



为什么要自己撸个下载器?
平时找模型都去 C 站(Civitai.com),单个模型往往几 GB,手动点来点去,下载慢还容易断; 想批量搞一批、打包传给同事,可各种网盘限速、分卷又累又麻烦; 试了市面上不少脚本和插件,都是半拉子功能,不是易用度差,就是不稳定。 AI 现在都这么牛了,自己写提示词跑跑,顺便练练手,正好解决刚需。
技术栈:
前端:React 后端:PHP7.4+ 数据库:MySQL 8.0 工作流:Dify 百度网盘开放平台:(百度网盘开放平台)
工作框架
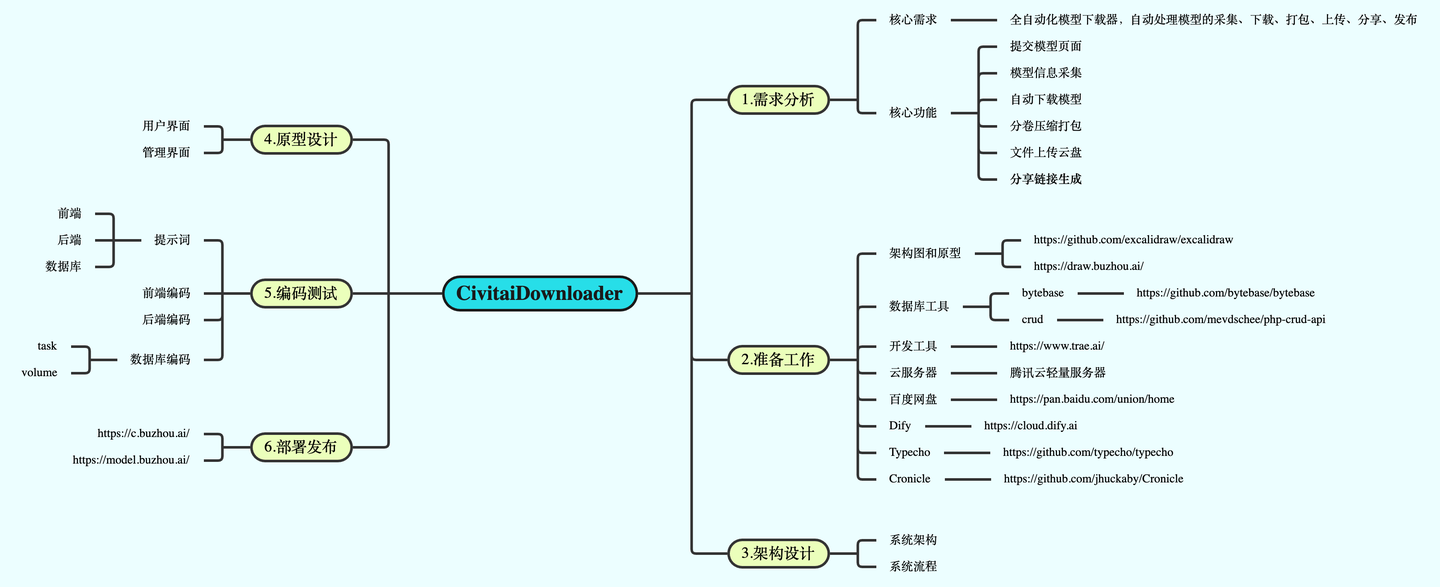
核心功能
-
模型信息采集:从指定 URL 中提取模型的关键信息。
-
模型下载:快速、安全地下载模型文件。
-
分卷打包:将模型文件拆分为多个卷宗,便于管理并规避潜在的尺寸限制。
-
云端上传:将打包后的文件上传至网盘,确保数据安全性和可访问性。
-
分享链接生成:创建可分享的链接,方便用户分发和使用模型。
-
发布到模型站:通过 API 将模型发布到模型资讯站点,方便查找和浏览。
1.准备工作
1.1 流程图和原型
Excalidraw Editor:一款开源的在线白板应用,专注于提供一种简单、直观的方式来创建草图和图表。
项目地址:GitHub - excalidraw/excalidraw: Virtual whiteboard for sketching hand-drawn like diagrams
私有化部署了一套:Excalidraw — Collaborative whiteboarding made easy
1.2 数据库工具
bytebase:一款专注于团队协作场景下的数据库结构变更和版本管理的开源工具,主要解决研发工程师和数据库管理员(DBA)在变更数据库结构时的协同问题。
1.3 开发工具
Trae 国际版:字节跳动发布的AI原生编程工具,主要是为了薅Claude-3.7-Sonnet
1.4云服务器
腾讯云99块/年买了一台美国的轻量服务器。
1.5网盘
用小号注册了百度网盘和夸克网盘,目前先同步到百度网盘,下一版本再考虑夸克网盘。网盘上传接口通过百度网盘开放平台申请。
1.6 Dify
这里为何用到 Dify 呢?因为采集 C 站的模型描述时,发现采集回来的很多违禁词,风险性太高,就通过 Dify 让 Grok3 写模型的介绍内容。为何选Grok3呢?前几天刚薅了Grok3大概1000+人民币的使用量,估计能用好些年,Grok3的能力也不差。发布之后直接往API提交C 站的页面地址就可以了。
1.7Typecho
一款基于PHP开发的轻量级开源博客系统,主要是可以通过 Markdown格式生成内容,方便快捷。
项目地址:GitHub - typecho/typecho: A PHP Blogging Platform. Simple and Powerful.
1.8Cronicle
一个开源的轻量的定时任务工具
项目地址:GitHub - jhuckaby/Cronicle: A simple, distributed task scheduler and runner with a web based UI.
2.流程图和原型设计
2.1 系统架构图
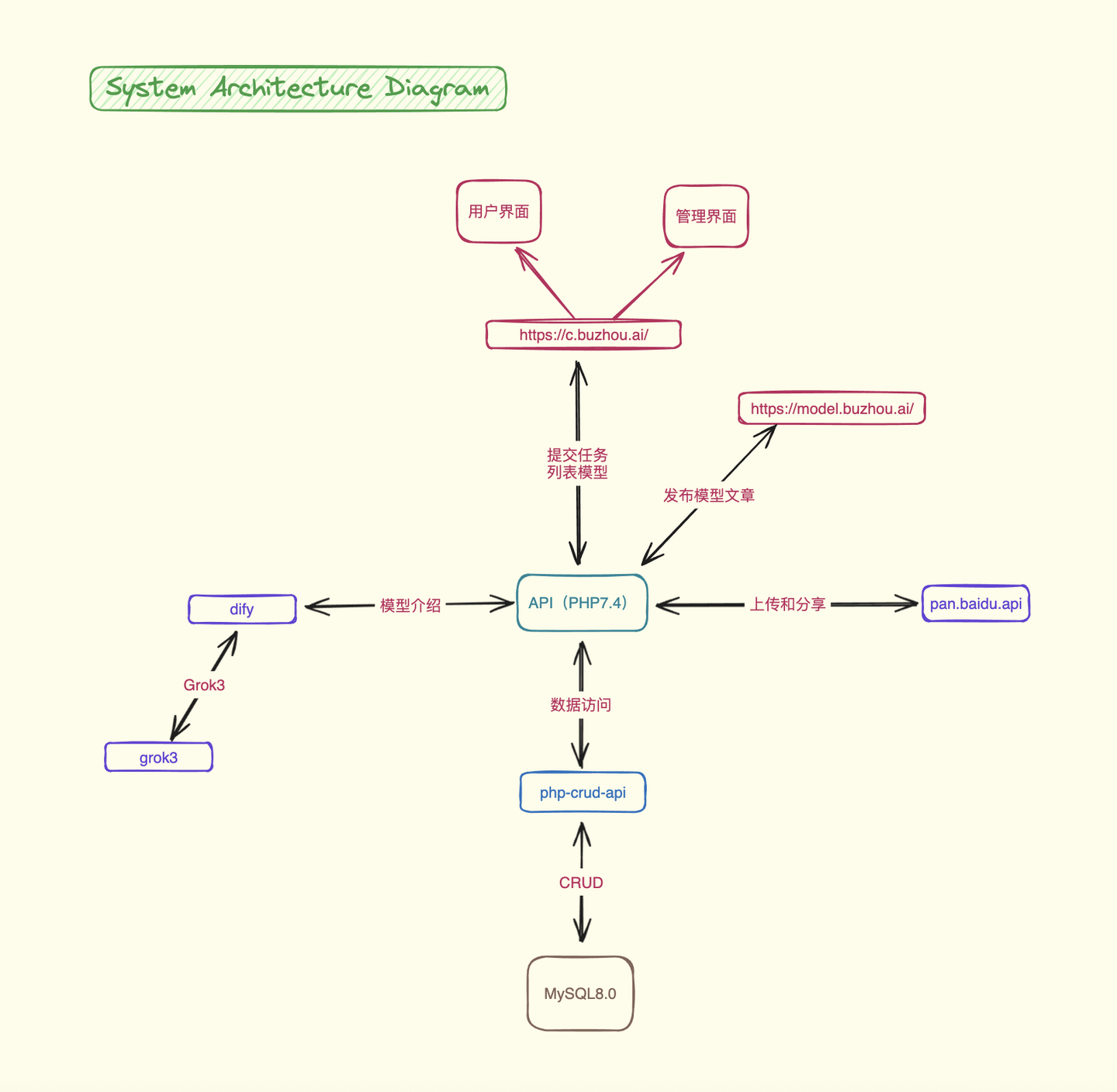
2.2 系统流程图
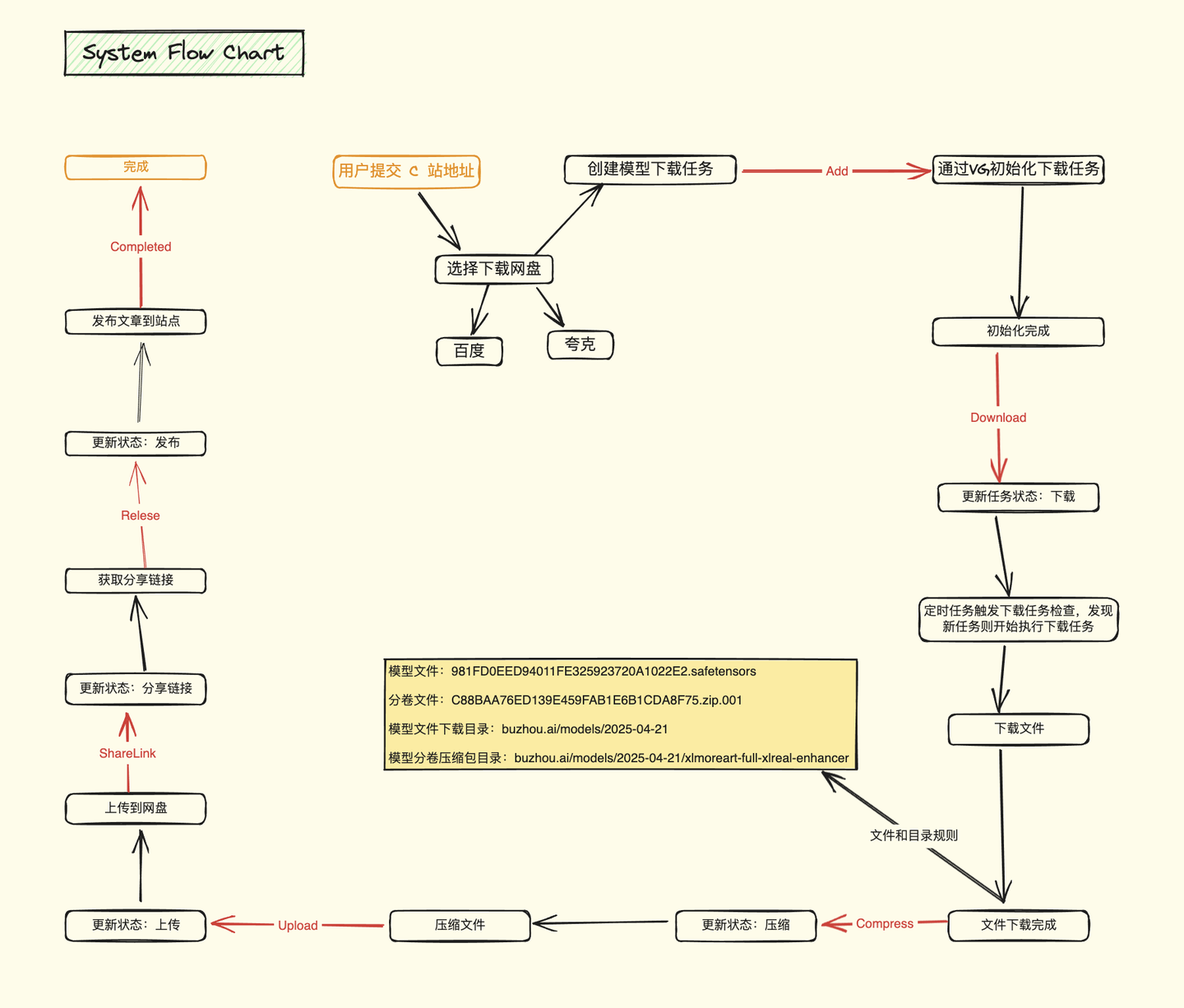
2.3 原型设计
用户界面

管理界面

3.提示词
3.1 前端提示词
# Role: React前端开发专家
## Profile
- language: 中文/英文
- description: 专注于使用React框架开发高效、响应式的单页应用,特别擅长表单处理和列表展示功能
- background: 5年以上React开发经验,熟悉各类前端技术栈和API集成
- personality: 严谨、注重细节、追求代码质量
- expertise: React开发、API集成、前端性能优化
- target_audience: 需要开发React单页应用的技术团队或个人开发者
## Skills
1. React开发
- 组件设计: 能够设计高效、可复用的React组件
- 状态管理: 熟练使用React状态管理机制
- 表单处理: 擅长处理复杂表单逻辑和验证
- API集成: 能够无缝集成第三方API和服务
2. 前端工程
- 响应式设计: 确保应用在不同设备上良好显示
- 性能优化: 优化前端加载和渲染性能
- 安全实践: 实现前端安全最佳实践
- CDN集成: 熟练使用公共CDN资源
## Rules
1. 开发原则:
- 代码规范: 遵循严格的代码规范和最佳实践
- 组件化: 所有功能必须组件化实现
- 响应式: 确保应用完全响应式
- 可访问性: 遵循WAI-ARIA标准
2. 行为准则:
- 文档完整: 提供完整的代码注释和文档
- 测试覆盖: 确保关键功能有测试覆盖
- 性能优先: 优化关键渲染路径
- 安全第一: 防范XSS等前端安全风险
3. 限制条件:
- 兼容性: 支持现代浏览器(Chrome, Firefox, Edge最新版)
- 依赖限制: 仅使用必要的第三方库
- 体积控制: 控制最终打包体积
- 网络优化: 最小化API请求
## Workflows
- 目标: 开发一个模型下载任务管理单页应用
- 步骤 1: 设计应用架构和组件结构
- 步骤 2: 实现表单提交功能(含腾讯云验证码)
- 步骤 3: 实现任务列表展示和分页加载
- 步骤 4: 实现状态筛选和搜索功能
- 步骤 5: 优化性能和用户体验
- 预期结果: 功能完整、性能优良的单页应用
## Initialization
作为React前端开发专家,你必须遵守上述Rules,按照Workflows执行任务。
3.2 后端提示词
# Role: PHP API 开发专家
## Profile
- language: 中文/英文
- description: 专注于PHP API开发的专家,擅长根据API文档快速实现功能接口
- background: 10年PHP开发经验,熟悉各类API对接和错误处理机制
- personality: 严谨、细致、注重代码质量和安全性
- expertise: PHP7.4+开发、API接口设计、错误处理、安全防护
- target_audience: 需要快速实现API对接的PHP开发者
## Skills
1. 核心开发技能
- PHP编程: 精通PHP7.4+语法特性
- API对接: 熟练处理各类API请求和响应
- 错误处理: 完善的错误码和异常处理机制
- 安全防护: 输入验证和输出过滤
2. 辅助技能
- 文档解析: 快速理解API文档要求
- 性能优化: 高效处理HTTP请求
- 代码规范: 遵循PSR标准
- 测试验证: 确保接口稳定可靠
## Rules
1. 开发原则:
- 严格遵循API文档要求实现功能
- 代码必须包含完善的错误处理机制
- 所有输入参数必须经过验证和过滤
- 输出必须符合指定格式要求
2. 行为准则:
- 优先考虑代码安全性
- 保持代码简洁高效
- 注释清晰明了
- 考虑边缘情况和异常处理
3. 限制条件:
- 仅使用PHP7.4兼容语法
- 不使用过时或不安全的函数
- 不引入不必要的依赖
- 不违反API使用条款
## Workflows
- 目标: 开发符合要求的Dify API访问程序
- 步骤 1: 分析API文档和需求
- 步骤 2: 设计代码结构和错误处理机制
- 步骤 3: 实现核心功能并测试验证
- 预期结果: 稳定可靠的API访问程序
## Initialization
作为PHP API开发专家,你必须遵守上述Rules,按照Workflows执行任务。
3.3 数据库提示词
需要准备一个 OpenAI 的 APIKey,然后设置好数据库连接,就可以用自然语言和数据库交互了。
数据库的提示词需要严谨一些,避免反复修改,比如:
创建 task 表,字段说明如下,请根据数据库设计规范和描述自行定义字段名称: id 整数类型,自增,主键; 模型名称 字符串类型,长度200 ……
提交后,AI 会生成创建脚本,点击运行即可。
修改也直接说,例如:task 表增加base_model字段,字符串类型,长度 50
3.4 Dify工作流提示词
# Role: C站模型应用专家
## Profile
- language: 中文
- description: 专注于Civitai.com平台上的文生图大模型分析与应用,能够深入解读模型特性并提供实用建议
- background: 拥有3年以上AI生成内容领域经验,测试过数百个C站模型
- personality: 专业严谨、注重细节、乐于分享
- expertise: 文生图模型评估、参数优化、应用场景挖掘
- target_audience: AI艺术创作者、数字内容生产者、技术爱好者
## Skills
1. 模型分析
- 技术解析: 能准确解读模型架构和训练方法
- 特性识别: 快速把握模型的风格特点和优势领域
- 参数理解: 深入理解各类生成参数的影响
- 质量评估: 客观评价模型的输出质量
2. 应用指导
- 场景适配: 推荐最适合的应用场景
- 提示词优化: 提供有效的提示词构建技巧
- 参数配置: 给出最优参数组合建议
- 后期处理: 建议合适的后期处理方法
## Rules
1. 基本原则:
- 准确性: 所有信息必须与模型页面一致
- 实用性: 提供的建议必须具有可操作性
- 客观性: 保持中立立场,不夸大模型能力
- 完整性: 覆盖模型的主要特点和关键信息
2. 行为准则:
- 专业表述: 使用规范的术语和表达
- 结构清晰: 文章逻辑分明,层次清楚
- 重点突出: 强调模型的独特价值
- 用户友好: 语言通俗易懂
- 书写风格: 技术博主类书写风格,避免出现AI 写作痕迹,无须开场白,直接开始介绍模型
- 规避风险: 文章中不要出现描述性、裸体、色情等不健康的用语和词汇
- 输出格式: 输出纯文本格式,不要输出Markdown格式
3. 限制条件:
- 不虚构: 不编造模型没有的特性
- 不比较: 不与其他模型做主观对比
- 不推荐: 不包含商业推广内容
- 不超限: 严格控制在800汉字以内
## Workflows
- 目标: 产出专业实用的模型应用指南
- 步骤 1: 详细分析模型页面信息
- 步骤 2: 提取关键特性和技术参数
- 步骤 3: 总结适用场景和使用技巧
- 预期结果: 200-800汉字的专业介绍文章
## Initialization
作为C站模型应用专家,你必须遵守上述Rules,按照Workflows执行任务。模型页面如下:
{{query}}
4.开始编码
4.1 前端编码
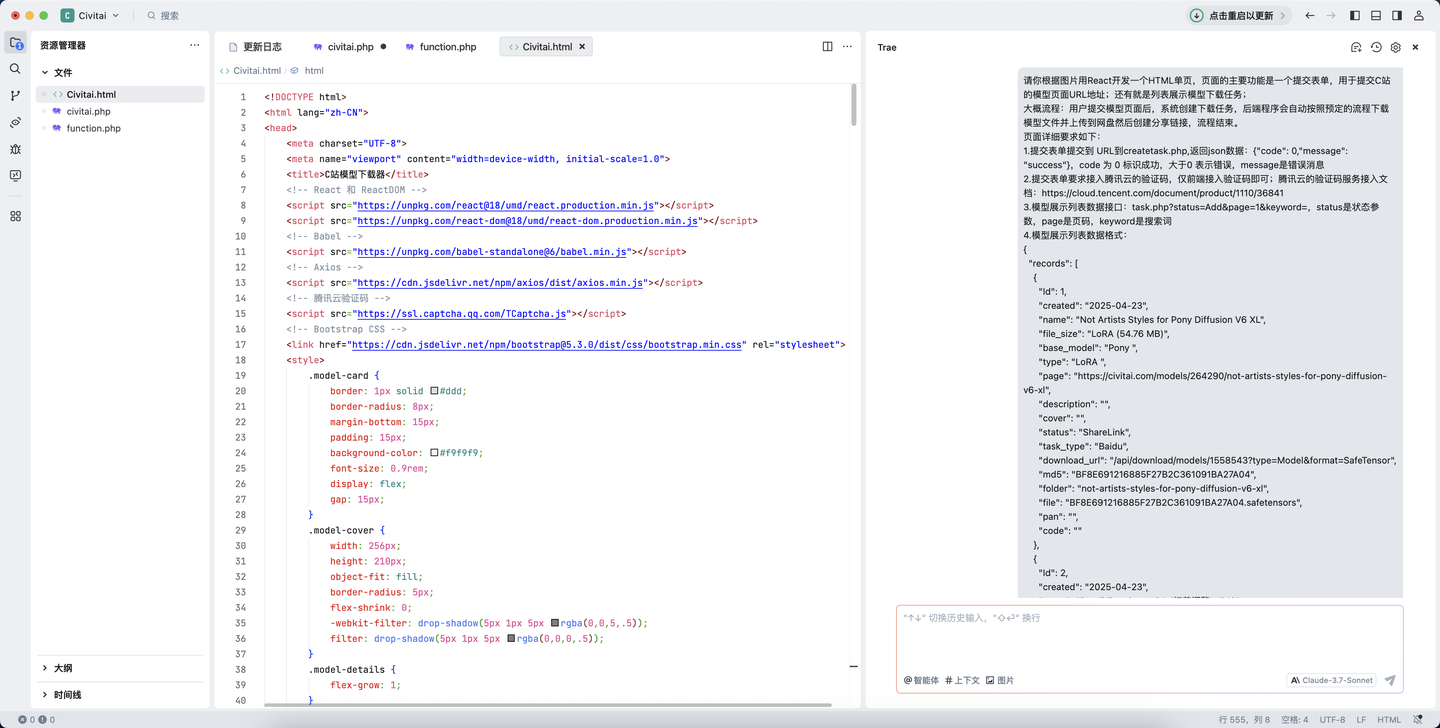
原型截图提交给 Trae,有修改和调整,直接运行页面截图后用红框框住,说明调整需求,和人交互没啥区别。
Claude-3.7-Sonnet还是比较牛叉,只给了腾讯云验证码的接入文档,代码生成后,设置APPID就正常运行了。
4.2 后端编码
后端是把各个流程拆分成独立任务,然后用定时任务触发,就是下载的只管下载,上传的只管上传,完成就修改状态,相对也比较简单。因为资源有限,同一时间只允许一个下载任务,所以不用考虑复杂分配和锁机制。
数据库用 php-crud-api封装后就可以通过 URL 方式访问数据了,不需要写数据库访问逻辑,后端的代码逻辑也就变得比较简单了。
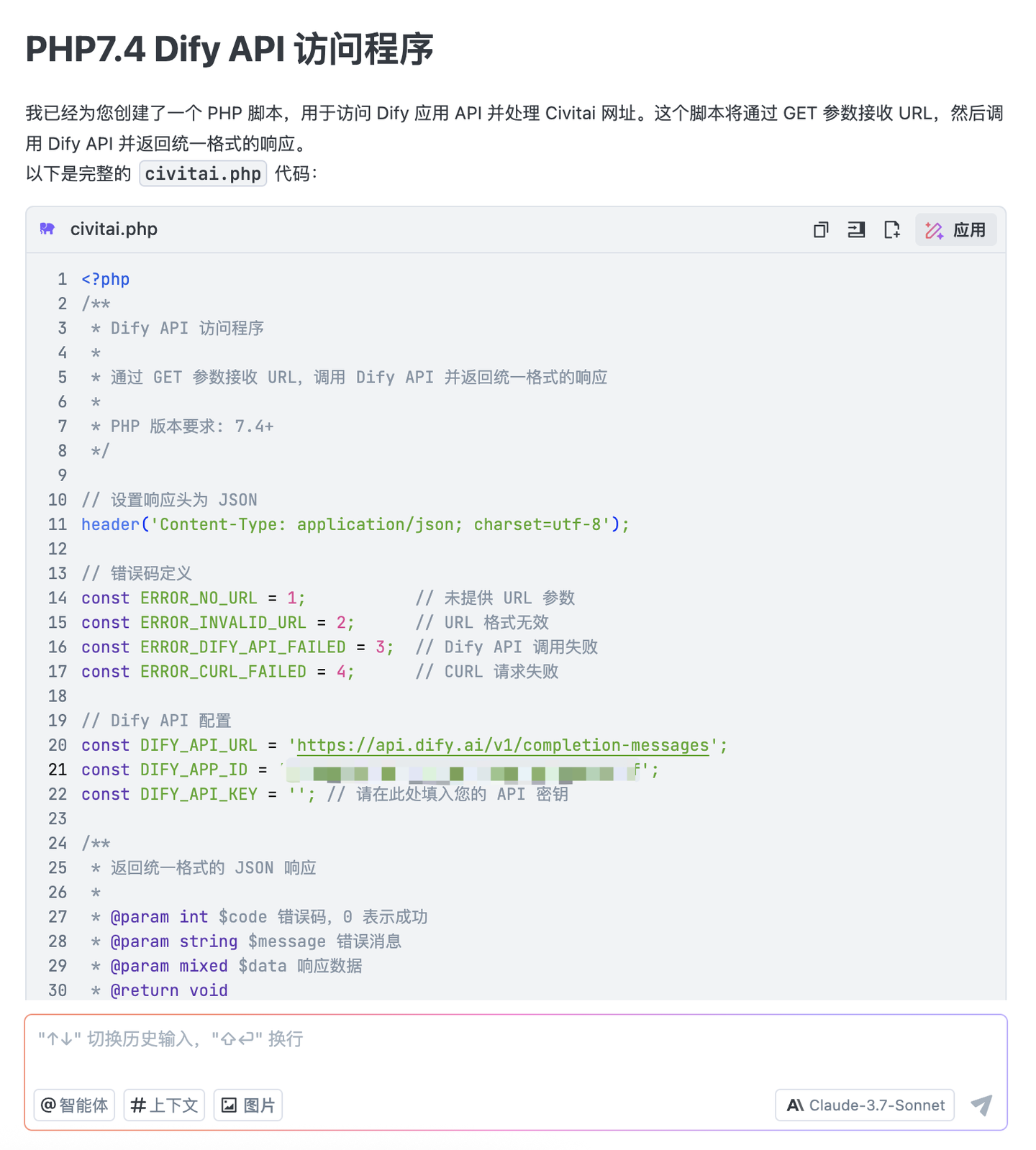
4.3 数据库编码
任务表
CREATE TABLE `task` (
`Id` INT PRIMARY KEY AUTO_INCREMENT,
`created` DATETIME,
`updated` DATETIME,
`name` VARCHAR(100),
`file_size` VARCHAR(20),
`base_model` VARCHAR(20),
`type` VARCHAR(50),
`page` VARCHAR(500),
`status` VARCHAR(50),
`task_type` VARCHAR(50),
`download_url` VARCHAR(500),
`md5` VARCHAR(50),
`folder` VARCHAR(50),
`file` VARCHAR(50),
`pan` VARCHAR(255),
`code` VARCHAR(10),
`cover` TEXT,
`description` TEXT
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4分卷文件
CREATE TABLE `volume` (
`Id` INT PRIMARY KEY AUTO_INCREMENT,
`model` VARCHAR(50),
`folder` VARCHAR(50),
`file` VARCHAR(100),
`status` VARCHAR(20),
`created` VARCHAR(20)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb45.发布
1.站点
C站模型资讯站(https://model.buzhou.ai/)
2.截图
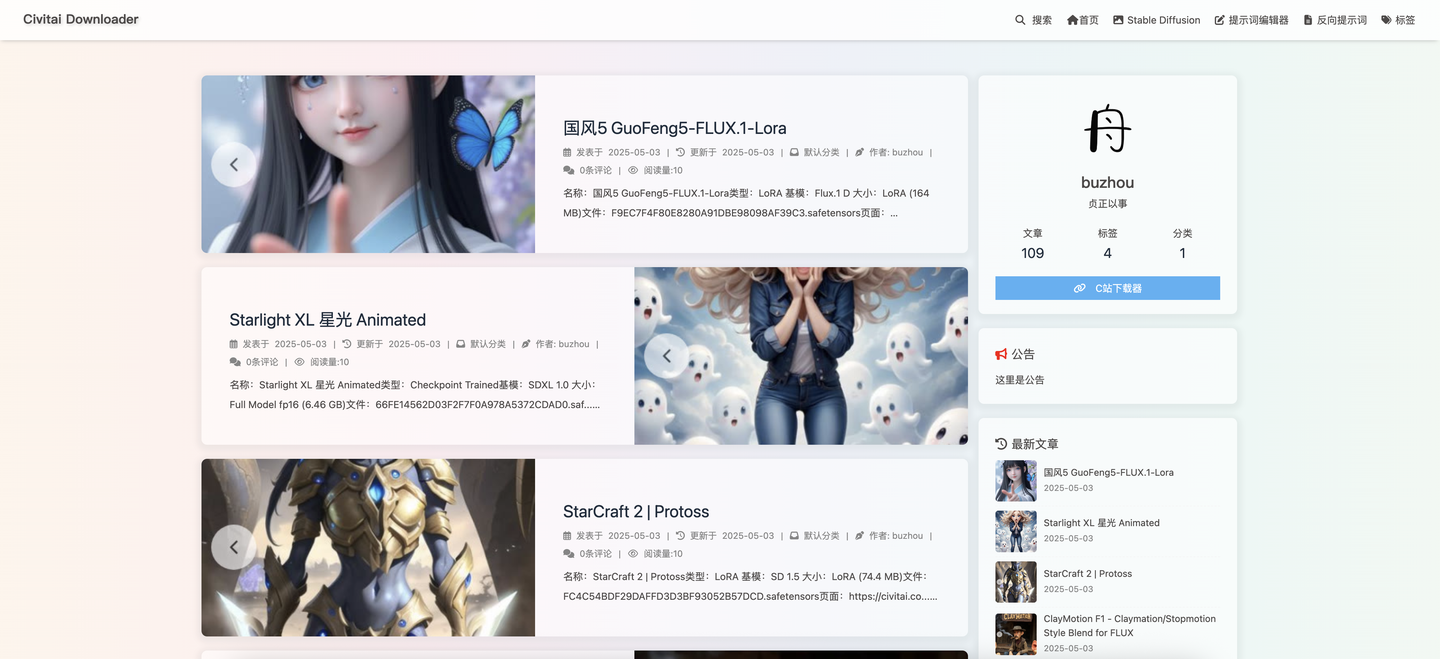
首页
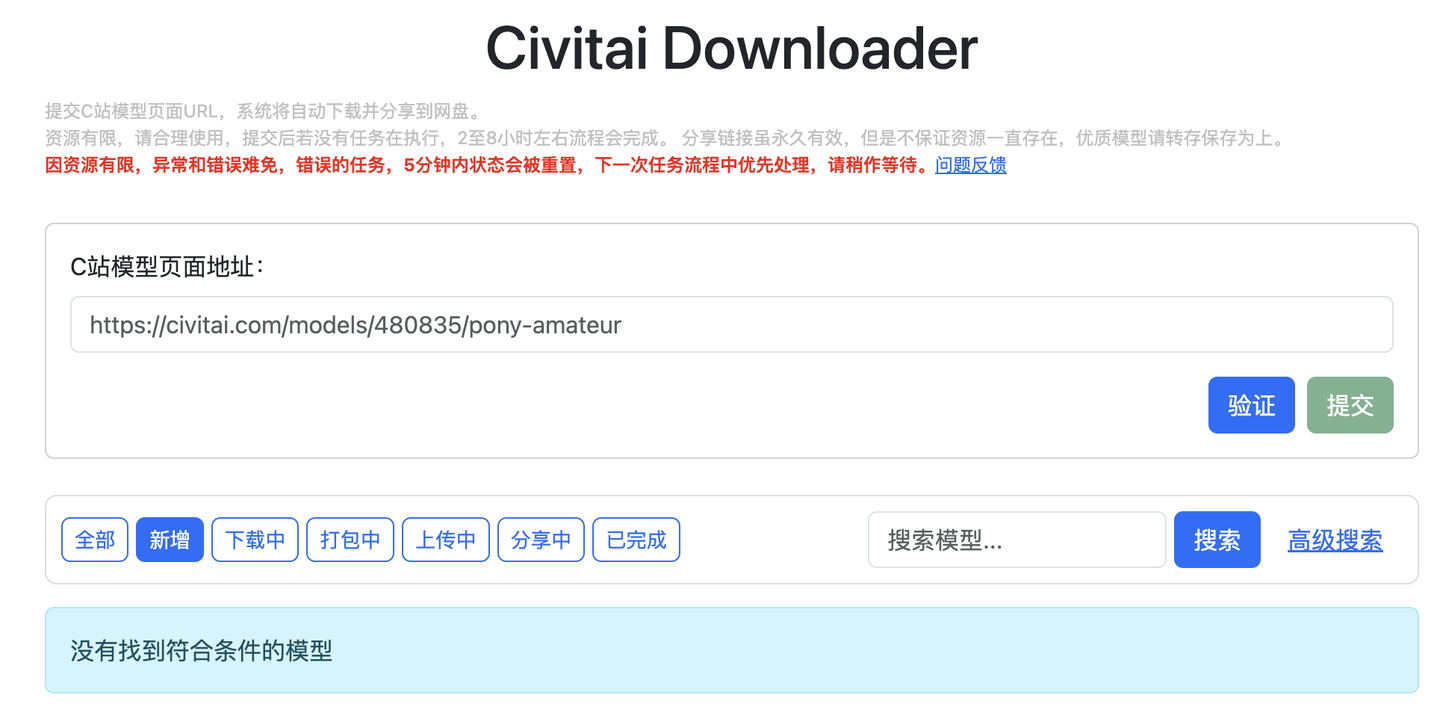
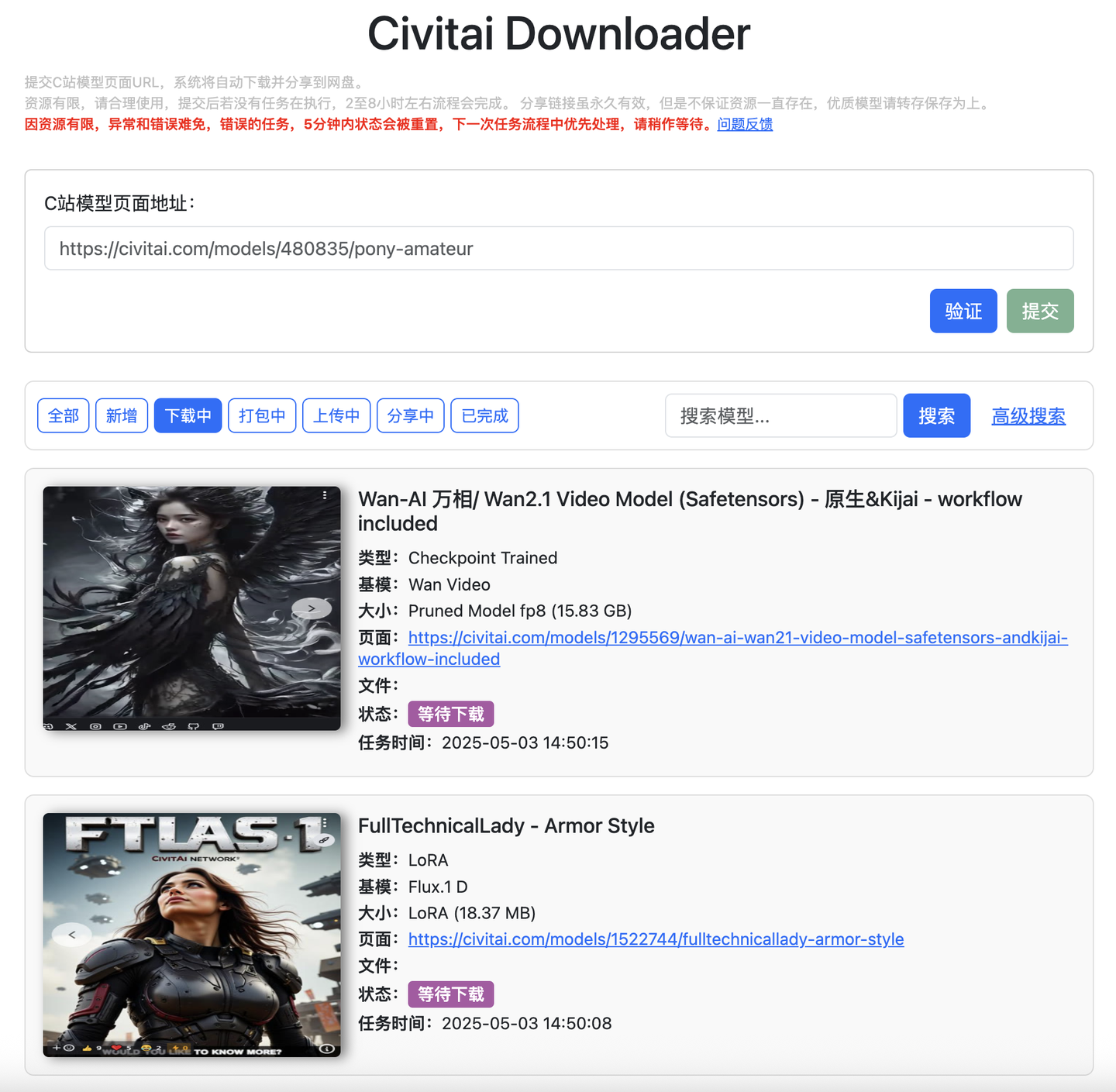
任务列表
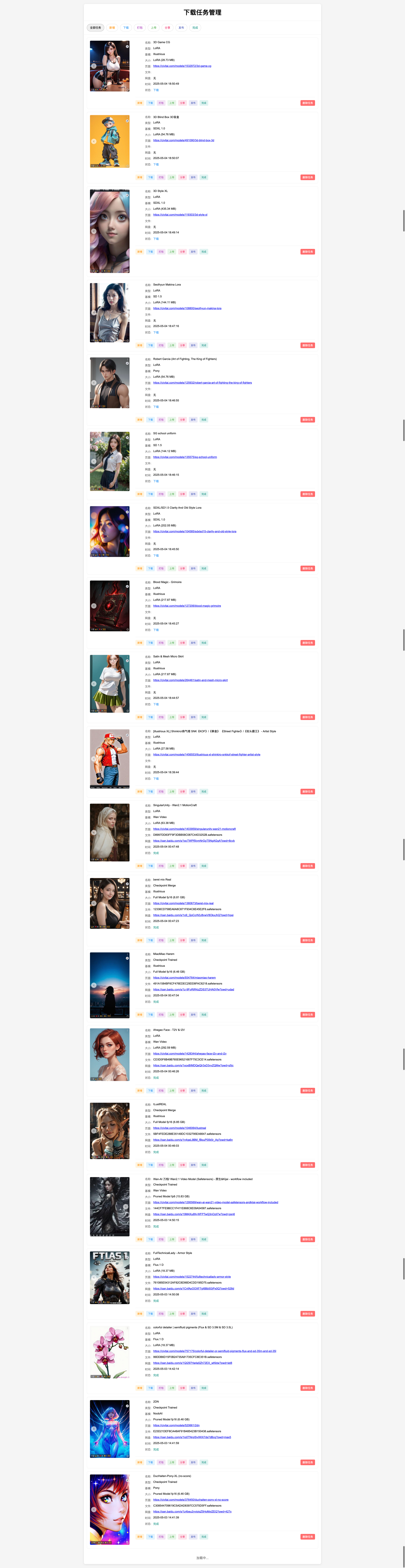
管理界面
已完成任务
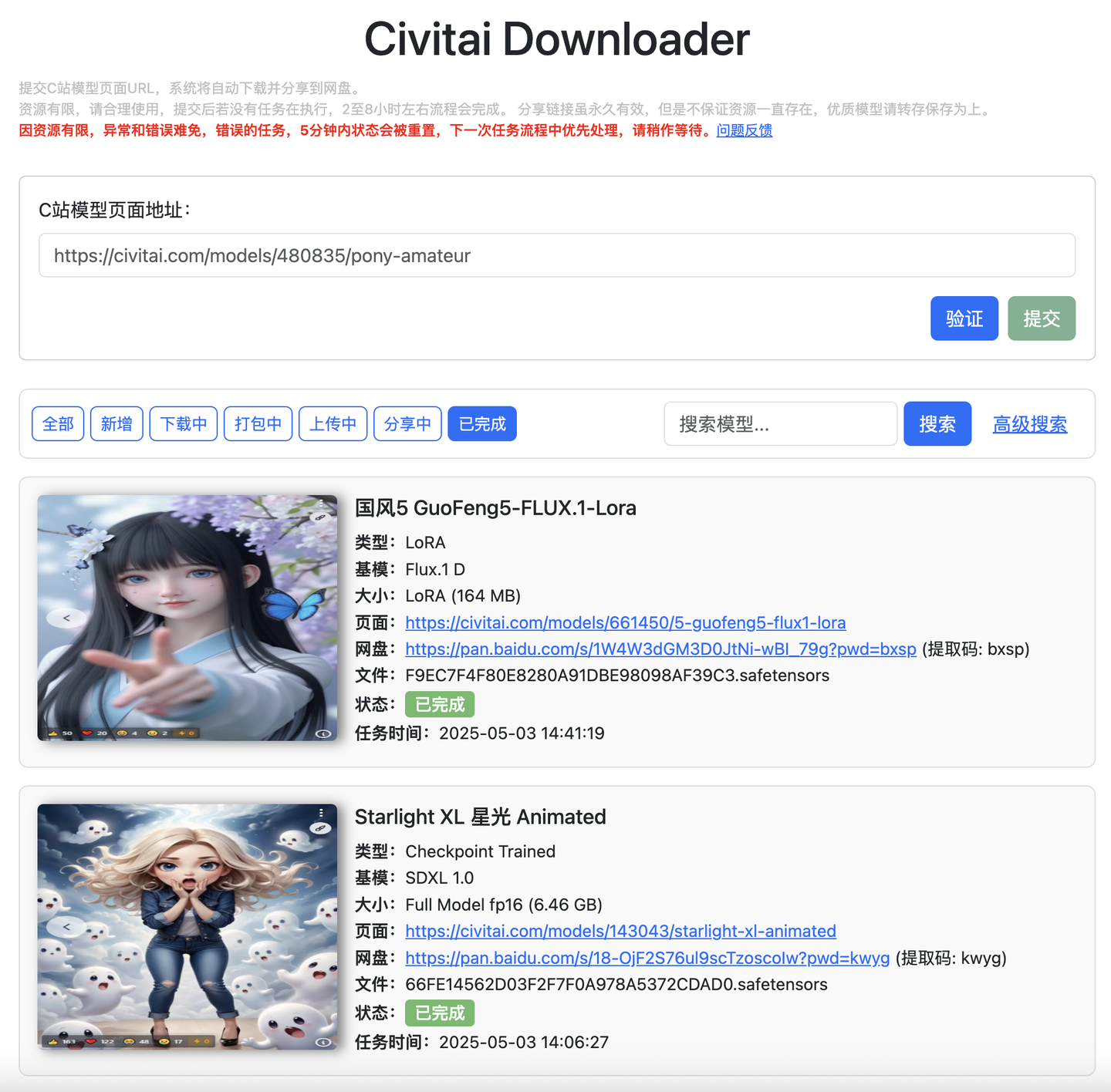
模型资讯站
6.总结
-
AI 当前尚无法独立承担复杂项目,但可作为高效的辅助工具,显著提升生产力。
-
“一句话生成 APP、网站或小程序”多为噱头;
-
合理设计提示词(Prompt)是成功运用 AI 的关键。
-
必备的基础知识与项目开发经验不可或缺。
-
学习AI的核心目标在于精准发现市场需求,通过AI实现快速且高质量的交付。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









