






 本文介绍了数据库设计的基本原则,包括3NF和反范式设计,强调在实际开发中如何权衡规范化与性能。接着讨论了B树和B+树在数据库索引中的作用,以及Mysql的BufferPool缓存机制,包括LRU算法、预读和脏页管理。最后提到了Mysql的优化点,如join优化和分库分表策略。
本文介绍了数据库设计的基本原则,包括3NF和反范式设计,强调在实际开发中如何权衡规范化与性能。接着讨论了B树和B+树在数据库索引中的作用,以及Mysql的BufferPool缓存机制,包括LRU算法、预读和脏页管理。最后提到了Mysql的优化点,如join优化和分库分表策略。
一、前言
其实,我们做的大多数系统都是数据库应用系统,up主的大学专业也是这个。对于这部分知识,确实有掌握的必要。然而,实际上这部分知识并不困难,大部分知识点看一眼就会了。
本篇打算包括以下几个方面:
- 数据库表的设计
- B+树
- Mysql的缓存和sql执行过程
- Mysql索引
- join优化
- 分库分表
二、3范式与反范式设计
2.1 第一范式
所有数据列都是不可再分的原子值,也就是每个字段都不可以再拆分成更小的单位。
PS:但实际上,有些字段可以很确定的不会用作查询条件,有些时候放个json进去也未尝不可;只不过,那些信息再添加字段时,会变得十分麻烦,有新旧数据结构不同的问题
表样例:
| 学号 | 姓名 | 系名 | 系主任 | 课程名 | 分数 |
|---|---|---|---|---|---|
| 1 | 李晓明 | 经济系 | 凯因斯 | 高等数学 | 95 |
| 1 | 李晓明 | 经济系 | 凯因斯 | 大学英语 | 87 |
| 1 | 李晓明 | 经济系 | 凯因斯 | 普通化学 | 76 |
| 2 | 张莉莉 | 经济系 | 凯因斯 | 高等数学 | 72 |
| 2 | 张莉莉 | 经济系 | 凯因斯 | 大学英语 | 98 |
| 2 | 张莉莉 | 经济系 | 凯因斯 | 计算机基础 | 88 |
| 3 | 高芳芳 | 法律系 | 刘诗韵 | 高等数学 | 82 |
| 3 | 高芳芳 | 法律系 | 刘诗韵 | 法律基础 | 82 |
2.2 第二范式
在满足第一范式的基础上,非主键列完全依赖于主键列,而不是部分依赖。也就是说,一个表中的所有非主键字段必须完全依赖于主键,而不是只依赖于主键的某个部分。
简单来讲,就是符合第一范式,表中必须有主键,其他字段可由主键确定。二范式只是通过拆表来解决数据冗余。不能解决删除插入异常的问题。
表样例
| 学号 | 课程名 | 分数 |
|---|---|---|
| 1 | 高等数学 | 95 |
| 1 | 大学英语 | 87 |
| 1 | 普通化学 | 76 |
| 2 | 高等数学 | 72 |
| 2 | 大学英语 | 98 |
| 2 | 计算机基础 | 88 |
| 3 | 高等数学 | 82 |
| 3 | 法律基础 | 82 |
| 学号 | 姓名 | 系名 | 系主任 |
|---|---|---|---|
| 1 | 李晓明 | 经济系 | 凯因斯 |
| 2 | 张莉莉 | 经济系 | 凯因斯 |
| 3 | 高芳芳 | 法律系 | 刘诗韵 |
2.3 第三范式
在满足第二范式的基础上,所有非主键列之间没有依赖关系。也就是说,一个表中的任何非主键字段都不能依赖于其他非主键字段,而是必须依赖于主键字段。简单来说,就是拆分实体,形成主外键的关联。
表样例
| 学号 | 课程名 | 分数 |
|---|---|---|
| 1 | 高等数学 | 95 |
| 1 | 大学英语 | 87 |
| 1 | 普通化学 | 76 |
| 2 | 高等数学 | 72 |
| 2 | 大学英语 | 98 |
| 2 | 计算机基础 | 88 |
| 3 | 高等数学 | 82 |
| 3 | 法律基础 | 82 |
| 学号 | 姓名 | 系名 |
|---|---|---|
| 1 | 李晓明 | 经济系 |
| 2 | 张莉莉 | 经济系 |
| 3 | 高芳芳 | 法律系 |
| 系名 | 系主任 |
|---|---|
| 经济系 | 凯因斯 |
| 法律系 | 刘诗韵 |
2.4 实体关系与代理主键
数据库中的实体关系通常有3种,1-1,1-n,n-n。
1-1可以用主键做关联;1-n两张表,多的一方设置外键,关联少的一方;n-n得3张表,其中维护一个引用表,持有双方的外键,维护2个表的关系。
在现代数据库中,尽量给实体设置代理主键,而不要以有意义的字段作为主键。
2.5 反范式设计
然而,在实际开发中,完全按照标准的三范式设计数据库,会使得数据库有太多的表,使得关系难以理清,并且在查询时需要大量的表连接,使得程序效率骤降,sql调优变得极其困难。在我的经验中,以下情况可以违反三范式做设计。
2.5.1 不常变动的数据做适当冗余
在有些时候,数据录入到数据库中,很少做改变。比如用户的用户名,项目的code,优惠券的名称,公司的名称等。在何其关联的表中,我们可以把这些信息冗余上,可以把多数连表查询改为单表查询。不过在这些字段更新时,需要记得一起更新关联表,在SpringBoot中可以用发消息的方式进行。
2.5.2 使用级联Id
在级联Id中,有2个常见的例子。一个是鉴权中的部门系统,通常会使用一个级联code的字符串,描述从根到当前节点的全路径,比如root-eng1-dep1。这样在查询某个部门的子孙节点时可以使用like root-eng1-dep1-%。
还有一个常见的情况,就是位置信息。也就是在哪个国家,哪个省,哪个市,哪个区。我们会创建的一个Location表,并且把Id规划好,哪几位表示省,哪几位表示市,哪几位表示区。当要查找在哪个市时,只需要用相关数学运算,就可以直接用Id做查找。
2.5.3 一些明确不需要做查询的复杂字段
有些时候,有些类似备注呀,设备属性呀,收货地址信息之类的字段,很明确的知道不会用作查询,并且有较复杂的层级关系时。这时我们可以把多个属性合成一个json字段。在获取字段时主义好判空操作即可。在SpringBoot中,也支持把这种json字段直接映射成为实体。
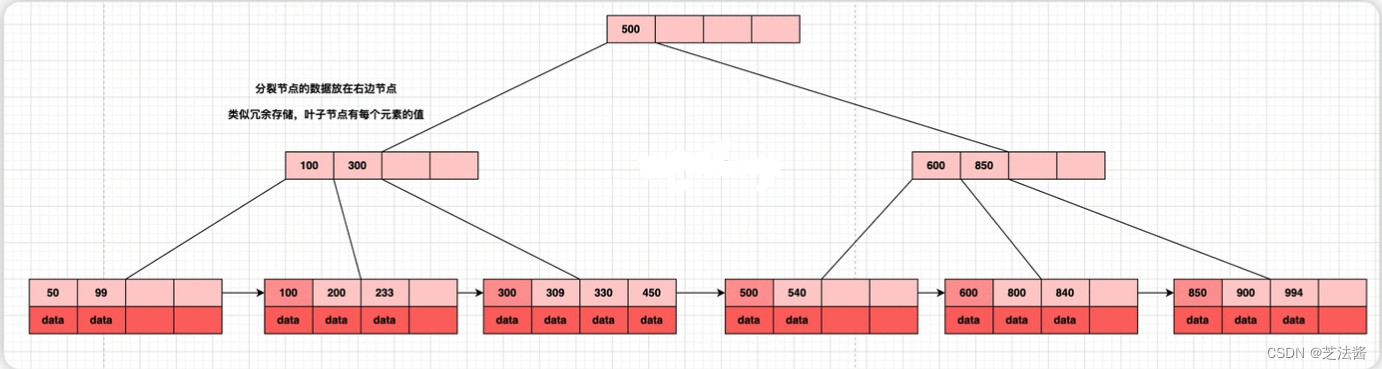
三、B树、B+树
3.1 内存中用于查找的数据结构
在内存中,我们的用于数据查找的数据结构,常常用这两种。哈希表和红黑树。
哈希表是把键算出一个哈希值,再映射到数组的某个槽中。当查找时,先计算哈希值,然后直接找到对应的槽,遍历到key值相同的元素时即可找到。这种数据结构的查找算法效率是n(1)。mysql的哈希索引,也只能在内存引擎中使用。
然而,哈希表这种数据结构,无法做排序运算,这时就需要用二叉查找树。二叉查找树保证每个节点只有2个子节点,左节点的值比自身小,右节点的值比自身大。红黑树是一个优化的二叉查找树,通过旋转等方法,使树尽可能平衡,也就让树的层数尽可能小,尽可能两边都有节点。红黑树的查找效率是lg(n)
B树与B+树
然而在数据库中,磁盘的数据读取并不是一个内存的随机访问。硬件通常一次读取一大批连续的数据。而在内存的红黑树中,一个节点才放3个数据,而磁盘一次读取可以读一个逻辑块,通常是4KB,这显然不匹配。
于是B树和B+树算法就产生了。mysql的一个节点会存放16KB的数据,并根据估算来计算每个节点存放的数据行数量。
那么,B树的定义就成了每个节点的子节点引用放在一个数组中,数组元素根据主键值有序排列。每个节点维护其处理的数据范围。
而B+数则是,只有在叶子节点存放数据,以减少回表,减少数据库IO次数。
Mysql的innodb使用的是B+树,之前的MyISAM使用的是B树,主键索引和数据分属于不同的文件。
四、Mysql的buffer pool
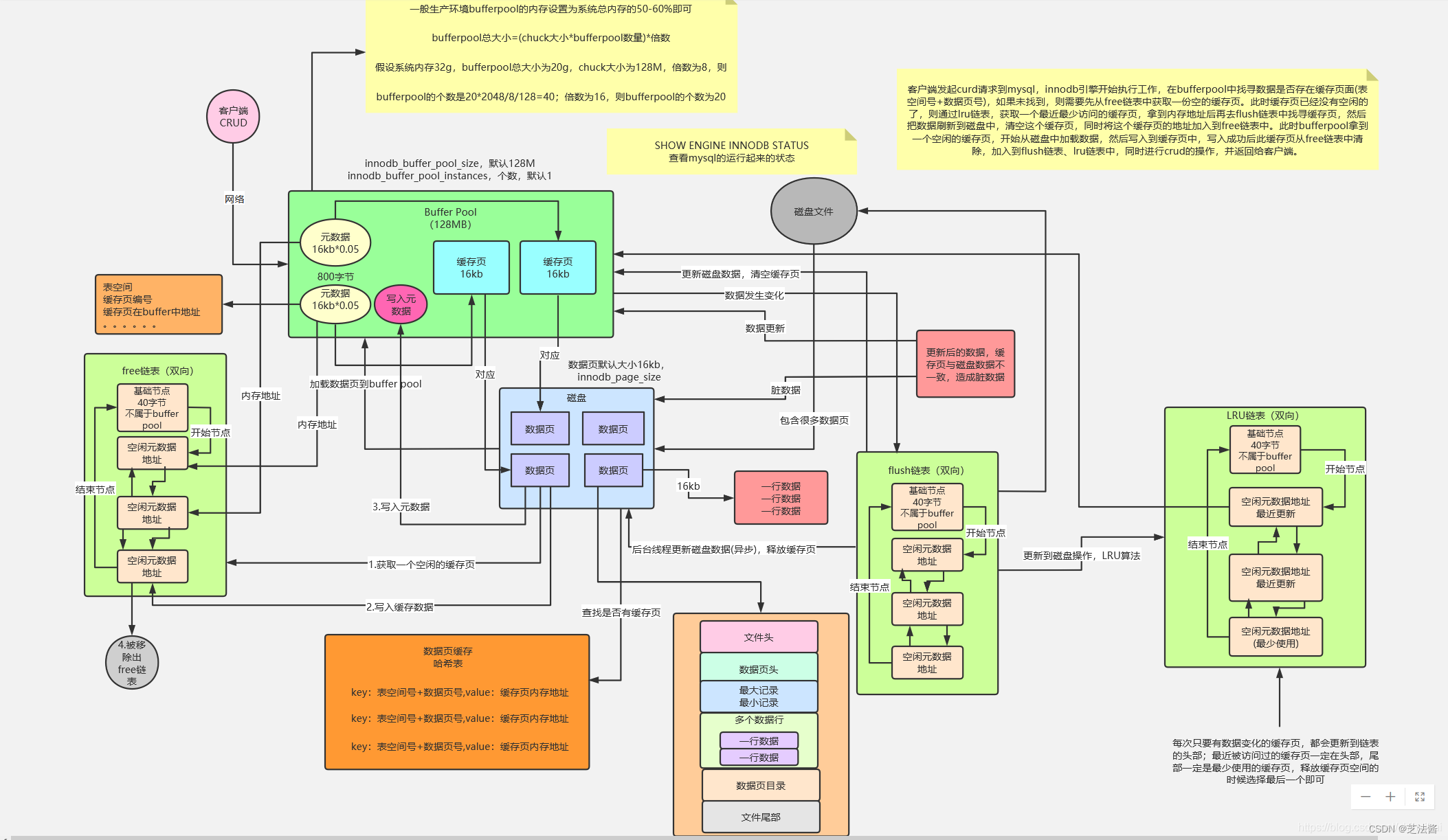
4.1 什么是buffer pool
Buffer Pool是MySQL中InnoDB存储引擎的一种内存缓存机制,用于加速对磁盘上数据的访问。具体来说,Buffer Pool是一块内存区域,其中存储了最近使用的数据页的副本,这些数据页通常是磁盘上的数据文件的一部分。在MySQL需要读取或写入磁盘上的数据时,会首先查找Buffer Pool中是否存在该数据页的副本,如果存在,则直接从内存中读取或写入数据,避免了频繁的磁盘访问。
Buffer Pool中存放的是InnoDB存储引擎的数据页,包括索引页、数据页、undo页等。其中,索引页用于存放B+树索引的节点数据,数据页用于存放表中的行数据,undo页用于存放事务回滚信息等。
Buffer Pool中存储的数据是以数据页为单位进行管理的,每个数据页的大小通常是16KB。在MySQL启动时,Buffer Pool会从操作系统中申请一块连续的内存区域作为缓存区域,并将其划分为多个数据页。当InnoDB需要访问磁盘上的数据时,它会首先查找Buffer Pool中是否存在该数据页,如果存在,则直接读取缓存中的数据;如果不存在,则从磁盘上读取该数据页,并将其存储到Buffer Pool中。
4.2 一个sql语句如何被定为到数据页上
当MySQL接收到一个SQL语句时,它会首先通过解析器将该语句分解为语法树,然后通过优化器对语法树进行分析和优化,生成一个查询计划。在生成查询计划的过程中,MySQL会根据表的统计信息、索引信息以及其他一些因素,选择最优的查询策略和执行计划。
在执行查询计划时,MySQL需要访问表中的数据页,并将其加载到Buffer Pool中。当MySQL需要访问某个数据页时,它会首先检查该数据页是否已经在Buffer Pool中缓存,如果已经缓存,则直接从Buffer Pool中读取数据;如果没有缓存,则需要从磁盘上读取该数据页,并将其存储到Buffer Pool中,然后再从Buffer Pool中读取数据。数据页中有个类似哈希表的数据结构,它使用表空间号+数据页号作为一个key,然后缓冲页对应控制块作为value。
| KEY | VALUE |
|---|---|
| 表空间+页号 | 对应控制块 |
| 表空间+页号 | 对应控制块 |
| 。。。 | 。。。 |
因此,MySQL并不需要事先知道哪些数据页可能会被使用,而是在查询执行的过程中动态地加载和使用数据页。如果某个数据页在查询过程中没有被使用,那么在Buffer Pool空间不足时,该数据页可能会被淘汰出缓存区,释放空间供其他数据页使用。
4.3 buffer pool的几个特性
- LRU算法:
Buffer Pool中的数据页会按照最近使用时间进行排序,最近使用的数据页会被优先保留在内存中,而较长时间未使用的数据页则可能会被淘汰出内存,释放空间。这种淘汰算法被称为LRU(Least Recently Used)算法。 - 预读机制:
MySQL在读取磁盘上的数据页时,不仅会读取当前需要的数据页,还会预先读取相邻的一些数据页,以便在下次查询时可以直接从Buffer Pool中读取这些数据页,提高查询性能。 - 脏页管理:
当MySQL修改一个数据页时,该页会被标记为“脏页”,表示该页的内容已经被修改但尚未同步到磁盘上。MySQL会定期将脏页同步到磁盘上,以保证数据的持久性和一致性。如果Buffer Pool中的空间不足,MySQL可能会选择先淘汰一些脏页,以腾出空间存储新的数据页。
Buffer Pool的大小是可以通过配置参数进行调整的,key值为innodb_buffer_pool_size。如果把该值大小设置的比较大,其实就可以把mysql当成一个内存数据库用。在实际开发中,我们可以把一些常访问的数据放到一个数据库服务器中,并把该服务器配置较大内存。
4.4 网上搬运的mysql innodb架构
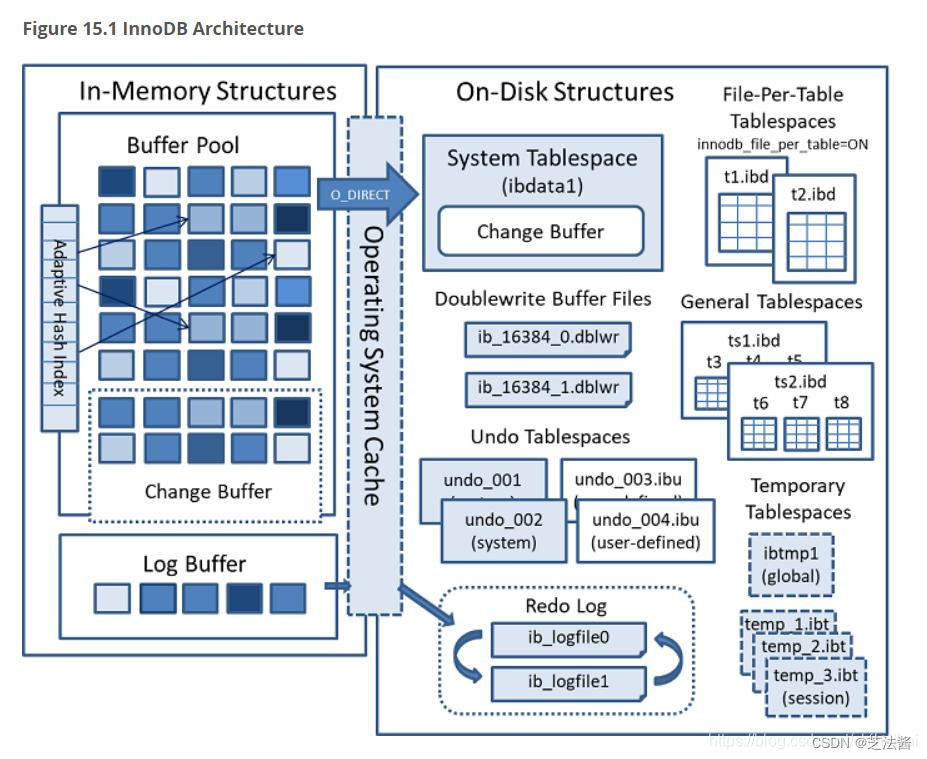
五、结语
这篇虽然是孔乙己拒止攻略,但mysql作为应用开发最多接触的中间件,确实有必要深入了解其底层原理。这样子在编码和优化时才会有更广阔的思路,对性能瓶颈也有更深刻的认识。
本篇的内容用chatgpt辅助编写,参考了一些其他人的博客,以及B站上的一篇讲mysql面试的视频


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









