







冒泡排序:
它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
这个算法的名字由来是因为越大的元素会经由交换慢慢“浮”到数列的顶端,故名。
在要排序的一组数中,对当前还未排好序的范围内的全部数,自上而下对相邻的两个数依次进行比较和调整,让较大的数往下沉,较小的往上冒。即:每当两相邻的数比较后发现它们的排序与排序要求相反时,就将它们互换。
冒泡排序算法的运作如下:(从后往前)
1.比较相邻的元素。如果第一个比第二个大,就交换他们两个。
2.对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
3.针对所有的元素重复以上的步骤,除了最后一个。
4.持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
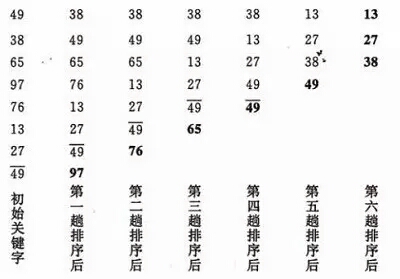
原理是临近的数字两两进行比较,按照从小到大或者从大到小的顺序进行交换,
这样一趟过去后,最大或最小的数字被交换到了最后一位,
然后再从头开始进行两两比较交换,直到倒数第二位时结束,其余类似看例子
这里图片描述了该进行多少趟循环(n-1);
排序需要很多趟,每一趟里面有很多次
这就说明了有外部循环与内部循环
外部循环:进行的趟数的循环
内部循环:进行的交换位置次数的循环
每一趟冒出一个最大的数,放到最后面(?????如何做到的,通过相邻元素比较,交换位置)
第一趟循环把数组的最大元素冒泡到最后一个位置
第二趟循环,不在检查数组最后一个元素,不改变,
把数组第二大数放在倒数第二位置
每一趟循环都把当前最大元素放在数组的合适位置中
n-1趟后,算法完成了所有元素排序
每趟该进行多少次循环–交换位置次数
每一趟确定了一个最大元素后就不在理会那个位置(观察图片)
第一趟有0个元素确定位置,要进行n-1次交换位置(3个元素要交换2次位置)
第二趟有一个元素确定了位置,要进行n-2次交换位置(比第一趟少一次,比第一趟少一个元素移动)
每一趟要进行n-i次位置变换(默认是从1开始数起)i是要进行的趟数
示例:
例子为从小到大排序,
原始待排序数组| 6 | 2 | 4 | 1 | 5 | 9 |
第一趟排序(外循环)
第一次两两比较6 > 2交换(内循环)
交换前状态| 6 | 2 | 4 | 1 | 5 | 9 |
交换后状态| 2 | 6 | 4 | 1 | 5 | 9 |
第二次两两比较,6 > 4交换
交换前状态| 2 | 6 | 4 | 1 | 5 | 9 |
交换后状态| 2 | 4 | 6 | 1 | 5 | 9 |
第三次两两比较,6 > 1交换
交换前状态| 2 | 4 | 6 | 1 | 5 | 9 |
交换后状态| 2 | 4 | 1 | 6 | 5 | 9 |
第四次两两比较,6 > 5交换
交换前状态| 2 | 4 | 1 | 6 | 5 | 9 |
交换后状态| 2 | 4 | 1 | 5 | 6 | 9 |
第五次两两比较,6 < 9不交换
交换前状态| 2 | 4 | 1 | 5 | 6 | 9 |
交换后状态| 2 | 4 | 1 | 5 | 6 | 9 |
第二趟排序(外循环)
第一次两两比较2 < 4不交换
交换前状态| 2 | 4 | 1 | 5 | 6 | 9 |
交换后状态| 2 | 4 | 1 | 5 | 6 | 9 |
第二次两两比较,4 > 1交换
交换前状态| 2 | 4 | 1 | 5 | 6 | 9 |
交换后状态| 2 | 1 | 4 | 5 | 6 | 9 |
第三次两两比较,4 < 5不交换
交换前状态| 2 | 1 | 4 | 5 | 6 | 9 |
交换后状态| 2 | 1 | 4 | 5 | 6 | 9 |
第四次两两比较,5 < 6不交换
交换前状态| 2 | 1 | 4 | 5 | 6 | 9 |
交换后状态| 2 | 1 | 4 | 5 | 6 | 9 |
第三趟排序(外循环)
第一次两两比较2 > 1交换
交换后状态| 2 | 1 | 4 | 5 | 6 | 9 |
交换后状态| 1 | 2 | 4 | 5 | 6 | 9 |
第二次两两比较,2 < 4不交换
交换后状态| 1 | 2 | 4 | 5 | 6 | 9 |
交换后状态| 1 | 2 | 4 | 5 | 6 | 9 |
第三次两两比较,4 < 5不交换
交换后状态| 1 | 2 | 4 | 5 | 6 | 9 |
交换后状态| 1 | 2 | 4 | 5 | 6 | 9 |
第四趟排序(外循环)无交换
第五趟排序(外循环)无交换
排序完毕,输出最终结果1 2 4 5 6 9
时间复杂度
若文件的初始状态是正序的,一趟扫描即可完成排序。所需的关键字比较次数和记录移动次数均达到最小值:
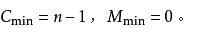
所以,冒泡排序最好的时间复杂度为
O(n)
若初始文件是反序的,需要进行n-1
趟排序。每趟排序要进行n-i
次关键字的比较(1≤i≤n-1),且每次比较都必须移动记录三次来达到交换记录位置。在这种情况下,比较和移动次数均达到最大值:
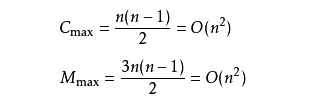
冒泡排序的最坏时间复杂度为
O(n²)
综上,因此冒泡排序总的平均时间复杂度为
O(n²)
算法稳定性
冒泡排序就是把小的元素往前调或者把大的元素往后调。比较是相邻的两个元素比较,交换也发生在这两个元素之间。所以,如果两个元素相等,我想你是不会再无聊地把他们俩交换一下的;如果两个相等的元素没有相邻,那么即使通过前面的两两交换把两个相邻起来,这时候也不会交换,所以相同元素的前后顺序并没有改变,所以冒泡排序是一种稳定排序算法。
Java代码实现:
package javastudy;
public class BubbleSort {
public static void main(String[] args) {
// TODO Auto-generated method stub
int A[]={6,2,4,1,5,9};
System.out.println("冒泡排序前的数组:");
show(A);
bubble(A);
System.out.println("冒泡排序后的数组:");
show(A);
}
private static void show(int[] A) {
for(int i=0;i<A.length;i++){
System.out.print(A[i]+" ");
}
System.out.println();
}
public static void bubble(int[] A){
for(int i=0;i<=A.length-2;i++){//外部循环
for(int j=0;j<=A.length-2-i;j++){//内部循环
if(A[j]>A[j+1]){//比较两个元素的大小,如果前一个大,则交换
int temp=A[j];
A[j]=A[j+1];
A[j+1]=temp;
}
}
}
}
}
一个小技巧:
Java中若需要重写的代码多且要重复使用多次,可利用重构,把这些重复的代码组成一个函数,需要时调用即可
例如上面的show函数
1.选中需要重复代码部分
2.右键选Refactor
3.refactor中选Extract Method
4.写上函数名即可
冒泡排序优化
思想1:当遇到一趟里面(内部循环)每一相邻相隔两个元素都不需要交换位置,证明排序已经排好了,下面的剩余的趟数就不需要在进行了
Java代码:
package javastudy;
public class BubbleSort {
public static void main(String[] args) {
// TODO Auto-generated method stub
int A[]={6,2,4,1,5,9};
System.out.println("冒泡排序前的数组:");
show(A);
bubble(A);
System.out.println("冒泡排序后的数组:");
show(A);
}
private static void show(int[] A) {
for(int i=0;i<A.length;i++){
System.out.print(A[i]+" ");
}
System.out.println();
}
public static void bubble(int[] A){
for(int i=0;i<=A.length-2;i++){//外部循环
boolean flag=false;
for(int j=0;j<=A.length-2-i;j++){//内部循环
if(A[j]>A[j+1]){//比较两个元素的大小,如果前一个大,则交换
int temp=A[j];
A[j]=A[j+1];
A[j+1]=temp;
flag=true;//只要执行过一次内部循环的交换位置,flag就是true
}
}
if(!flag)//只有内部循环交换位置一次都没有执行过才会跳出
{
break;
}
}
}
}
冒泡排序优化
思想二:
每一次冒泡可以找出最大元素,也可以通过同样道理找最小元素,如果排序时,通过冒泡找最大元素放在最后,和冒泡找出最小元素,一次排序可以确定这次的最大最小元素,从而使排序趟数几乎减少一半
public static void bubble_2(int[]A){
int low=0;
int high=A.length-1;//low和high确定了n个元素
int temp,j;
while(low<high){
for(j=low;j<high;j++){//正向冒泡,找出最大值
if(A[j]>A[j+1]){
temp=A[j];
A[j]=A[j+1];
A[j+1]=temp;
}
}
high--;//最后一位确定了,就前移
for(j=high;j>low;j--){//反向冒泡,找出最小值
if(A[j]<A[j-1]){
temp=A[j];
A[j]=A[j-1];
A[j-1]=temp;
}
}
low++;//第一位确定了就,后移
}//j的起始位置是low和high的原因是每进行一趟都可以确定一个最大最小元素,然后通过high--;与low++忽略上一次的最大最小元素,减少循环次数,for循环中的判断条件也是如此
}















 823
823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









