







|
2014年12月考研前一周写的笔记。。。 放在这里,希望对其他人有帮助。。。=============================================== 写到一半时,发现这个公开课的资料挺全的: http://share.onlinesjtu.com/course/view.php?id=3# 教材,视频,ppt,还有swf。。。 =============================================== 0.准备 1.组成原理比体系结构更偏向于硬件或者实现 2.IEEE754 float,1,8,32,阶数偏移127(也就是实际范围是-127~128)和一般的移码偏移2^n不同,尾数是原码 double,1,11,52 3.原码和补码运算 a.移位 逻辑移位,符号位不特殊对待 算数移位,符号位特殊对待 循环移位 例子:
b.溢出判断 一个符号位:俩个同号数相加,若结果符号变换,则为溢出 两个符号位:结果的两个符号位不同,则为溢出 两者等价,还有一种比较符号位进位和最高位进位的方法,不过该方法和2等价,只是不同的表述而已。 c.乘法 原码乘法: 符号位异或,去掉符号位的运算同手工 补码乘法: 可以当初无符号数,按手工算法算 也可以按照Booth算法(该算法在乘数中有连续的1时,比较有效,其实该方法也可以用在原码乘法中) d.除法 原码除法: 恢复余数:符号位异或,其他位手工 不恢复余数 补码除法: 同不恢复余数发,只是上商时,0还是1,有些变化(其实也和原码运算一样,和除数同号上1,不同号上0) 4.浮点加减 a.对阶 b.位数求和 c.规格化(尾数“溢出”右规,阶码溢出才是真的溢出) 1.cpu和指令集 1.1寻址方式,主要是基址寻址和变址寻址【9】 变址寻址,是把在指令字中给出的一个数值(称为变址偏移量)与一个被称为变址寄存器的内容相加之和作为操作数的地址,用于读写存储器。 基地址寻址,是指把在程序中所用的地址与一个特定的寄存器(称为基地址寄存器)的内容相加之和作为操作数的地址或指令的地址。两者相似,但使用上有差别。 基址寻址:其中的形式地址是可变的,基址寄存器的内容是一定的 变址寻址:形式地址不变,变址寄存器的内容可变 因此它可用于处理数组问题 1.2指令周期 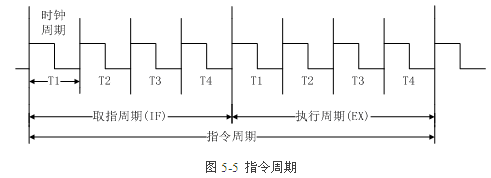
1.3硬布线和微程序控制 硬布线:RISC,指令少,逻辑电路。 微程序控制:CISC,用微程序来执行指令。 1.4流水和数据相关 数据相关(写后读(Read-After-Write,RAW)相关、读后写(Write-After-Read,WAR)相关、写后写(Write-After-Write,WAW) 资源相关(同时使用硬盘?) 控制相关(跳转分支,if...else...) 静态流水线:同一时间内,多功能结构只能按一种功能的连接方式工作。 动态流水线:同一时间内,可以有多种功能的连接方式同时工作。 2.存储 0.准备 存取时间和存取周期 存取时间是执行一次读操作或写操作的时间,分为读出时间和写入时间。 读出时间为从主存接收到有效地址到数据稳定为止的时间; 写入时间是从主存接收到有效地址开始到数据写入被写单元为止的时间。 存取周期是指存储器进行两次连续独立的读或写操作所需的最小的时间间隔。 通常,存取周期大于存取时间。 1.cache a.直接相连,全相联,组相联【3】 为了能理解得更加透彻,把存储器比作一家大超市,超市里面的东西就是一个个字节或者数据。为了让好吃好玩受欢迎的东西能够容易被看到,超市可以将这些东西集中在一块放在一个专门的推荐柜台中,这个柜台就是缓存。如果仅仅是把这些货物放在柜台中即完事,那么这种就是完全关联的方式。可是如果想寻找自己想要的东西,还得在这些推荐货物中寻找,而且由于位置不定,甚至可能把整个推荐柜台寻找个遍,这样的效率无疑还是不高的。于是超市老总决定采用另一种方式,即将所有推荐货物分为许多类别,如“果酱饼干”,“巧克力饼干”,“核桃牛奶”等,柜台的每一层存放一种货物。这就是直接关联的访问原理。这样的好处是容易让顾客有的放矢,寻找更快捷,更有效。但这种方法还是有其缺点,那就是如果需要果酱饼干的顾客很多,需要巧克力饼干的顾客相对较少,显然对果酱饼干的需求量会远多于对巧克力饼干的需求量,可是放置两种饼干的空间是一样大的,于是可能出现这种情况:存放的果酱饼干的空间远不能满足市场需求的数量,而巧克力饼干的存放空间却被闲置。为了克服这个弊病,老板决定改进存货方法:还是将货物分类存放,不过分类方法有所变化,按“饼干”,“牛奶”,“果汁”等类别存货,也就是说,无论是什么饼干都能存入“ 饼干”所用空间中,这种方法显然提高了空间利用的充分性,让存储以及查找方法更有弹性。 b.替换算法【4】 随机 先进先出 最近不经常使用: LFU算法认为应将一段时间内被访问次数最少的那行数据换出。为此,每行设置一个计数器。新行建立后从0开始计数,每访问一次,被访问行的计数器增1。当需要替换时,对这些特定行的计数值进行比较,将计数值最小的行换出,同时将这些特定行的计数器都清零。这种算法将计数周期限定在对这些特定行两次替换之间的间隔内,因而不能严格反映近期访问情况。 LRU: LRU算法将近期内长时间未被访问过的行换出。为此,每行也设置一个计数器,但它们是Cache每命中一次,命中行计数器清零,其他各行计数器增1。当需要替换时,比较各特定行的计数值,将计数值最大的行换出。这种算法保护了刚复制到Cache中的新数据行,符合Cache工作原理,因而使Cache有较高的命中率。 c.写回和写分配 全写法:cache和内存同时写入。非写分配:写数据,cache未命中,直接写内存,不把数据调入内存。 写回法:只写入cache。要有标志位,数据被替换时,写回内存,存在冲突的风险。写分配:写数据,cache未命中,数据调入内存。 2.虚拟存储器 a. 页【5】, 段【6】, 段页【7】 去看百度百科。。。 b. 快表TLB【8】 联想寄存器 TLB和CPU里的一级、二级 缓存之间不存在本质的区别,只不过前者 缓存页表数据,而后两个缓存实际数据。 3.总线 1.总线仲裁【11】 分布:分布式总裁有些像计算机网络 集中:链式查询,计时器查询,独立请求 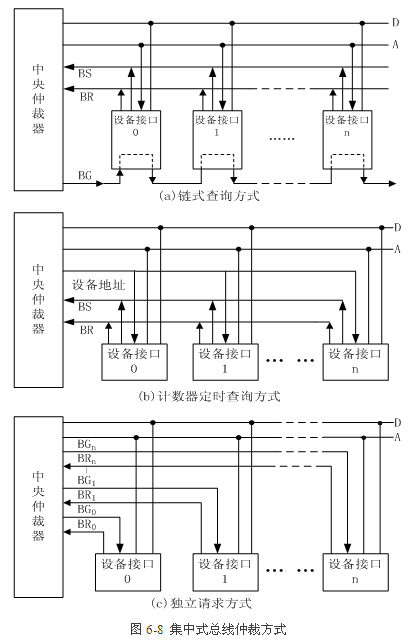
2.总线操作和定时【12】【13】(不同领域,同步和异步指的东西好像是不同的) 同步: 异步:不互锁,半互锁,全互锁 【14】 半同步: 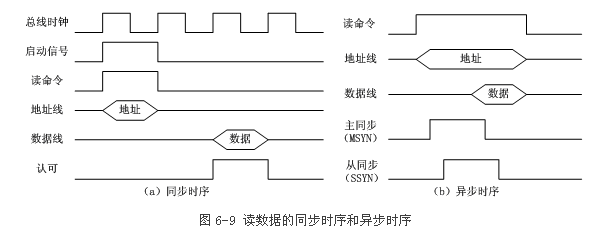
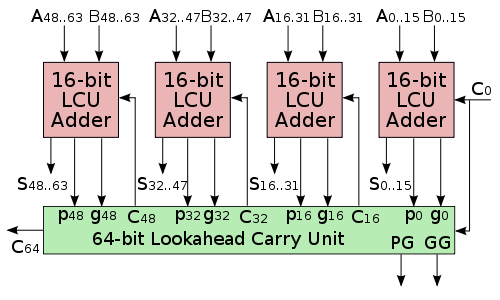
同步和异步的区别:同步需要时钟信号,在时钟上升沿或下降沿传送的信号才有效? 也就是说,verilog写cpu的时候,如果用时钟信号和计数器相结合,片内总线就用的是同步通信? 计算机网络上,传输的信号中没有时钟信号,所以肯定是异步通信? 4.IO 4.0.磁盘地址 驱动器号::柱面(磁道)号::盘面号::扇区号 4.1中断和程序查询 4.2.中断 4.1.1内部中断,外部中断 4.1.2中断和响应,是否开中断,指令执行周期结束响应 4.1.3中断处理过程,多重中断,屏蔽字(对应位为1则被屏蔽), 4.3.DMA cpu预处理,设置IO设备和DMA 外设准备好后,DMA控制器向cpu申请总线使用权限(DMA请求) DMA传输结束,向cpu发出中断信号 4.4通道 附: 1.Booth 乘法原理【1】 考虑一个由若干个 0 包围着若干个 1 的正的二进制乘数,比如 00111110,积可以表达为: 其中,M 代表被乘数。变形为下式可以使运算次数可以减为两次: 事实上,任何二进制数中连续的 1 可以被分解为两个二进制数之差: 因此,我们可以用更简单的运算来替换原数中连续为 1 的数字的乘法,通过加上乘数,对部分积进行移位运算,最后再将之从乘数中减去。它利用了我们在针对为零的位做乘法时,不需要做其他运算,只需移位这一特点,这很像我们在做和 99 的乘法时利用 99 = 100 − 1 这一性质。 这种模式可以扩展应用于任何一串数字中连续为 1 的部分(包括只有一个 1 的情况)。那么, 布斯算法遵从这种模式,它在遇到一串数字中的第一组从 0 到 1 的变化时(即遇到 01 时)执行加法,在遇到这一串连续 1 的尾部时(即遇到 10 时)执行减法。这在乘数为负时同样有效。当乘数中的连续 1 比较多时(形成比较长的 1 串时),布斯算法较一般的乘法算法执行的加减法运算少。 2.并行进位加法器【2】为了减少多位二进制数加减计算所需的时间,工程师设计了一种比脉动进位加法器速度更快的加法器电路,这种加法器被称为“超前进位加法器(carry-lookahead adder)”。 下面简述超前进位加法器的主要原理。[6][1]:255-262我们先来考虑构成多位加法器的单个全加器从其低一位获得的进位信号
于是,某位全加器从低一位获得的进位可以表示为 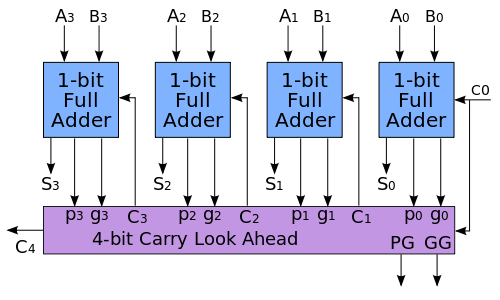
3.流水【10】 3.1.指令流水线过程段 图5-20表示流水CPU中一个指令周期的任务分解。假设指令周期包含取指令(IF)、指令译码(ID)、指令执行(EX)、访存取数(MEM)、结果写回(WB)5个子过程(过程段),流水线由这5个串联的过程段组成,各个过程段之间设有高速缓冲寄存器,以暂时保存上一过程段子任务处理的结果,在统一的时钟信号控制下,数据从一个过程段流向相邻的过程段。
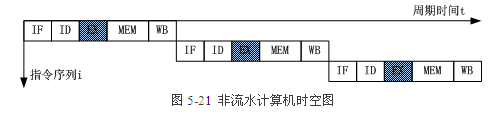
3.2.非流水计算机工作方式
对于非流水计算机而言,上一条指令的5个子过程全部执行完毕后才能开始下一条指令,每隔5个时钟周期才有一个输出结果。因此,图5-21中用了15个时钟周期才完成3条指令,每条指令平均用时5个时钟周期。 非流水线工作方式的控制比较简单,但部件的利用率较低,系统工作速度较慢。 3.3.标量流水计算机工作方式
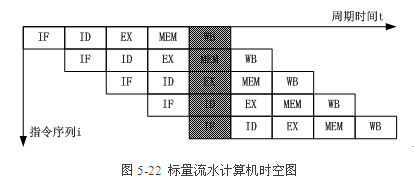
对标量流水计算机而言,上一条指令与下一条指令的5个子过程在时间上可以重叠执行,当流水线满载时,每一个时钟周期就可以输出一个结果。因此,图5-22中仅用了9个时钟周期就完成了5条指令,每条指令平均用时1.8个时钟周期。 3.4.超标量流水计算机工作方式
当流水线满载时,每一个时钟周期可以执行2条以上的指令。因此,图5-23中仅用了9个时钟周期就完成了10条指令,每条指令平均用时0.9个时钟周期。 参考资料: 【01】 http://zh.wikipedia.org/wiki/%E5%B8%83%E6%96%AF%E4%B9%98%E6%B3%95%E7%AE%97%E6%B3%95 【02】 http://zh.wikipedia.org/wiki/%E5%8A%A0%E6%B3%95%E5%99%A8 【03】 http://baike.baidu.com/view/907.htm 【04】 http://baike.baidu.com/view/3871278.htm 【05】 http://baike.baidu.com/view/3224034.htm 【06】 http://baike.baidu.com/view/3227088.htm 【07】 http://baike.baidu.com/view/3227786.htm 【08】 http://baike.baidu.com/view/129737.htm 【09】 http://cop.cjlu.edu.cn/forum.php?mod=viewthread&tid=197 【10】 http://share.onlinesjtu.com/mod/tab/view.php?id=300 【11】 http://share.onlinesjtu.com/mod/tab/view.php?id=258 【12】 http://share.onlinesjtu.com/mod/tab/view.php?id=259 【13】 http://bbs.csdn.net/topics/370019505 【14】 http://blog.csdn.net/ce123_zhouwei/article/details/6933329 |





 ,我们可以将它变换为
,我们可以将它变换为 。现在为二级制数的每一位构建两个新信号:
。现在为二级制数的每一位构建两个新信号:

 ,例如次低位全加器从最低位获得的进位为
,例如次低位全加器从最低位获得的进位为 ,而从最低位开始第三位的那个全加器获得的进位信号则为
,而从最低位开始第三位的那个全加器获得的进位信号则为 。在多位脉动进位加法器中,C2必须连接到低一位的进位输出信号,如果使用这种方式构成多位全加器,则逻辑门的延迟会发生累加,导致降低电路的计算效率下降。超前进位加法器采取的方式是,将C1的逻辑函数代入到C2,即
。在多位脉动进位加法器中,C2必须连接到低一位的进位输出信号,如果使用这种方式构成多位全加器,则逻辑门的延迟会发生累加,导致降低电路的计算效率下降。超前进位加法器采取的方式是,将C1的逻辑函数代入到C2,即 ,于是,这一位的进位输出就只取决于x1、y1、x0、y0、c0几个信号,而这几个信号都是计算电路外部的已知信号,而非低一位的计算结果。上面考虑的是从最低位开始第三位的情况。采用类似的代入方法,可以用各位的生成信号Gi、传输信号Pi,以及最低位从外部获取的进位信号C0来表示多位全加器的所有进位信号。
,于是,这一位的进位输出就只取决于x1、y1、x0、y0、c0几个信号,而这几个信号都是计算电路外部的已知信号,而非低一位的计算结果。上面考虑的是从最低位开始第三位的情况。采用类似的代入方法,可以用各位的生成信号Gi、传输信号Pi,以及最低位从外部获取的进位信号C0来表示多位全加器的所有进位信号。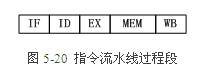
















06-20
 1370
1370
1370
07-29
1431
1431
07-19
1516
1516
08-01
2320
2320
07-24
1277
1277
08-07
1017
1017
04-18
117
117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









