







Self-attention module详解
1. Data Input and Output
生活中解决实际问题时,可能会遇到一组向量作为输入的情况,这种输入情况称作为Vector Set as Input。这类问题常常出现在文本翻译,语音识别,图(Graph)分析中。
那么这类问题的输出,就是一组或一个label,根据输出label个数不同可以分为以下三类:
情况1. 每个向量都会有一个label
上面这个例子就是每个单词都会对应输出其词性label,每个单词可以看作是一个向量。
情况2. 这组向量共同输出一个label值
比如在语音识别上,一段语音,去判断这段语音是谁说的。
情况3. label输出个数是不确定的
在这种情况下,label个数是由模型自动决定的,典型的模型代表是seq2seq模型,情况3也是在文本翻译上所面临的问题。
2. Sequence Labeling
考虑情况一,其中的例子稍微做一个改动,考虑为这个句子中每个单词都需要输出其意思,那么这个问题也是每个向量都会输出一个label的问题。
那么如果是不考虑上下文的情况,用相同的FC模型去推理,前后两个saw输入向量是完全一致的,模型没有理由会输出两个不一样的翻译结果。
那么解决这个问题的一个思路是将上下文加入,也就是设置一个像滑动窗的window,将window所覆盖的单词作为一个整体输入进行训练,得到模型再进行推理。
这个方法在一些简单问题的情况下可以取得不错的效果,但是这种思路也会存在其瓶颈。比如在sequence特别长的情况下,又需要考量整个sequence才可以得出结果的情况;sequence在文本翻译情况下长度是变化的,可长可短。若强行继续使用window的方式,并将window开大,来训练网络,那么会使得运算量急剧增大,同时也会有over-fitting的危险。
为了解决上述可能遇到的复杂输入情况,又还需要继续结合上下文分析的思路走,那么self-attention机制就是解决这种问题而产生的。
3. Self-Attention
3.1 Self-Attention与网络结构的关系
self-attention与最初的开大window有相同的想法,那就是接收了整个sequence,考虑到了整个sequence的上下文。比起window直接塞进网络训练,self-attention做了一些计算上下文关联度的操作。
我们在开始部分说到,sequence是一组向量,“vector set as input”,这么一组向量经过self-attention module后会输出与输入向量数目相等的向量,也就是说,输入了多少向量,也会输出多少向量。self-attention module可以与FC重复叠加,一个简单重复叠加网络结构可以设计如下所示。
Note: self-attention这个著名的模块是在《Attention is all you need》这篇文章提出的,在这篇文章中其实是提出了Transformer架构,self-attention是其中的一个模块,后来发扬光大的部分。
3.2 Self-Attention内部计算过程
self-attention模块最终的输出是一组向量,当我们输出第一个向量 b 1 \ b^1 b1时,模块内部做了哪些操作呢?sequence输入时,会计算每个向量与其他向量的关联度,如下图所示(台大李宏毅教授PPT)。
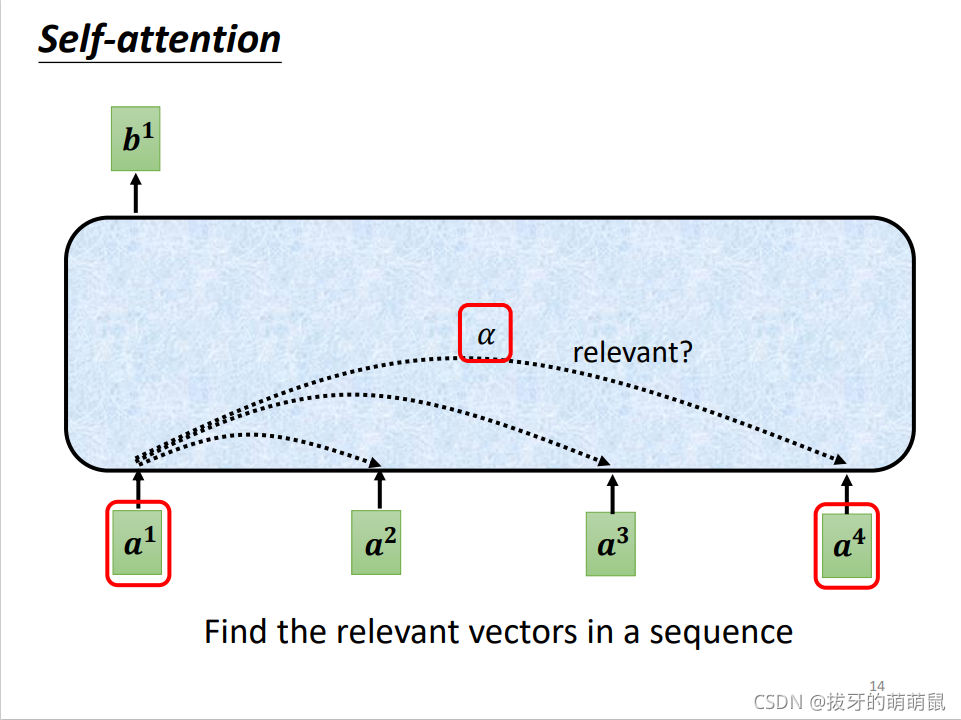
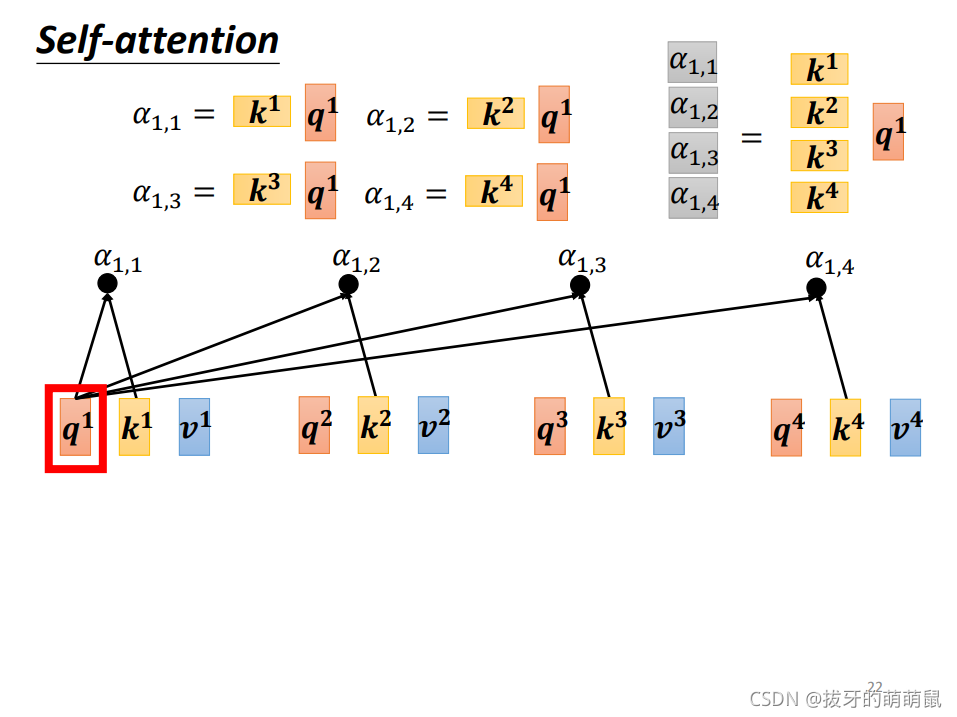
两个向量之间的关联度定义为 α \ \alpha α,计算过程如下图所示。
这个过程计算出来关联度定义为 α 1 , 2 \ \alpha_{1,2} α1,2,同理我们可以计算出 α 1 , 3 , α 1 , 4 \ \alpha_{1,3}, \alpha_{1,4} α1,3,α1,4,同时还需要计算同自己的关联度 α 1 , 1 \ \alpha_{1,1} α1,1。此时我们得到了四个关联值,但它们还不是最终的关联值,还需要通过一层激活函数,我们可以假定是softmax函数。
也就是说,经过softmax之后,才得到了 a 1 \ a^1 a1和 a 2 , a 3 , a 4 \ a^2,a^3,a^4 a2,a3,a4之间的最终关联度 α 1 , 1 ′ , α 1 , 2 ′ , α 1 , 3 ′ , α 1 , 4 ′ \ \alpha'_{1,1},\alpha'_{1,2},\alpha'_{1,3},\alpha'_{1,4} α1,1′,α1,2′,α1,3′,α1,4′。
此时,就可以通过得到的关联度计算 a 1 \ a^1 a1所对应的self-attention输出 b 1 \ b^1 b1了。计算过程如下
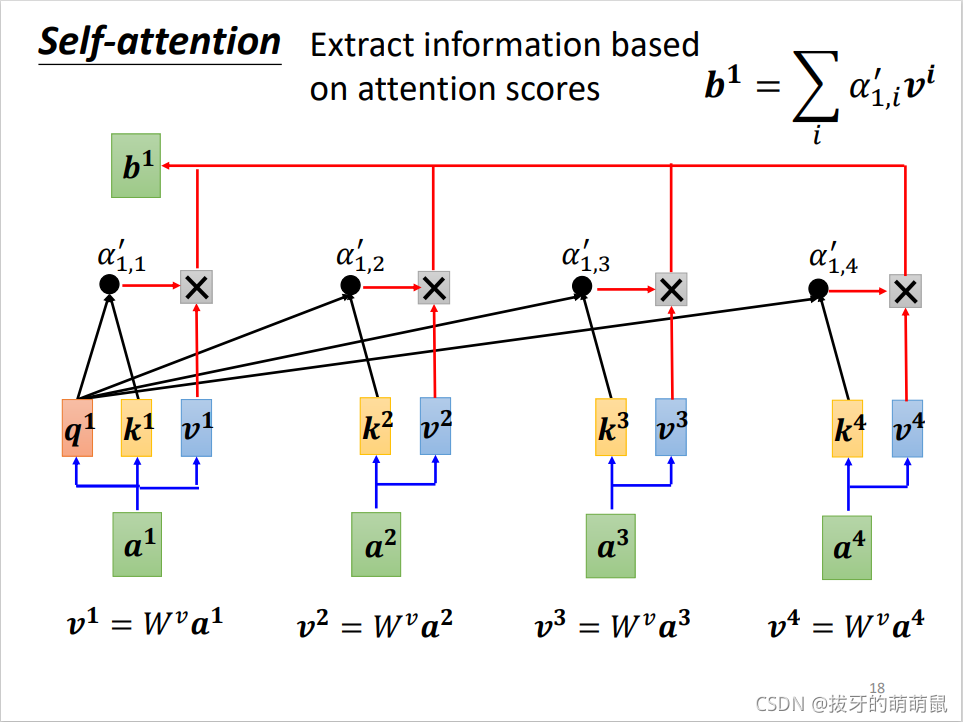
与 v 1 , v 2 , v 3 , v 4 \ v^1,v^2,v^3,v^4 v1,v2,v3,v4相乘并求和,就得到了输出值 b 1 \ b^1 b1。
其他向量的计算输出过程也是以此类推,便不再赘述。
3.3 向量公式表示Self-Attention内部计算过程
q 1 q 2 q 3 q 4 = W q a 1 a 2 a 3 a 4 \pmb{q^1q^2q^3q^4=W^qa^1a^2a^3a^4} q1q2q3q4=Wqa1a2a3a4q1q2q3q4=Wqa1a2a3a4q1q2q3q4=Wqa1a2a3a4
左边写为
Q
\ \pmb{Q}
QQQ,右边写成
I
\ \pmb{I}
III,那么可以写成下面这种形式
Q
=
W
q
I
\pmb{Q=W^qI}
Q=WqIQ=WqIQ=WqI
k
1
k
2
k
3
k
4
=
W
k
a
1
a
2
a
3
a
4
\pmb{k^1k^2k^3k^4=W^ka^1a^2a^3a^4}
k1k2k3k4=Wka1a2a3a4k1k2k3k4=Wka1a2a3a4k1k2k3k4=Wka1a2a3a4
左边写为
K
\ \pmb{K}
KKK得到
K
=
W
k
I
\pmb{K=W^kI}
K=WkIK=WkIK=WkI
v 1 v 2 v 3 v 4 = W v a 1 a 2 a 3 a 4 \pmb{v^1v^2v^3v^4=W^va^1a^2a^3a^4} v1v2v3v4=Wva1a2a3a4v1v2v3v4=Wva1a2a3a4v1v2v3v4=Wva1a2a3a4
左边写成
V
\ \pmb{V}
VVV得到
V
=
W
v
a
1
a
2
a
3
a
4
\pmb{V=W^v a^1a^2a^3a^4}
V=Wva1a2a3a4V=Wva1a2a3a4V=Wva1a2a3a4
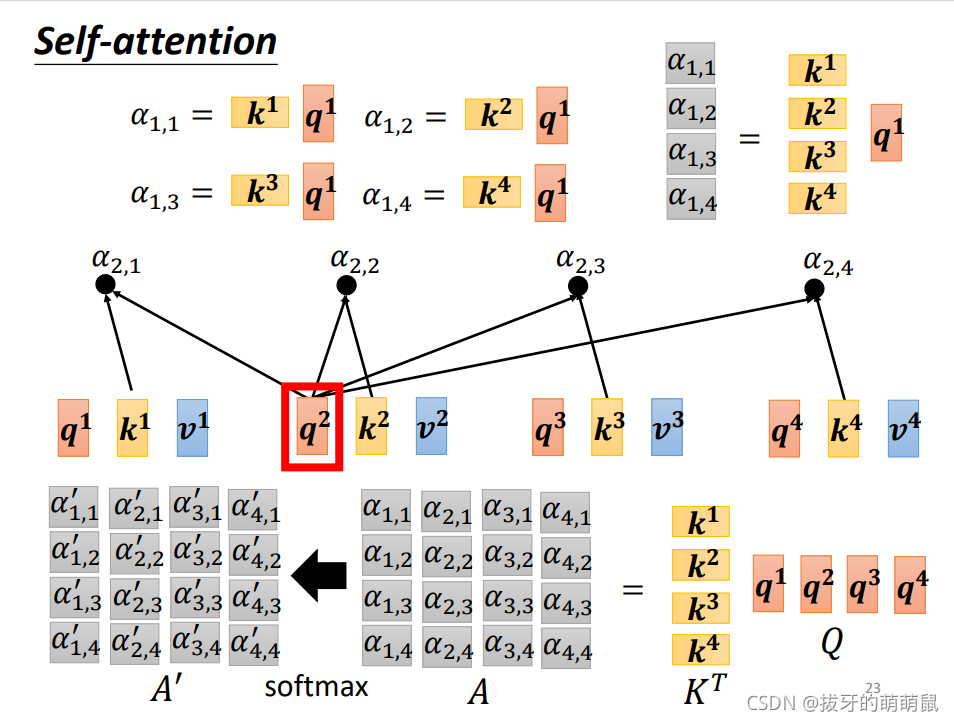
A
=
K
T
Q
\pmb{A=K^T Q}
A=KTQA=KTQA=KTQ
在经过一次softmax激活函数,得到
A
′
\ \pmb{A'}
A′A′A′。
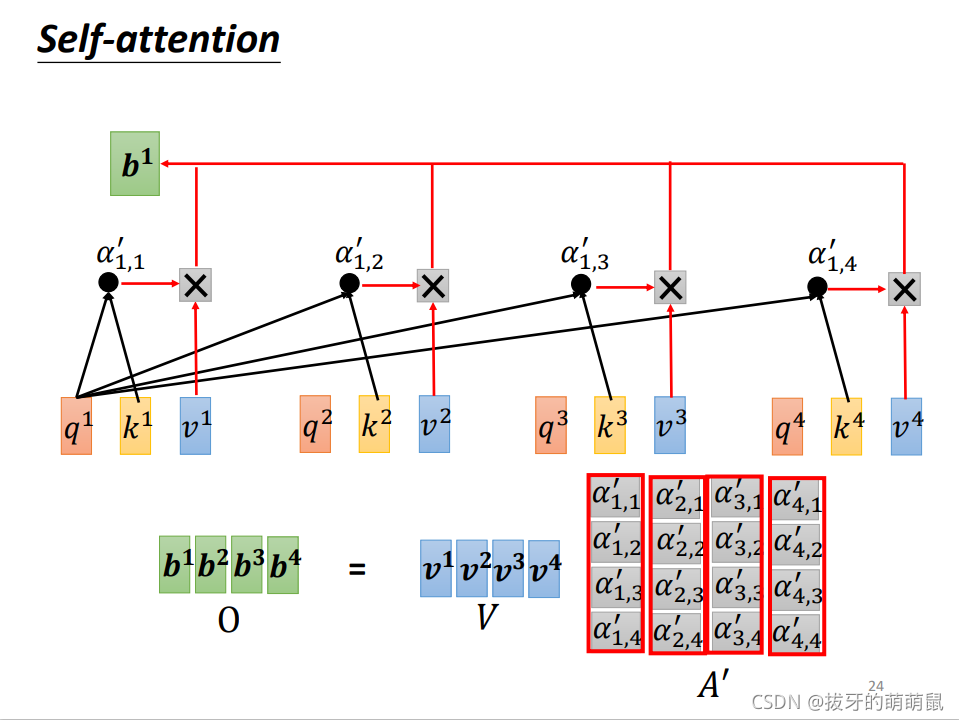
得到的
A
′
\ \pmb{A'}
A′A′A′再前乘一个
V
\ \pmb{V}
VVV向量即可得到self-attention模块的向量集输出。
b
1
b
2
b
3
b
4
=
v
1
v
2
v
3
v
4
A
′
\pmb{b^1b^2b^3b^4=v^1v^2v^3v^4A'}
b1b2b3b4=v1v2v3v4A′b1b2b3b4=v1v2v3v4A′b1b2b3b4=v1v2v3v4A′














 2685
2685











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









