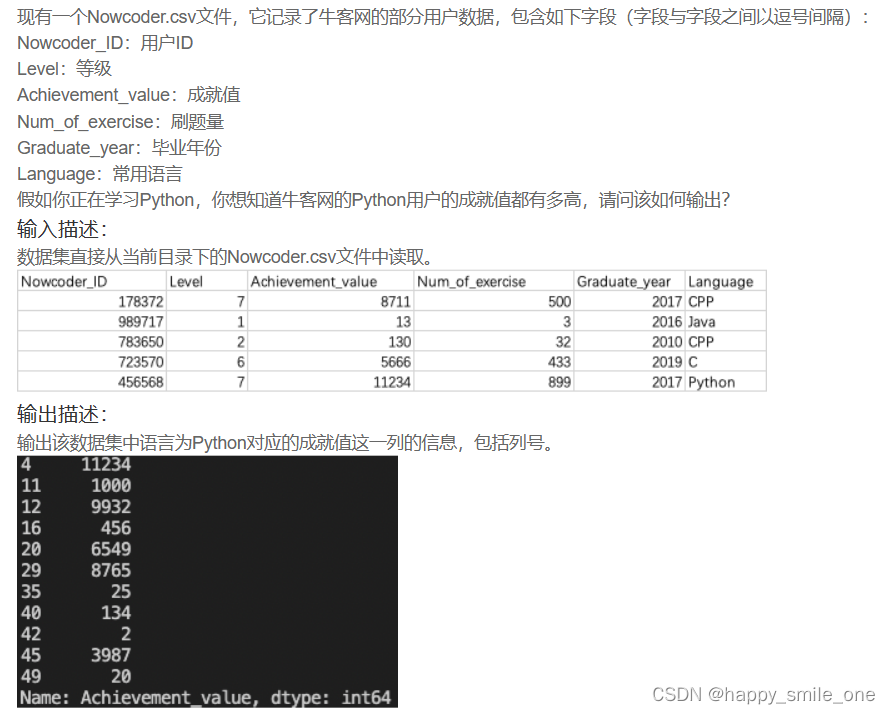
DA7 牛客网Python用户的成就值
import pandas as pd
df=pd.read_csv('Nowcoder.csv')
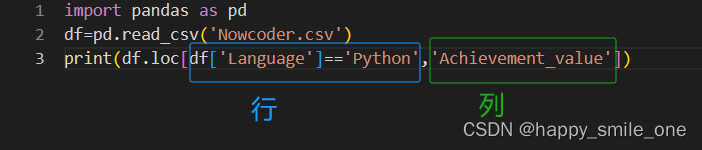
print(df.loc[df['Language']=='Python','Achievement_value'])
DA8 文件最后用户的部分数据
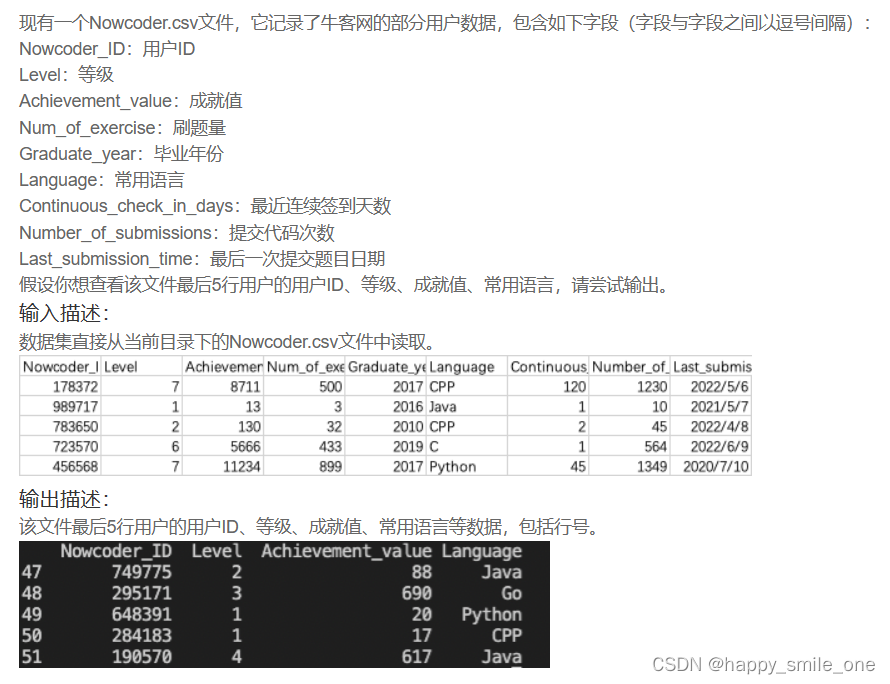
import pandas as pd
df=pd.read_csv('Nowcoder.csv')
print(df.iloc[-5:][['Nowcoder_ID','Level','Achievement_value','Language']])
三、逻辑运算
DA9 2020年毕业的人中最喜欢用Java的用户

import pandas as pd
df = pd.read_csv("Nowcoder.csv")
pd.set_option("display.width", 300) # 设置字符显示宽度
pd.set_option("display.max_rows", None) # 设置显示最大行
pd.set_option("display.max_columns", None)
print(df.loc[(df['Graduate_year'] == 2020)&(df['Language'] == "Java"),:])
#注意这一行,逻辑运算外侧带括号,逗号前表示行
注意:此题需要设置显示的最大宽度
DA9 牛客网C系用户们的信息
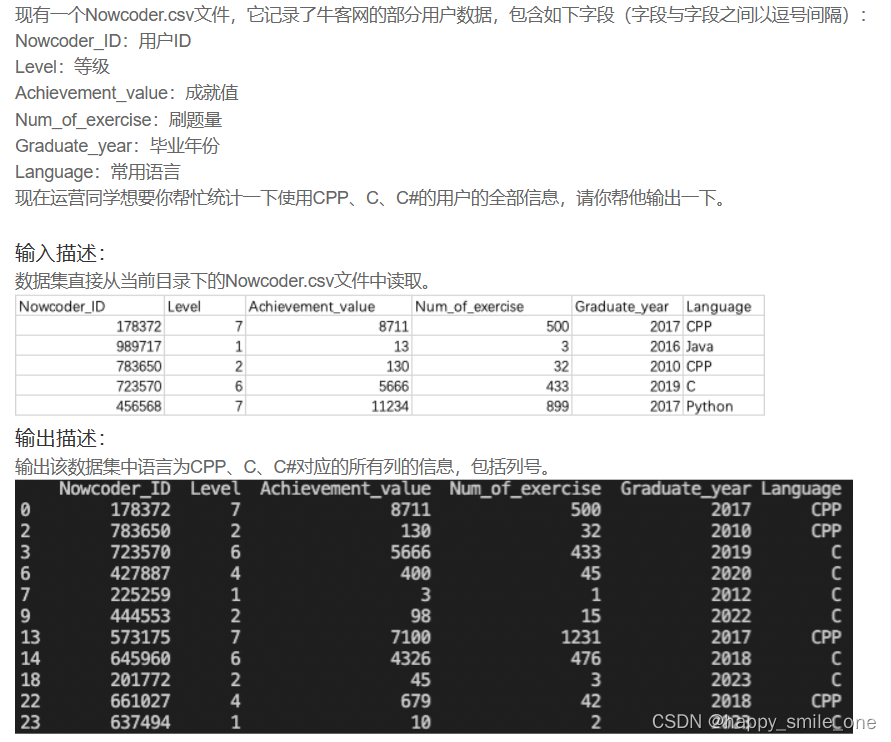
import pandas as pd
df = pd.read_csv("Nowcoder.csv")
pd.set_option("display.width", 500)
pd.set_option("display.max_rows", None) # 最大行数
pd.set_option("display.max_columns", None) # 最大显示列数
print(df.query('Language in ["CPP","C","C#"]'))
DA10 统计牛客网刷题数量500以上的大佬
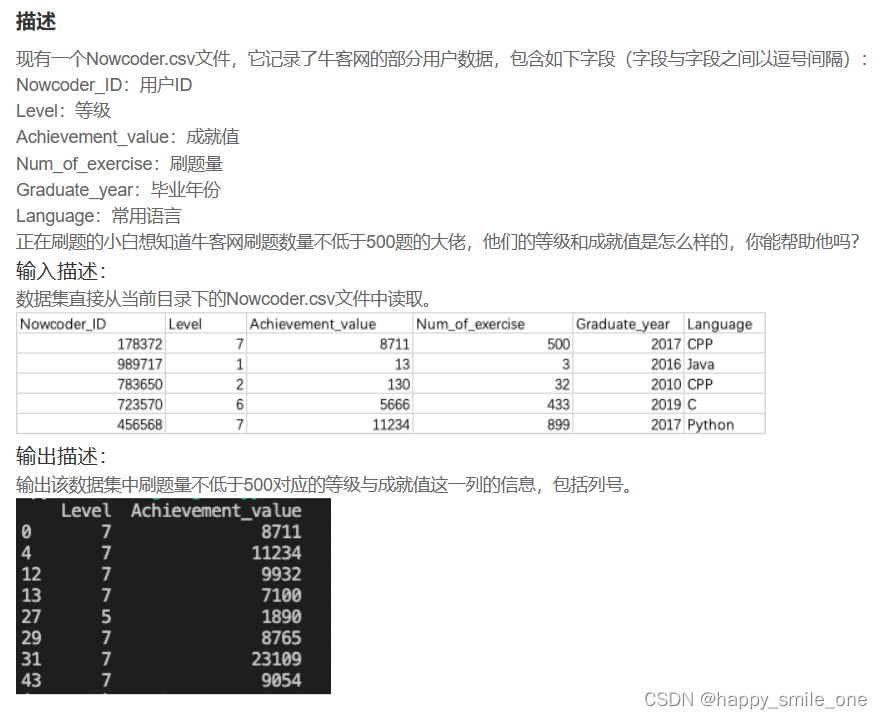
import pandas as pd
df=pd.read_csv('Nowcoder.csv')
print(df.loc[df['Num_of_exercise']>=500,['Level','Achievement_value']])
DA11 按照毕业年份与使用语言筛选牛客网7级用户
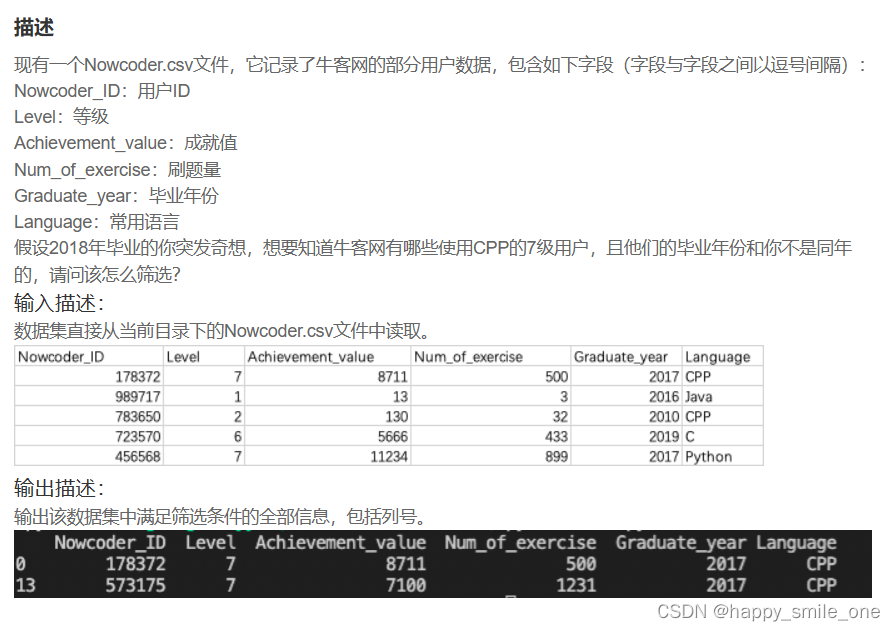
import pandas as pd
df=pd.read_csv('Nowcoder.csv')
pd.set_option('display.width',300)
pd.set_option('display.max_rows',None)
pd.set_option('display.max_columns',None)
print(df.loc[(df['Language']=='CPP')&(df['Level']==7)&(df['Graduate_year']!=2018),:]) #注意,时间是不等于2018
四、中级函数
DA12 牛客网不同语言使用人数
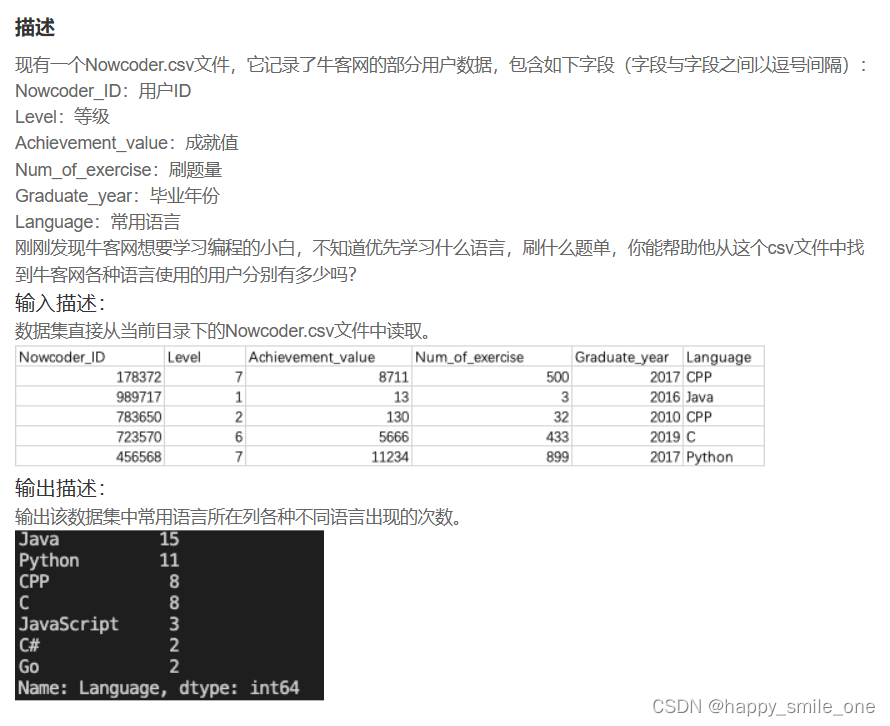
import pandas as pd
df=pd.read_csv('Nowcoder.csv')
print(df['Language'].value_counts()) #value_counts()对语言的值进行计数
value_counts()函数
在pandas中,value_counts常用于数据表的计数及排序,它可以用来查看数据表中,指定列里有多少个不同的数据值,并计算每个不同值有在该列中的个数,同时还能根据需要进行排序。
函数体及主要参数:
value_counts(values,sort=True, ascending=False, normalize=False,bins=None,dropna=True)
sort=True: 是否要进行排序;默认进行排序
ascending=False: 默认降序排列;
normalize=False: 是否要对计算结果进行标准化并显示标准化后的结果,默认是False。
bins=None: 可以自定义分组区间,默认是否;
dropna=True:是否删除缺失值nan,默认删除
DA13 牛客网用户最近的最长与最短连续签到天数
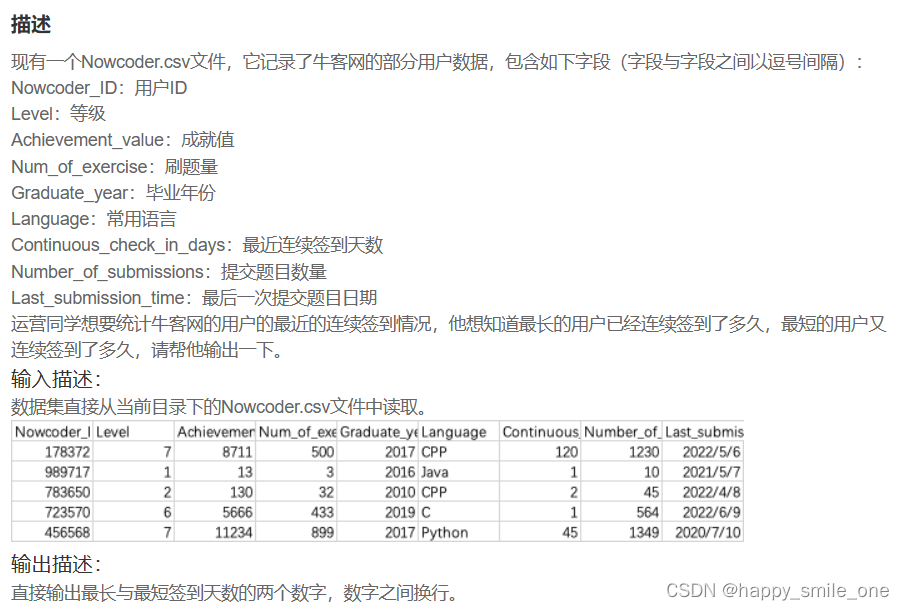
import pandas as pd
df=pd.read_csv("Nowcoder.csv")
print(df['Continuous_check_in_days'].max())
print(df['Continuous_check_in_days'].min())
DA14 Python用户的平均提交次数
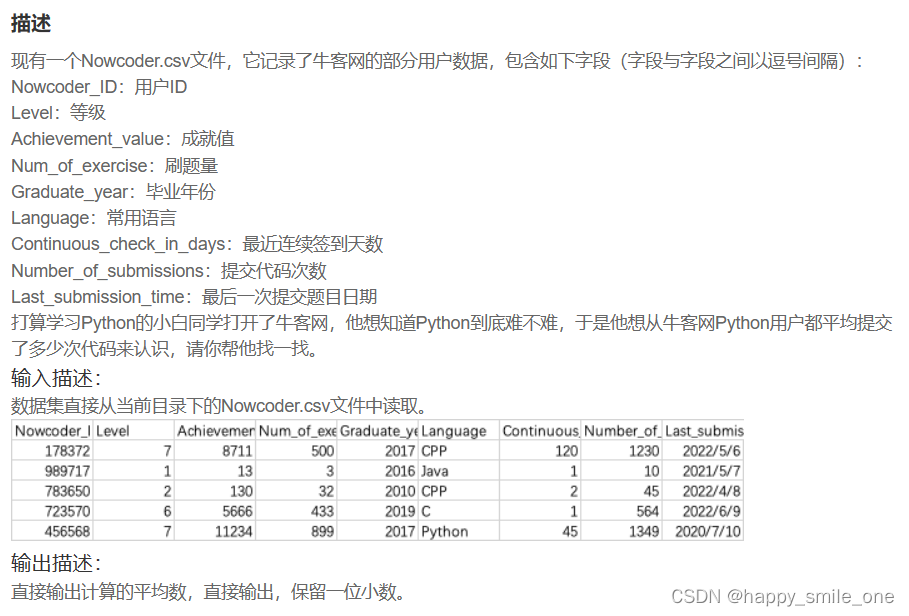
import pandas as pd
df = pd.read_csv("Nowcoder.csv")
# user = df[df.Language == "Python"] #获取所有用户为python的行数据
# result=user["Number_of_submissions"].mean() #对所有python用户的提交次数求平均值
# print(round(result,1)) #保留一位小数
print(round(df[df.Language == "Python"]['Number_of_submissions'].mean(),1))
DA15 牛客网用户等级的中位数
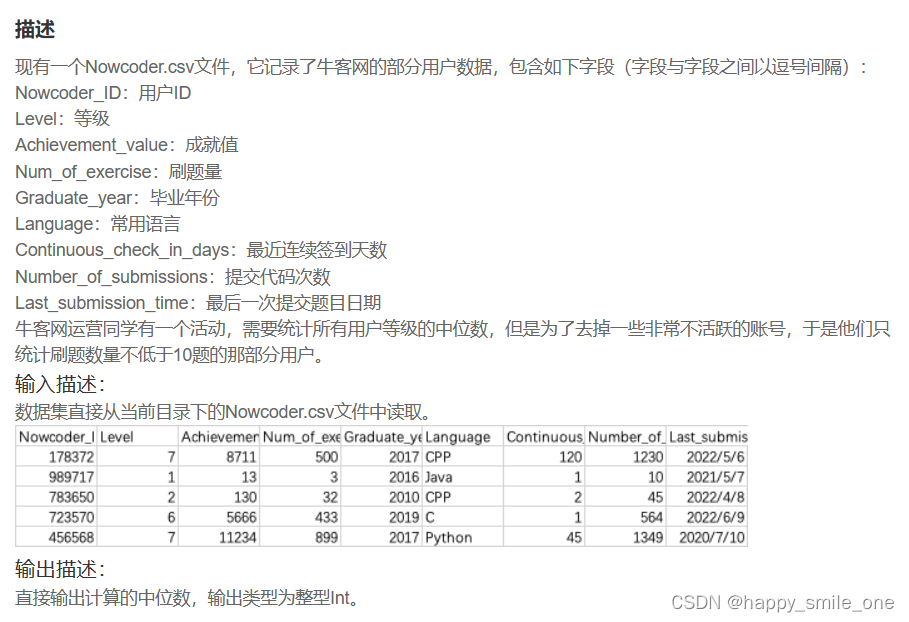
import pandas as pd
df=pd.read_csv('Nowcoder.csv')
user=df[df['Num_of_exercise']>=10]
result=user['Level'].median()
print(int(result))
DA16 用户常用语言有多少
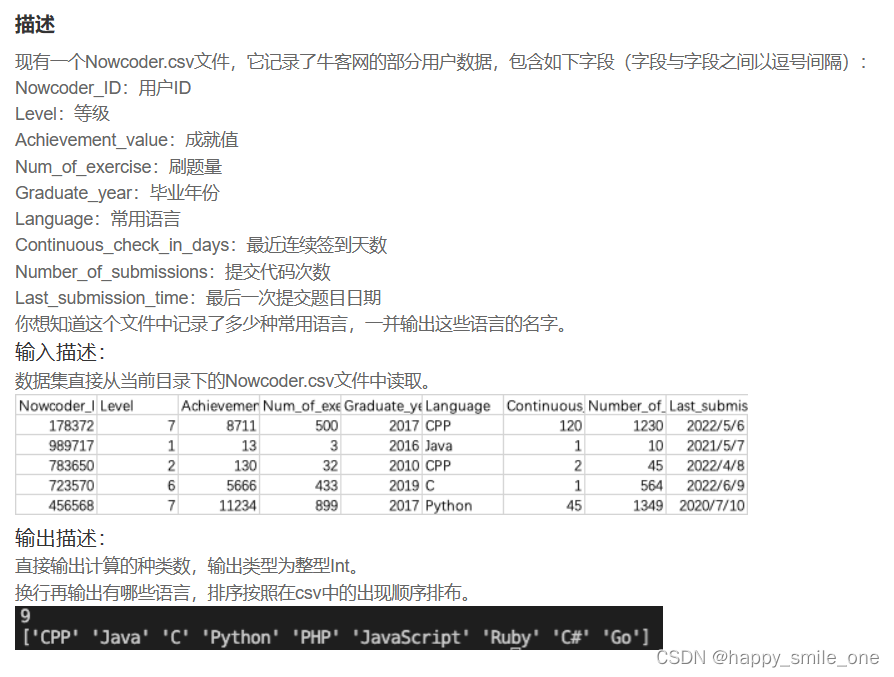
import pandas as pd
df=pd.read_csv('Nowcoder.csv')
# unique()方法返回的是去重之后的不同值,而nunique()方法则直接放回不同值的个数
print(len(df.Language.unique()))
print(list(df.Language.unique()))
# print(df.Language.nunique())
#print(df.Language.tolist())
这题,系统判别有问题,没写完就判对。
DA17 牛客网最多的用户等级
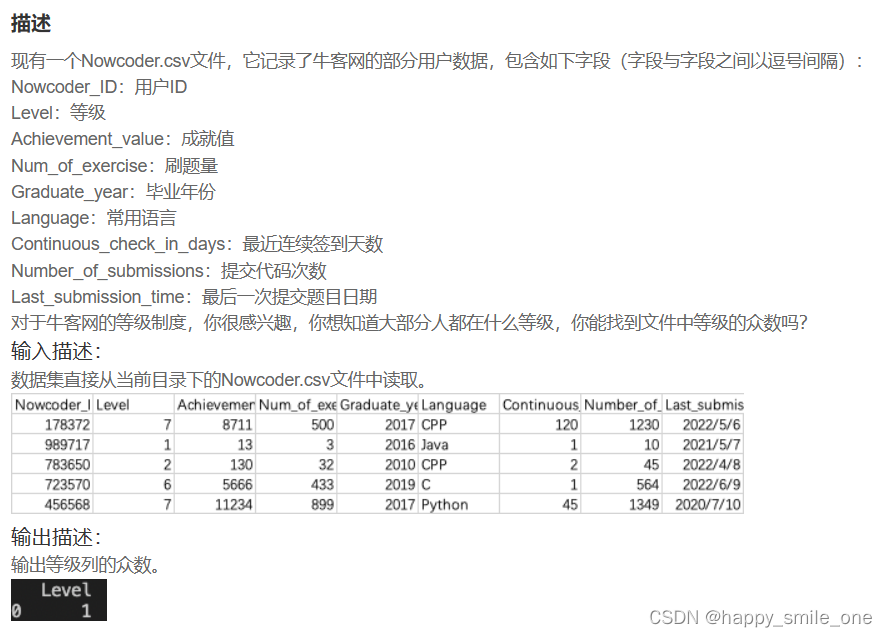
注意:输出格式为DataFrame,直接使用df.mode()函数输出的为series。
知识点:pandas教程:series和dataframe
Series:一种类似于一维数组的对象,是由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的Series对象。注意:Series中的索引值是可以重复的。
DataFrame:一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典。
Series
一个series是一个一维的数据类型,其中每一个元素都有一个标签。类似于Numpy中元素带标签的数组。其中,标签可以是数字或者字符串。
import pandas as pd
df=pd.read_csv('Nowcoder.csv')
#方法一
#将data数据中等级一列的众数求出,并以DataFrame格式表达
# print(df['Level'].mode().to_frame())
#方法二:
# print(df.loc[:,['Level']].mode())
#方法三
print(df[['Level']].mode()) #注意和方法一的区别
DA18 用分位数分析牛客网用户活动
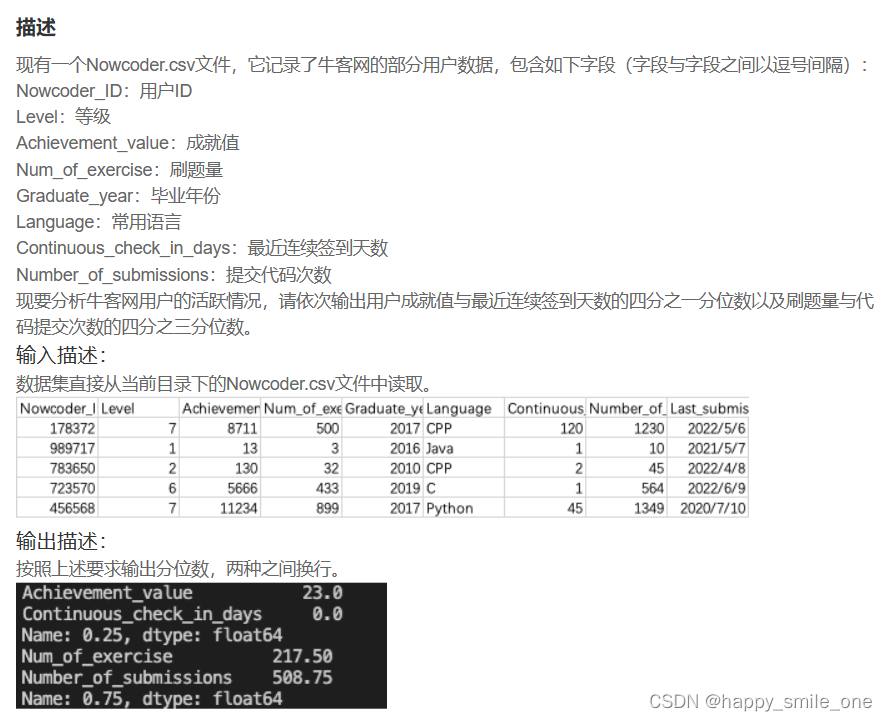
DA18 用分位数分析牛客网用户活动
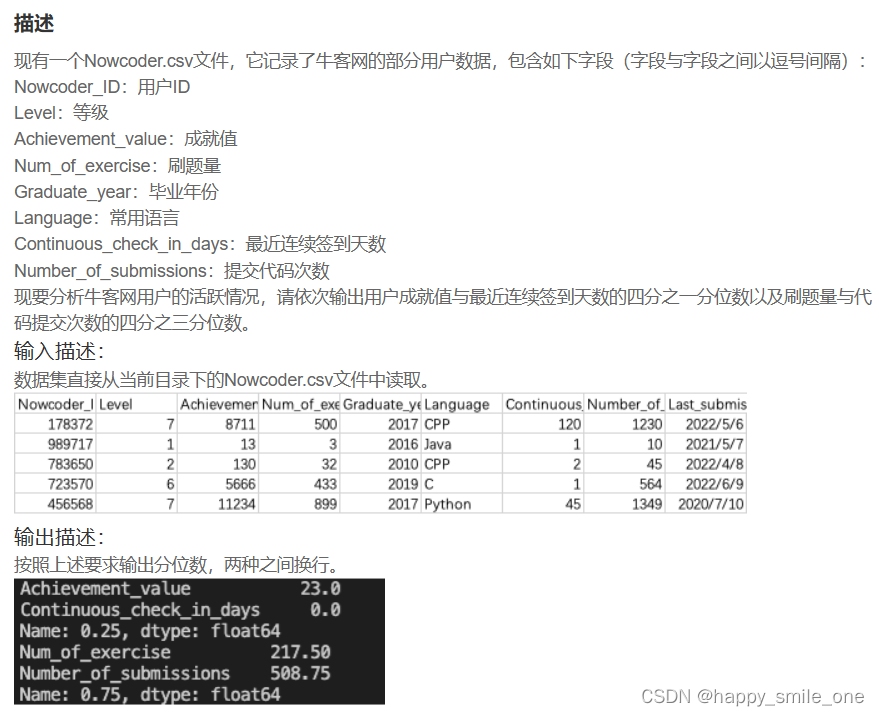
import pandas as pd
df=pd.read_csv('Nowcoder.csv')
print(df[['Achievement_value','Continuous_check_in_days']].quantile(1/4),df[['Num_of_exercise','Number_of_submissions']].quantile(3/4),sep='\n')
#注意两项分位数的输出形式
DA19 牛客网大佬之间的差距
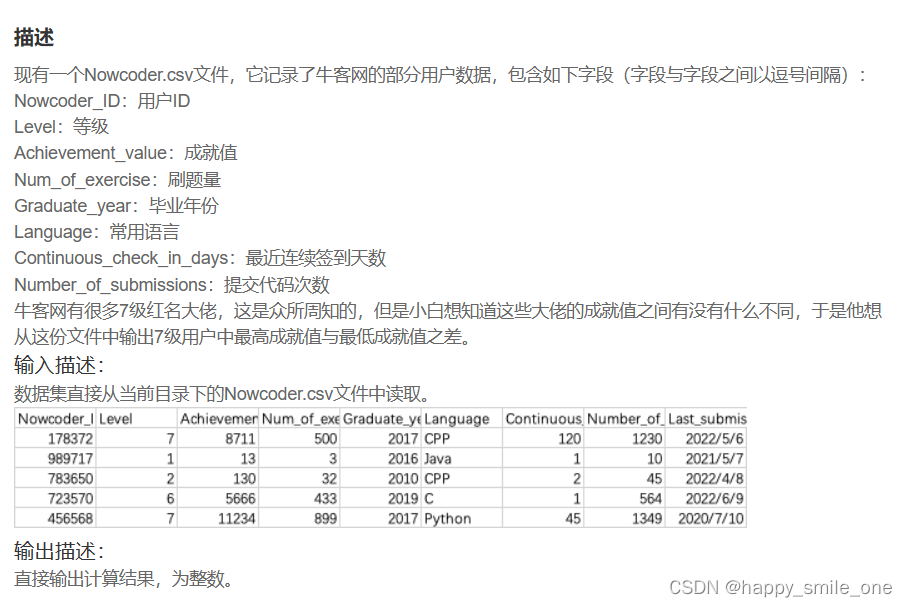
计算最大值和最小值差的函数:
import pandas as pd
df=pd.read_csv('Nowcoder.csv')
seven=df[df['Level']==7]['Achievement_value']
print(seven.values.ptp())
#方法1:numpy.ptp()是计算最大值与最小值差的函数
DA20 牛客用户刷题量的方差与提交次数的标准差
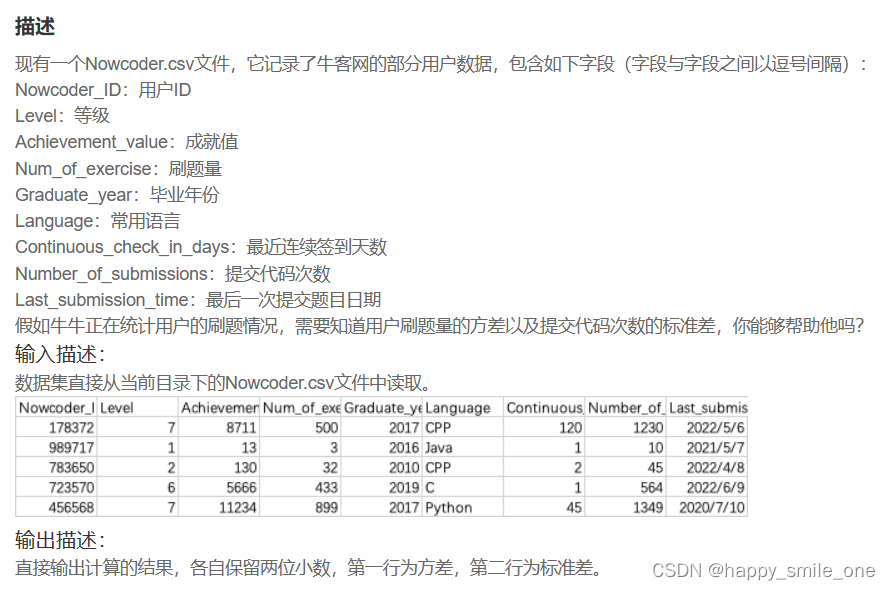
import pandas as pd
df=pd.read_csv('Nowcoder.csv')
print(round(df['Num_of_exercise'].var(),2),round(df['Number_of_submissions'].std(),2),sep='\n')
DA21 大佬用户成就值比例
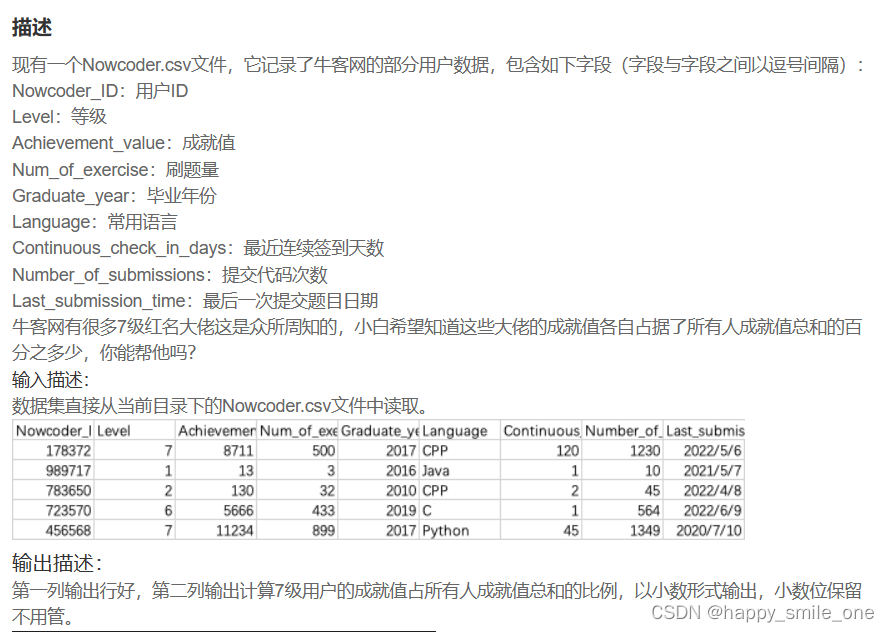
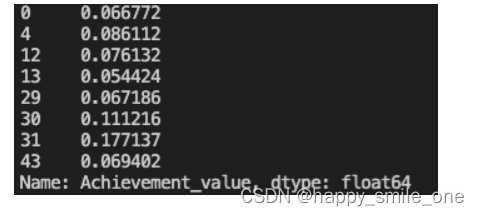
import pandas as pd
df=pd.read_csv('Nowcoder.csv')
seven=df[df['Level']==7]['Achievement_value']
total=df['Achievement_value'].sum()
print(seven/total)
DA22 牛客网用户最高的正确率
import pandas as pd
df=pd.read_csv('Nowcoder.csv')
data=df[df['Num_of_exercise']>10] #获取刷题数大于10的行
result=data['Num_of_exercise']/data['Number_of_submissions']
print(round(result.max(),3))
#方法二
# print(round((data['Num_of_exercise']/data['Number_of_submissions']).max(),3))
DA23 统计牛客网用户的名字长度

import pandas as pd
df=pd.read_csv('Nowcoder.csv')
#len(data['列’]是计算整列的元素个数;data.str.len()是计算元素长度,要求data是str格式
# print(df['Name'].str.len())
print(df['Name'].apply(len))#方法二:使用apply
五、数据清洗
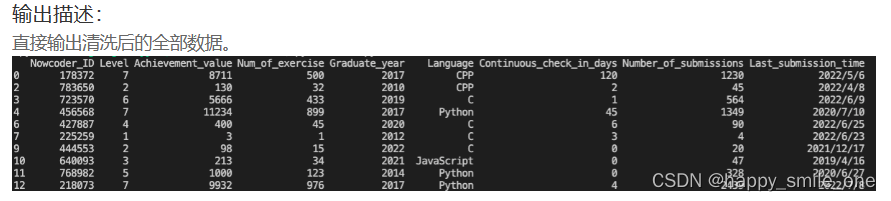
DA24 去掉信息不全的用户
import pandas as pd
df = pd.read_csv("Nowcoder.csv", dtype="object")
pd.set_option("display.width", 300)
pd.set_option("display.max_rows", None)
pd.set_option("display.max_columns", None)
print(df.dropna(axis=0, how="any", thresh=None, subset=None, inplace=False))
Pandas 清洗空值
如果我们要删除包含空字段的行,可以使用 dropna() 方法,语法格式如下:
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数说明:
axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。
how:默认为 ‘any’ 如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置 how=‘all’ 一行(或列)都是 NA 才去掉这整行。
thresh:设置需要多少非空值的数据才可以保留下来的。
subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。
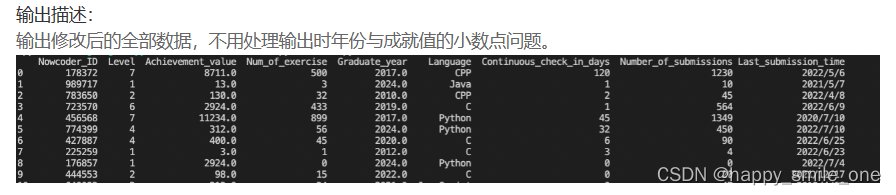
DA25 修补缺失的用户数据
import pandas as pd
df = pd.read_csv("Nowcoder.csv")
pd.set_option("display.width", 300)#设置字符显示宽度
pd.set_option("display.max_rows", None)#设置显示最大行
pd.set_option("display.max_columns", None)#设置显示最大列
df["Graduate_year"].fillna(max(df["Graduate_year"]), inplace=True)
df["Language"].fillna("Python", inplace=True)
df["Achievement_value"].fillna(round(df["Achievement_value"].mean(), 0), inplace=True)
print(df)
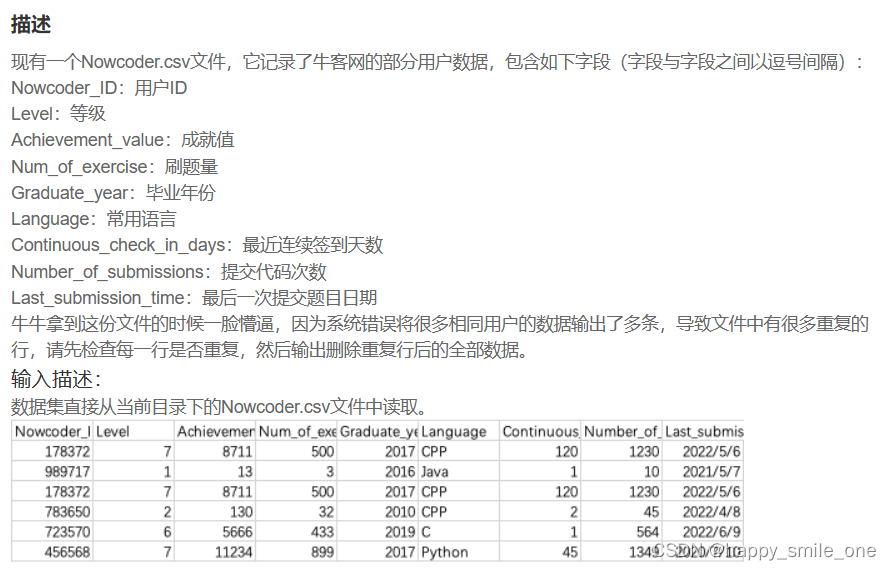
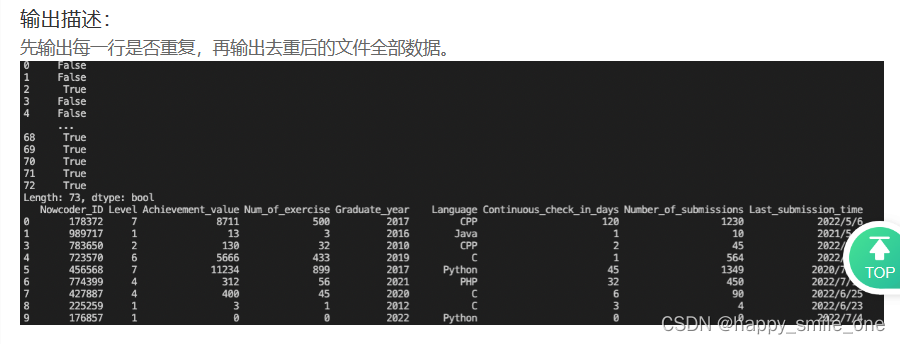
DA26 解决牛客网用户重复的数据
import pandas as pd
df=pd.read_csv('Nowcoder.csv')
print(df.duplicated()) #s输出每一行是否重复
print(df.drop_duplicates(inplace = True)) #删除去重后的文件全部数据
DA27 统一最后刷题日期的格式
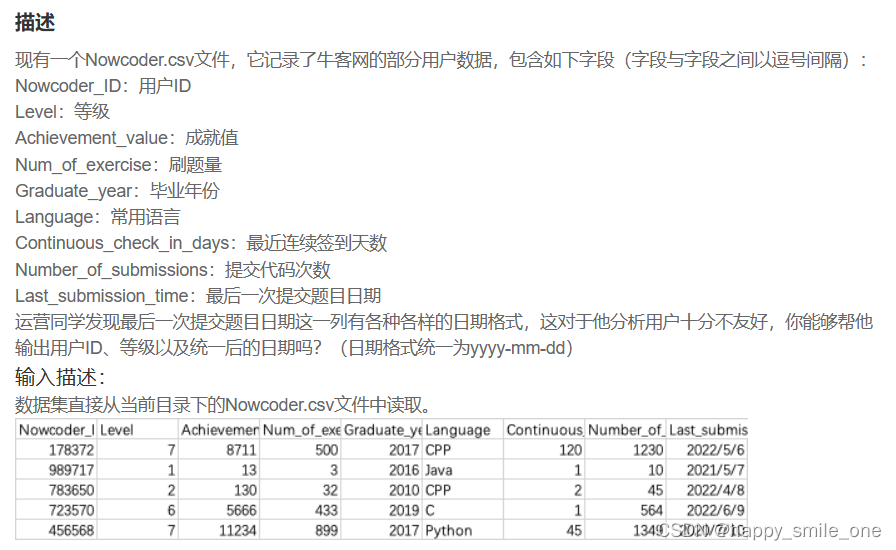
Pandas 清洗格式错误数据
数据格式错误的单元格会使数据分析变得困难,甚至不可能。
我们可以通过包含空单元格的行,或者将列中的所有单元格转换为相同格式的数据
import pandas as pd
df=pd.read_csv('Nowcoder.csv',sep=',',dtype=object) #必须添加dtype
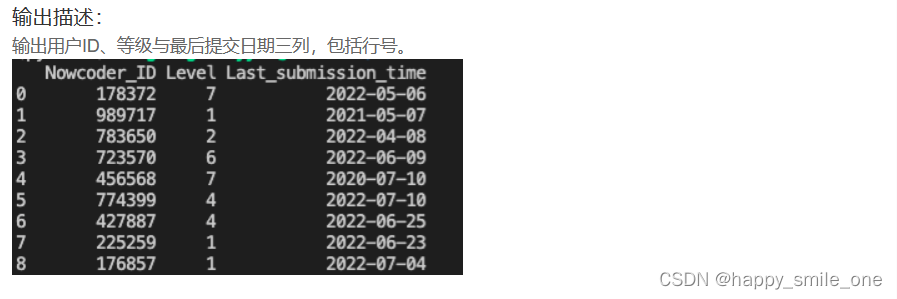
df['Last_submission_time'] = pd.to_datetime(df['Last_submission_time'],format='%Y-%m-%d') #注意格式化
print(df[['Nowcoder_ID','Level','Last_submission_time']]) #注意输出形式
六、Json处理
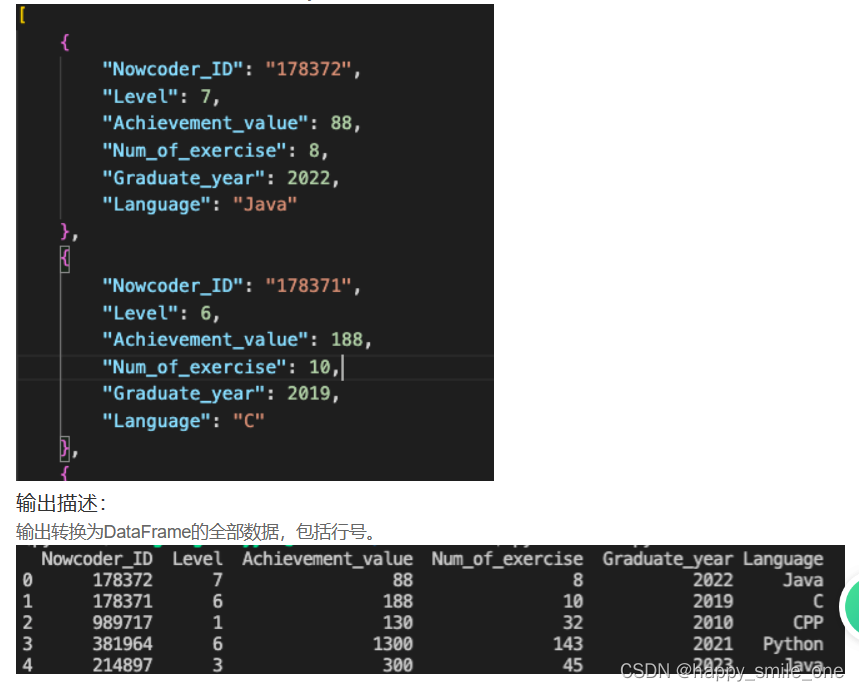
DA28 将用户的json文件转换为表格形式

import pandas as pd
pd.set_option("display.width", 300) # 设置字符显示宽度
pd.set_option("display.max_rows", None) # 设置显示最大行
pd.set_option("display.max_columns", None) # 设置显示最大列
df = pd.read_json("Nowcoder.json", dtype=False) #dtype=False
print(df)
dtype参数
指定列的数据类型.
该参数可以取True、False或者类似{‘column’:type}的字典来指定读取的数据的每一列的类型。
如果取True(默认取True)则函数自动判断每列的数据类型,纯数字的字符串会被识别为int类型。
如果取False则直接取原本的数据类型不会更改。
对于read_json函数,json文件有很多种方式指定index,columns以及values,如果不指定,则默认读取的json文件的方式为{columns->{index->values} 或 {columns->[values]}(此时index默认0123…) ,指定读取方式的参数为orient
七、分组聚合
DA29 牛客网的每日练题量

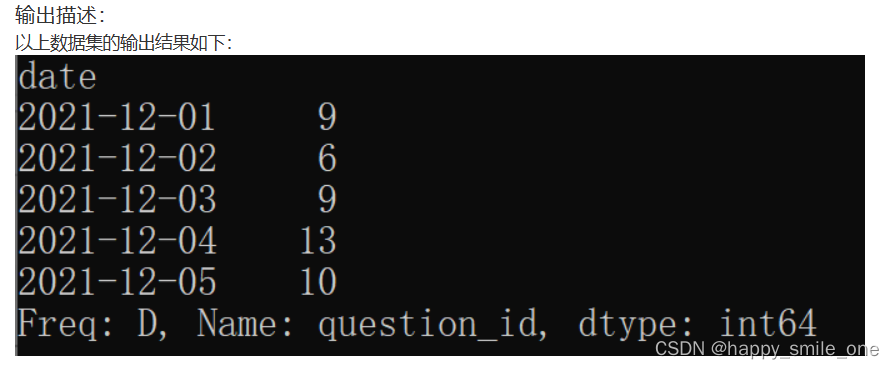
import pandas as pd
import datetime as dt
df = pd.read_csv("nowcoder.csv")
# 将date转换为日期格式
df["date"] = pd.to_datetime(df["date"]).dt.date
# 筛选统计区间 2021年12月
data = df[(df["date"] >= dt.date(2021, 12, 1)) & (df["date"] <= dt.date(2021, 12, 31))]
daily_num = df.groupby("date")["question_id"].count()
print(daily_num)
DA30 牛客网用户练习的平均次日留存率

import pandas as pd
from datetime import timedelta
df=pd.read_csv('nowcoder.csv')
#日期
df['date']=pd.to_datetime(df['date']).dt.date
#去重
df.drop_duplicates(subset=['user_id','date'],inplace=True)
#merge实现左右连
new_df=pd.merge(df,df,on='user_id',how='inner',suffixes=['_a','_b'])
#on和how的参数都是带引号的,还可以指定相同列的下标,不指定默认是_x,_y
new_df['diff']=new_df['date_b']-new_df['date_a']
#两个时间之差的数据类型就是timedelta类型
result=new_df[new_df['diff']==timedelta(days=1)]['diff'].count()/new_df[new_df['diff']==timedelta(days=0)]['diff'].count()
print(round(result,2))
DA31 牛客网每日正确与错误的答题次数
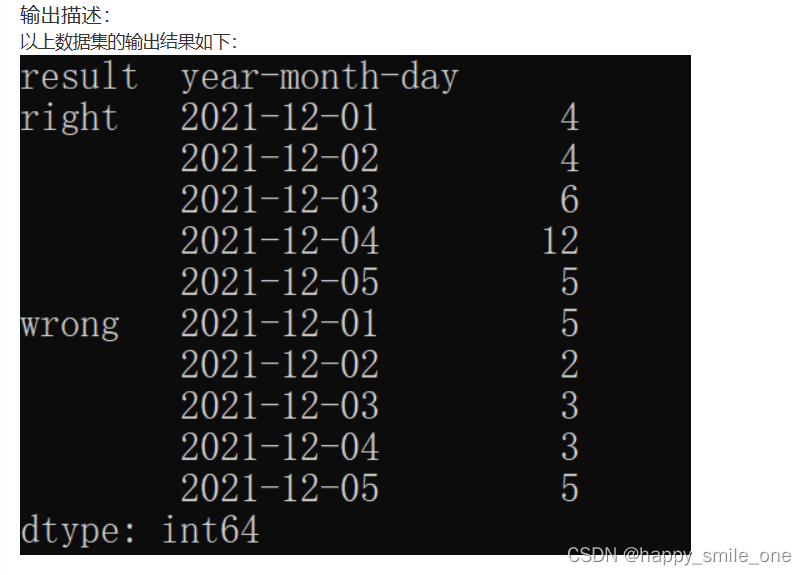
import pandas as pd
df=pd.read_csv('nowcoder.csv')
#首先过一次筛选,新建一列year-month-day
#然后选取日期前半部分并将str再转换成日期格式
df['year-month-day']=pd.to_datetime(df.date.str[:10])
#然后用groupby函数对result和year-month-day列进行分组
#并在最后计数时选择用question_id
answer=df.groupby(['result','year-month-day']).count().question_id
print(answer)
DA32 牛客网答题正误总数
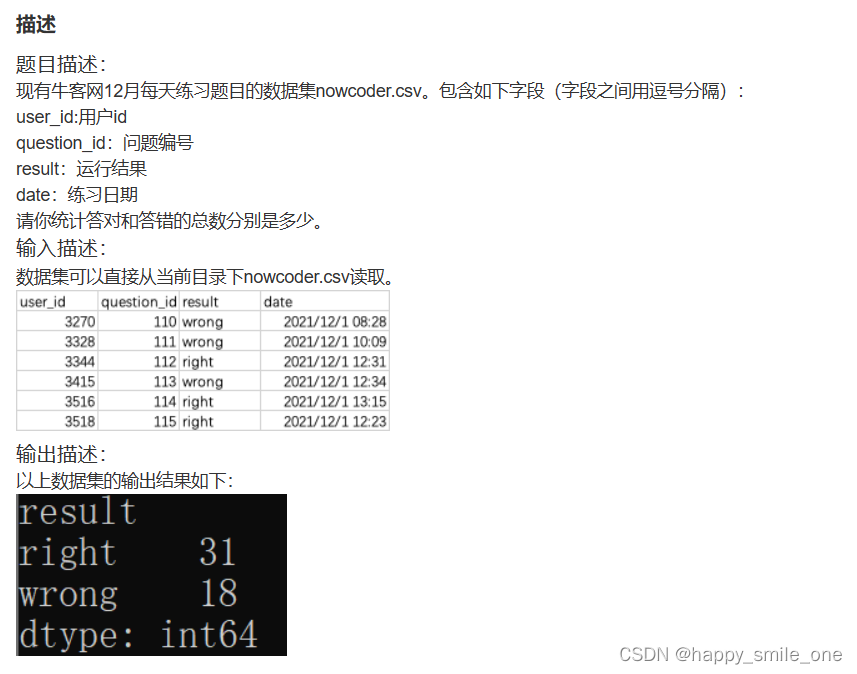
import pandas as pd
df=pd.read_csv('nowcoder.csv')
result_df=df.groupby('result')
print(result_df.size())
DA33 牛客网连续练习题目3天及以上的用户
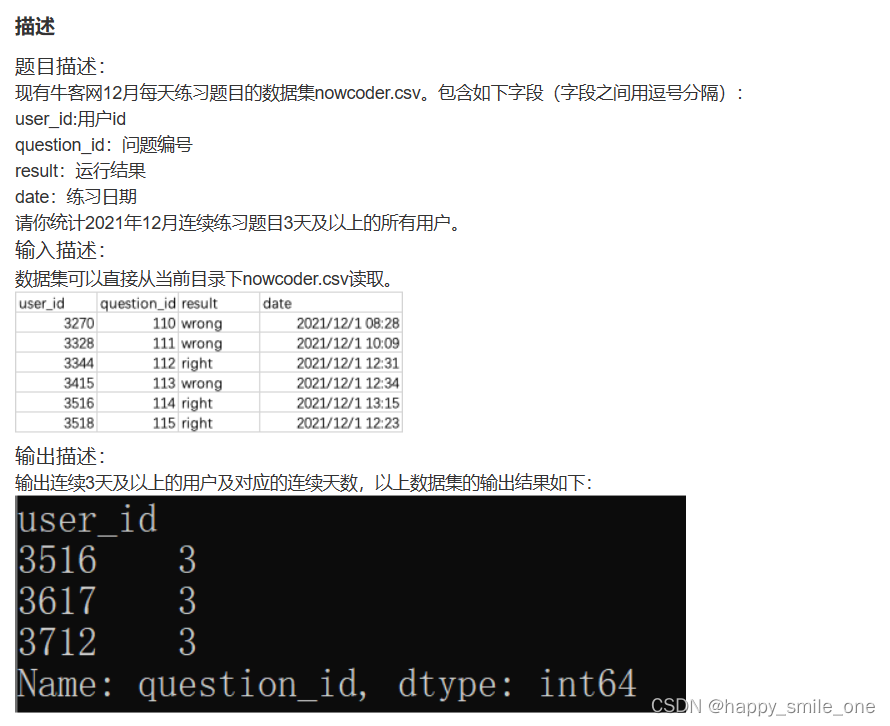
import pandas as pd
from datetime import timedelta
df=pd.read_csv('nowcoder.csv')
#先转时间
df['date']=pd.to_datetime(df['date'])
#先提取年月
df['date1']=df['date'].dt.strftime("%Y-%m")
data=df[df['date1']=='2021-12']
#再获取年月日
data['date2']=pd.to_datetime(data['date'].dt.date)
#根据日排序
data['rk']=pd.to_timedelta(data.groupby(['user_id']).date2.rank(),unit='d')
#作差并获取出现次数最多的值,SQL思路
data['cha']=data['date2']-data['rk']
data1=data.groupby(['user_id','cha']).count().groupby('user_id').rk.max()
print(data1[data1>=3])
DA34 牛客网不同毕业年份的大佬
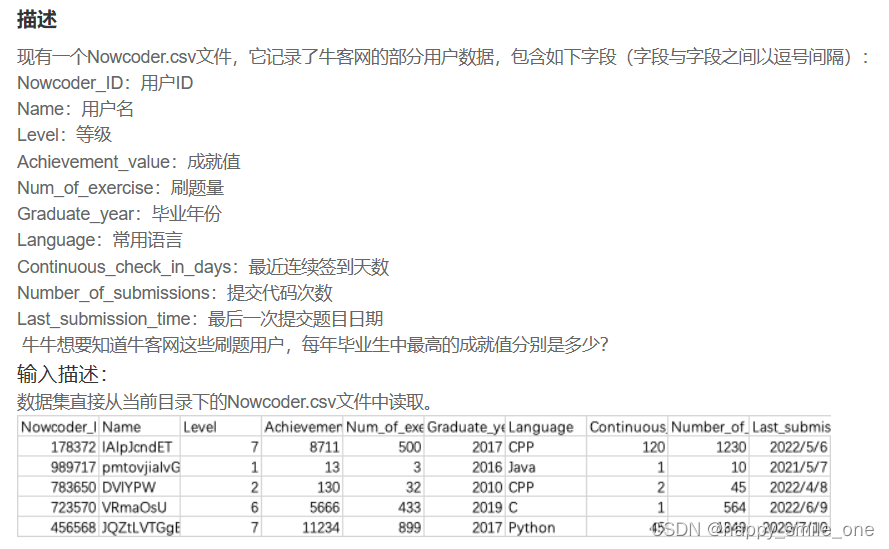

import pandas as pd
df=pd.read_csv('Nowcoder.csv')
result=df.groupby('Graduate_year') #按照毕业年份分组
print(result['Achievement_value'].max()) #输出分组中成就最大值
DA35 不同等级用户语言使用情况
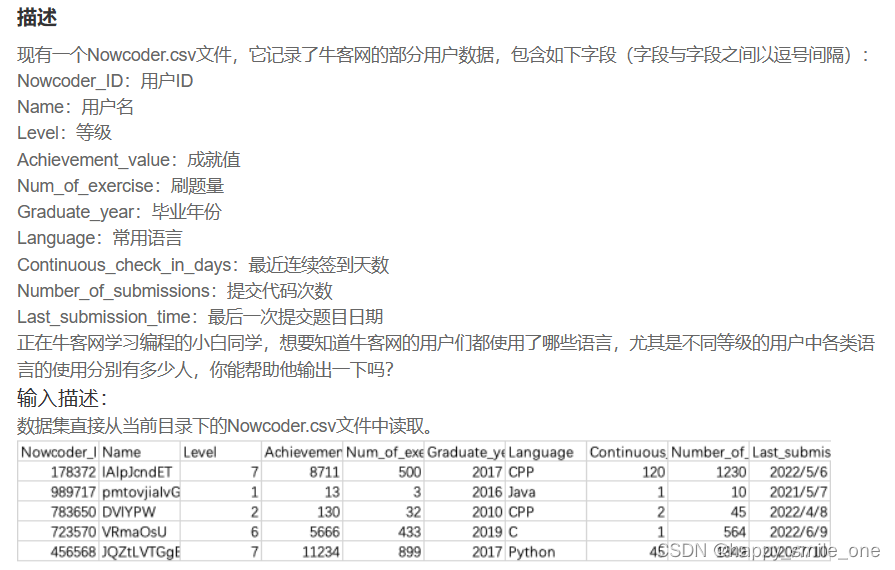
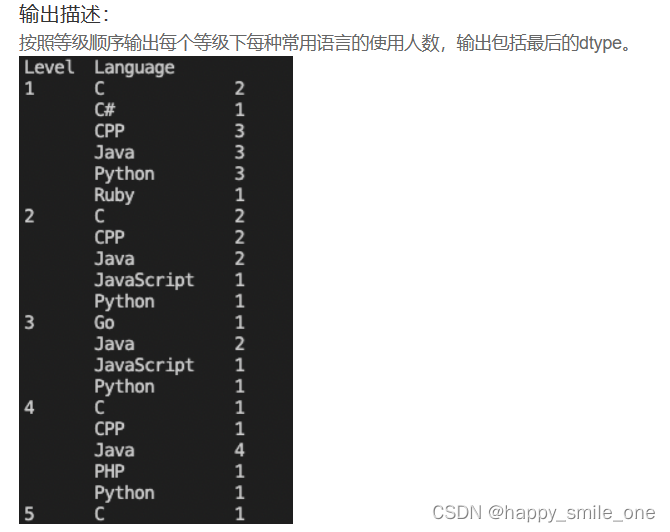
import pandas as pd
df=pd.read_csv('Nowcoder.csv')
result=df.groupby('Level') #以等级分组
print(result['Language'].value_counts()) #value_counts()计算各类语言的数量
DA36 总人数超过5的等级
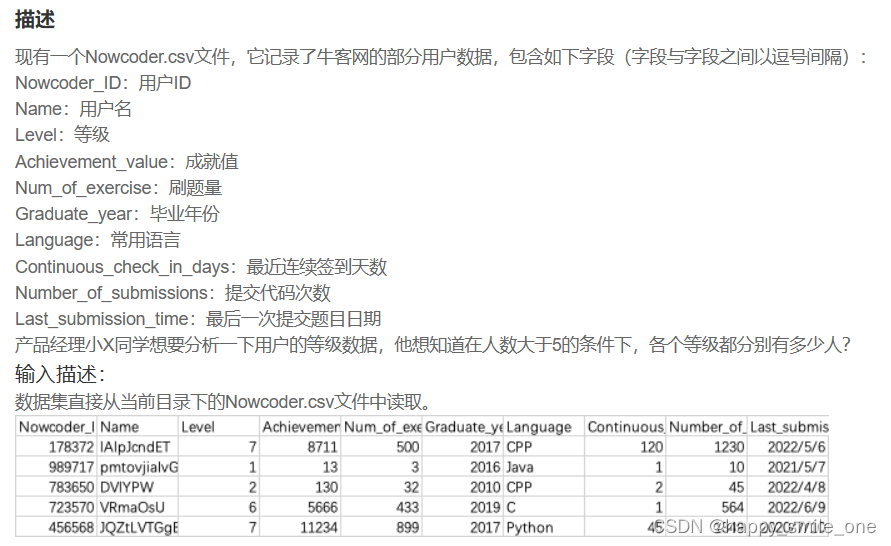

import pandas as pd
df=pd.read_csv('Nowcoder.csv')
#方法一
# result=df.groupby('Level')
# print(result.size()>5)
#方法二
result=df.groupby('Level').size()
print(result[result>5])
这个题系统有bug吧,方法一也判对。
八、合并
DA37 统计运动会项目报名人数
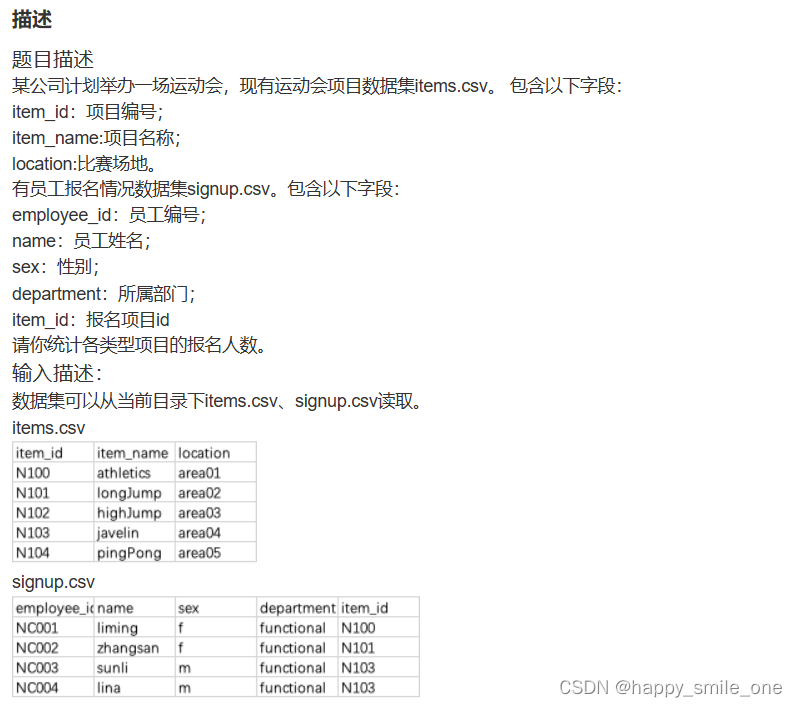

import pandas as pd
project=pd.read_csv('items.csv')
people=pd.read_csv('signup.csv')
df = pd.merge(project,people, on='item_id')
merge=df.groupby('item_name')['employee_id'].nunique()
print(merge[merge>0])
unique()方法返回的是去重之后的不同值,而nunique()方法则直接放回不同值的个数
nunique()可以通过参数dropna来自定义设置在统计不同值过程中是否需要包含None值,而unique()方法中没有可设置的参数,该方法在统计时无法排除None值。
DA38 统计运动会项目报名人数(二)


import pandas as pd
project = pd.read_csv("items.csv")
people = pd.read_csv("signup.csv")
df = pd.merge(project, people, on="item_id")
merge = df.groupby("item_name")["employee_id"].nunique()
print(merge)
DA39 多报名表的运动项目人数统计

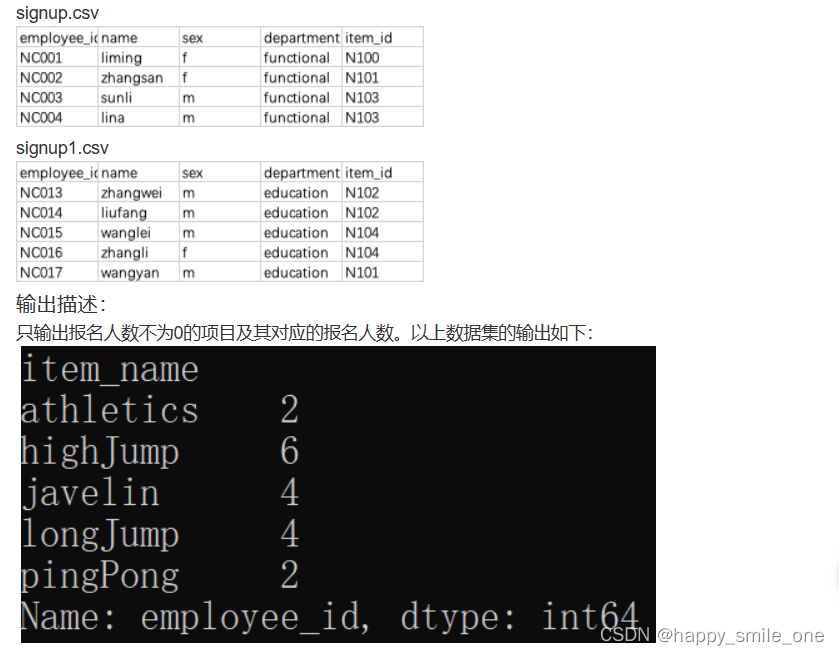
import pandas as pd
project = pd.read_csv("items.csv")
people1 = pd.read_csv("signup.csv")
people2 = pd.read_csv("signup1.csv")
df = pd.concat([people1, people2])#将多个数据框按照行或列进行合并
new_df = pd.merge(project,df, on="item_id")
#以项目名称分组,并计算分组中的人数
merge = new_df.groupby("item_name")["employee_id"].nunique()
#输出报名人数不为0的项目及其对应的报名人数
print(merge>0)
DA40 统计职能部分运动会某项目的报名信息


import pandas as pd
project = pd.read_csv("items.csv")
people = pd.read_csv("signup.csv")
# 连接两个表
df = pd.merge(project, people, on="item_id")
# 限定同时满足两个条件
new_df = df[(df["department"] == "functional") & (df["item_name"] == "javelin")]
print(new_df[['employee_id','name','sex']].reset_index(drop=True))
# 注意重置索引
# reset_index用来重置索引,因为有时候对dataframe做处理后索引可能是乱的。
# drop=True就是把原来的索引index列去掉,重置index。
# drop=False就是保留原来的索引,添加重置的index。
# 两者的区别就是有没有把原来的index去掉
DA41 运动会各项目报名透视表

import pandas as pd
project = pd.read_csv("items.csv")
people = pd.read_csv("signup.csv")
# 连接两个表
df = pd.merge(project, people, on="item_id")
table=pd.pivot_table(
df,
index=["sex", "department"],
columns=["item_name"],#列索引
values=["employee_id"],#相当于sql里的聚合函数操作的列,放在聚合函数里的列
aggfunc="count", #对values作不同的聚合
fill_value=0, #填充NAN
)
print(table)
aggfunc
相当于sql里的聚合函数,如果不指明,默认求平均.可以接受列表,即对values作不同的聚合,也可以接受字典,即对不同的values作不同的操作,也可以将字典里的值改为列表形式的,即对某列作几种不同的操作.切记,对于aggfunc,操作的是values后面的值,而不是columns后面的值.
DA42 合并用户信息表与用户活跃表

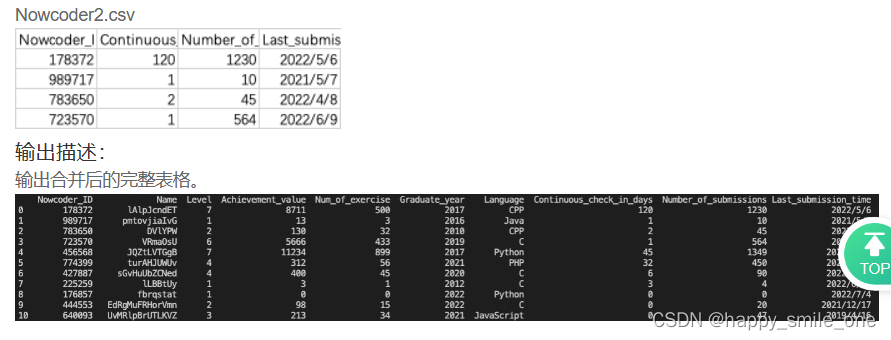
import pandas as pd
people1 = pd.read_csv("Nowcoder1.csv", sep=",")
people2 = pd.read_csv("Nowcoder2.csv", sep=",")
#使用merge方法合并数据框时,也可以使用参数how=’outer’来去除重复的数据。
df = pd.merge(people1, people2, on="Nowcoder_ID", how="outer").drop_duplicates()
#完整显示表格
pd.set_option("display.width", 300) # 设置字符显示宽度
pd.set_option("display.max_rows", None) # 设置显示最大行
pd.set_option("display.max_columns", None)
print(df)
DA43 两份用户信息表格中的查找

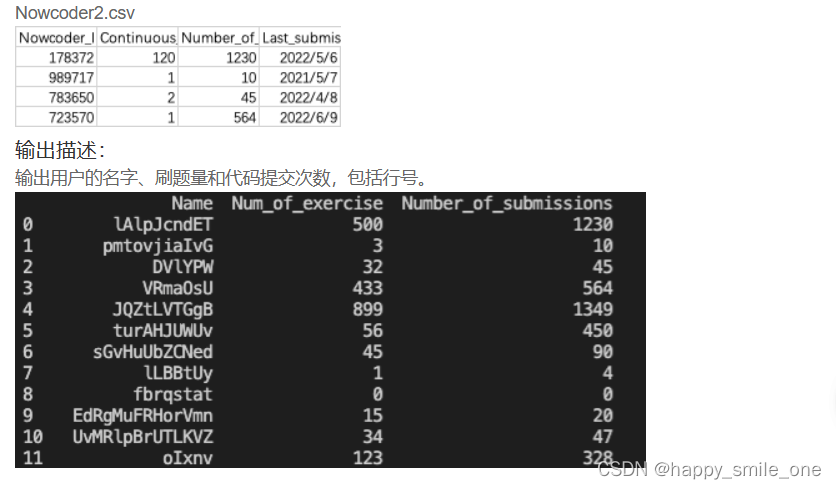
import pandas as pd
people1 = pd.read_csv("Nowcoder1.csv", sep=",")
people2 = pd.read_csv("Nowcoder2.csv", sep=",")
# 使用merge方法合并数据框时,也可以使用参数how=’outer’来去除重复的数据。
df = pd.merge(people1, people2, on="Nowcoder_ID", how="outer").drop_duplicates()
print(df[['Name','Num_of_exercise','Number_of_submissions']].reset_index(drop=True)) #reset_index重新编号
九、排序
DA44 某店铺消费最多的前三名用户
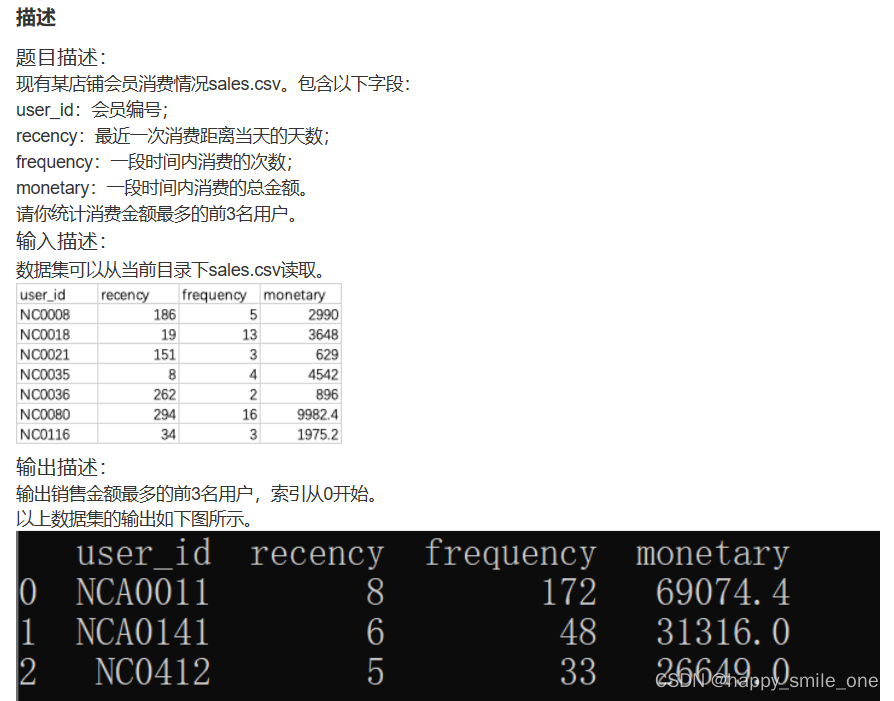
import pandas as pd
df=pd.read_csv('sales.csv')
new_df=df.sort_values(by='monetary', ascending=False)
print(new_df.head(3).reset_index(drop=True))
对于值排名,使用函数df.sort_values(by= , axix=,ascending= , inplace=,na_postion=)。
注意: by参数指定要排序的列,
axis=0表示按照行进行排名,axis=1表示按照列进行排名,默认0;
ascending=True表示升序,ascending=False表示降序,默认True.
inplace 代表是否要更改原数据,true代表修改原数据。false代表新建副本,在副本修改
na_position参数用于设定缺失值的显示位置,first表示缺失值显示在最前面,last表示缺失值显示在最后面
reset_index用来重置索引,因为有时候对dataframe做处理后索引可能是乱的。
drop=True就是把原来的索引index列去掉,重置index。
drop=False就是保留原来的索引,添加重置的index。
DA45 按照等级递增序查看牛客网用户信息
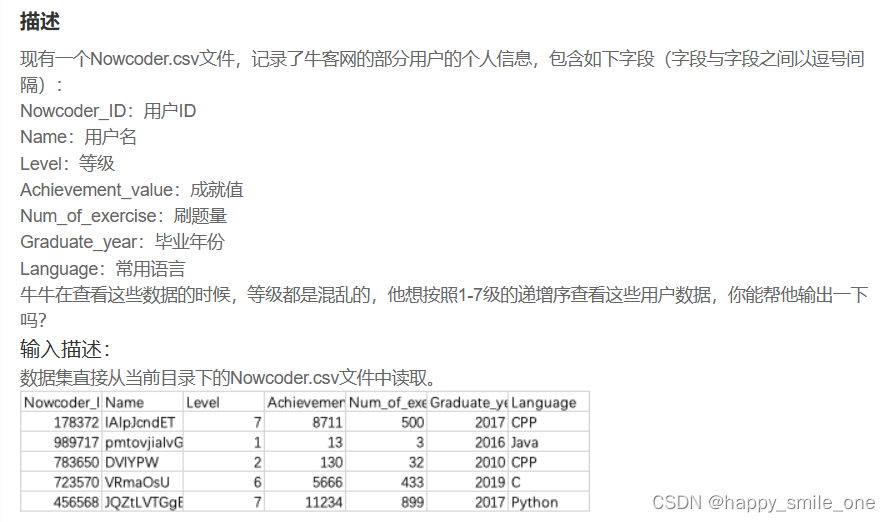
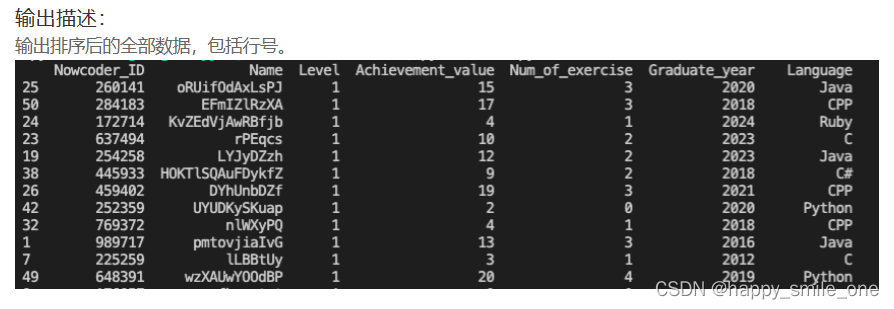
import pandas as pd
df = pd.read_csv("Nowcoder.csv")
new_df = df.sort_values(by="Level") # 默认升序
# 完整显示表格
pd.set_option("display.width", 300) # 设置字符显示宽度
pd.set_option("display.max_rows", None) # 设置显示最大行
pd.set_option("display.max_columns", None)
print(new_df)
十、函数
DA46 某店铺用户消费特征评分


#定义函数
def get_score(x, df, col, is_big_better=True):
q1 = df[col].quantile(0.25) # 上四分位数
q2 = df[col].median() # 中位数
q3 = df[col].quantile(0.75) # 下四分位数
if is_big_better == True:
if x <= q1:
return 1
elif q1 < x <= q2:
return 2
elif q2 < x <= q3:
return 3
elif x > q3:
return 4
else:
if x <= q1:
return 4
elif q1 < x <= q2:
return 3
elif q2 < x <= q3:
return 2
elif x > q3:
return 1
import pandas as pd
sales = pd.read_csv("sales.csv")
sales["R_Quartile"] = sales["recency"].apply(
lambda x0: get_score(x0, sales, "recency", is_big_better=False)
)
sales["F_Quartile"] = sales["frequency"].apply(
lambda x0: get_score(x0, sales, "frequency")
)
sales["M_Quartile"] = sales["monetary"].apply(
lambda x0: get_score(x0, sales, "monetary")
)
print(sales.head(5))
apply() 使用时,通常放入一个 lambda 函数表达式、或一个函数作为操作运算,官方上给出的 apply() 用法:
DataFrame.apply(self, func, axis=0, raw=False, result_type=None, args=(), **kwds
func 代表的是传入的函数或 lambda 表达式;
axis 参数可提供的有两个,该参数默认为0/列
0 或者 index ,表示函数处理的是每一列;
1 或 columns ,表示处理的是每一行;
raw ;bool 类型,默认为 False;
False ,表示把每一行或列作为 Series 传入函数中;
True,表示接受的是 ndarray 数据类型;
DA47 筛选某店铺最有价值用户中消费最多前5名

# 定义函数
def get_score(x, df, col, is_big_better=True):
q1 = df[col].quantile(0.25) # 上四分位数
q2 = df[col].median() # 中位数
q3 = df[col].quantile(0.75) # 下四分位数
if is_big_better == True:
if x <= q1:
return 1
elif q1 < x <= q2:
return 2
elif q2 < x <= q3:
return 3
elif x > q3:
return 4
else:
if x <= q1:
return 4
elif q1 < x <= q2:
return 3
elif q2 < x <= q3:
return 2
elif x > q3:
return 1
import pandas as pd
sales = pd.read_csv("sales.csv")
sales["R_Quartile"] = sales["recency"].apply(
lambda x0: get_score(x0, sales, "recency", is_big_better=False)
)
sales["F_Quartile"] = sales["frequency"].apply(
lambda x0: get_score(x0, sales, "frequency")
)
sales["M_Quartile"] = sales["monetary"].apply(
lambda x0: get_score(x0, sales, "monetary")
)
sales["RFMClass"] = (
sales["R_Quartile"].map(str)
+ sales["F_Quartile"].map(str)
+ sales["M_Quartile"].map(str)
)
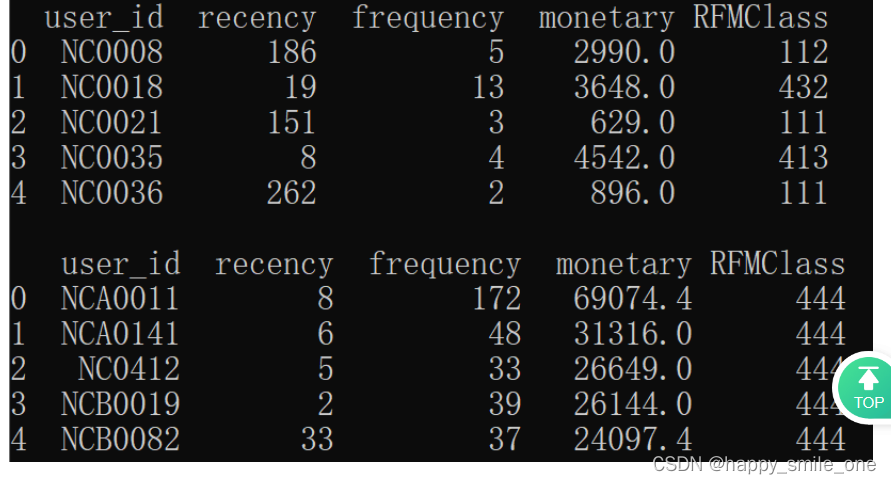
print(sales.head(5).loc[:, ["user_id", "recency", "frequency", "monetary", "RFMClass"]]) #输出评分数据前5行
print()
#输出最有价值的用户(评分为“444”)中销售总金额最高的前5位(索引从0开始)
new_sales=sales.query("RFMClass == '444'").sort_values("monetary", ascending=False).head(5).loc[:, ["user_id", "recency", "frequency", "monetary", "RFMClass"]]
print(new_sales.reset_index(drop=True)) #索引从0开始
总结
自己没有系统的学过数据分析,更多的都是参考题解完成。其中标星和斜体,都代表注需要重点回顾的题。
有些知识点按照三级目录展现。















 3540
3540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









