







大二学生党,最近在Java学习有所体会,但广度深度不够,敬请谅解。

本文主要参照这个文档Plumber
首先需要一点基础的知识可以看我的这2篇文章
Heap的内部结构
在前文中已经说到Java的内存模型,这里在提一哈
首先看一下图(图片来源:Java垃圾回收机制)

可以看到Java的Heap分为了2个部分(其实Permanent Generation常常被人称为方法区,用于存放静态文件,如Java类、方法等),下面一一介绍:
- Eden(Young Generation):当程序中为一个对象分配内存的时候,这个对象的内存就会被分在这里。在Eden区域进一步被每个线程分割了,也就是说一个线程里面分配的内存都会在一起,而这个区域被称为 Thread Local Allocation Buffer(TLAB),有了TLAB,避免了昂贵的线程同步问题。当一个TLAB满了之后,内存就会被分配到CommonArea。当Common Area满了之后,就会触发一次GC(线程共享的资源是声明在Common Area里面的,在这里引申出一个问题:多线程对共享资源的访问与控制)。

- Survivor(Young Generation):Survivor会被分为form to,当Eden触发GC之后就会触发Mark-and-Copy算法的GC,具体参见上篇文章咯。把Eden的存活的对象拷贝带Survivor1区域,当Eden再次满了之后,就会把Survivor1与Eden的存活的对象再次拷贝到Survivor2。注意以下几点:每个对象都一个age,每进行一次GC,age就会加一。当age达到一定的值就会被Old Generation区域。或者,Young Generation满了也会copy到Old Generation。
- Tenured(Old Generation):在年轻代中经历了N次垃圾回收后仍然存活的对象,就会被放到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象。老年代对象存活时间比较长,存活率标记高。
再补充一点在Young Generation里面的GC称为MinorGC;Old Generation的GC称为MajarGC,而FullGC是Young Generation与Old Generation都会回收。
关于Old Generation咱们下面就会进行了。
概述
在Young Generation里面主要是由下面几种Collector:
- Serial
- Parallel Scavenge
- Parallel New
在Old Generation里面主要是由下面几种Collector:
- Serial Old
- Parallel Old
- CMS
上面这6个可以简单的分为Serial,Parallel ,CMS3种,所以下面就详细的讲解一番。
Serial GC
Serial GC在young generation采用make-copy算法(也就是Serial),在old generation采用make-sweep-compact算法(也就是Serial Old)。同时对于每一个阶段,都会采用单线程进行处理。所以在多核CPU,Serial GC并没有占据优势,但是在配置较低,比如单核的机器上,基本都是采用Serial GC的。

MinorGC
在Plumber的文档里面是这样试验的:
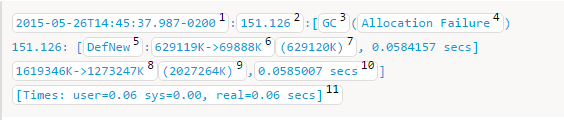
- GC开始的绝对时间
- GC开始相对于JVM开始的时间
- 用于区分GC的(暂时不解释,看到后面就自然清楚了)
- GC的原因,这里是因为为对象分配空间失败导致的
- GC的名字
- Young Generation的内存变化情况
- Young Generation的大小
- heap的内存变化情况
- heap的大小
- GC的所花费的时间
- 这里有三个时间:user:GC线程在CPU运行的时间;sys:系统进行函数调用等时间,这个时间一般比较短;real:其实就是Application线程阻塞的时间,也就是GC真正的时间。
heap的减少量小于Young Generation的减少量,也就是说有部分内存被系统Copy到Old Generation了。
Full GC
和MinorGC一样:
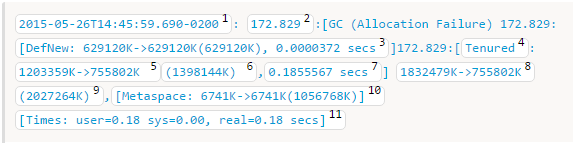
只需要注意一点:这里有个bug,第三个应该改为:629120k -> 0,是可以经过计算推出来的。
Parallel GC
对于Serial GC的单线程,显然满足不了现代的机器,所以就出现多线程来处理GC了。
首先我们要区分以下2个概念:Parallel与Concurrent,也就是我们常说的并行与并发。Parallel:指多个的进程都会在同一时刻运行,并行只有在多核CPU机器才可以进行,单核不能再同一时刻运行多个线程;Concurrent:多个进程可以在同一时间间隔运行,也就是CPU进行进程的切换,举个栗子就是在一秒钟内,CPU进行不断的切换,人的感觉就像在同时运行一样。(要是还不懂就去看操作系统的知识吧!!)
Parallel GC在Young Generation采用mark-copy算法,在OldGeneration采用make-sweep-copy。所有的算法都是Parallel的,所以称为Parallel GC。

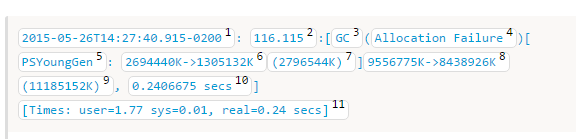
Plumber的里面这样说明:
Minor GC
Full GC
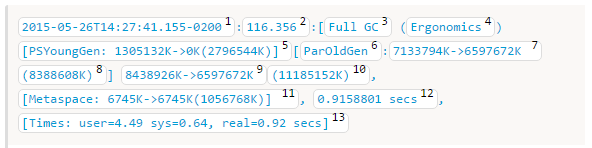
主要注意一点:由于采用多线程,所以real >= (user + sys)/threadNum;这里线程数为8。其他的数据和SerialGC一样一样的,可以对照着看
CMS
接下来,就是重点了。CMS全面叫“Mostly Concurrent Mark and Sweep Garbage Collector”,也叫Concurrent Mark and Sweep。在Young Generation采用并行(parallel)的mark-copy算法,Old Generation采用并发(concurrent)的mark-sweep算法。
首先我们看看怎么实现的,再看看性能比较。
MinorGC
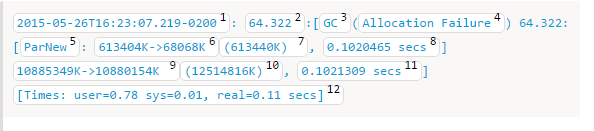
对于(5)还是要说一哈:ParNew,也就是Parallel New,表示了在Young Generation使用了parallel mark-copy stop-the-world GC。
在Minor使用了ParNew,与在Old Generation相结合,也就是今天我们所说的重点。
(12)这个时间和我们前面说的时间也是一样的,采用8个线程进行处理。
Full GC
前面几个GC的Full GC,都是比较简单的,但是这次却是异常的复杂。
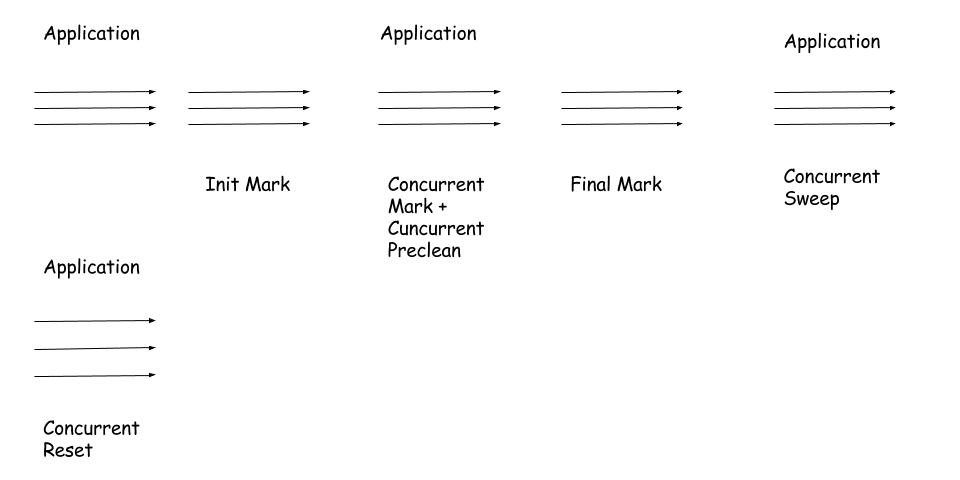
根据前面的图,我们一步步的理解:
Init Mark:在这个阶段,应用程序进程是停下来的,也就是说stop-the-world。GC遍历Old Generation里面的所有root set,找到所有的root节点。Concurrent Mark:首先注意这是和应用程序并发进行的。在这个阶段,从Init Mark遍历得到的root节点开始,层次向下遍历,标记所有能够到达的节点。Concurrent Preclean:上面的过程看似可以把所有的节点都遍历完,但是由于是并发执行的,就会在遍历过程中新分配一个对象的存储空间,所以这个过程就是找到这些新分配的对象,也被称为dirty object(这些对象都会存在一个Set里面),并把这些对象标记为live状态(不管这些对象是否真的为live状态,也就是说有错误的标记对象 ),为下一步做出准备。Final Mark:上面一步说了,这个过程就是停下应用程序,来在所有已经标记过得对象中剔除标记错的对象。Concurrent Sweep:并发的Sweep所有被标记的对象。Concurrent Reset:重置一些数据,为下一次GC做出准备。
这个过程大概就是这样,我们要注意以下几点:
- 一般并发处理的时候,默认的GC线程是机器内核数量的1/4,至于为啥,我也不是很清楚。// Todo:思考一哈。。。。
- 由于算法是并发进行处理的,也就是应用程序不会停止,所以系统的响应时间减少了(准确的说是:延时(latency)减少了),但是CPU的负荷增大了。同时由于应用程序的线程减少,导致吞吐量(thoughtput)也减少了。
- CMS为高并发、低停顿,追求最短GC回收停顿时间,cpu占用比较高,响应时间快,停顿时间短,多核cpu 追求高响应时间的选择。
Garbage First(G1)
G1算法Java7提出的。G1算法和CMS有相似之处,也有不同,下面一起来看看。
首先对于G1算法,heap区域不再是连续的了,而是被切割为很多的块(严格的说是regions),每一个块可以是Eden,Suvrvivor,或者Old Generation的一种。可以参照下面的图片(来源):

拓展延伸:Slab内存分配算法(学习PHP看到的),与上面的思想差不多。
G1垃圾收集器维护了2个数据结构,这里先看看Collection Sets,这个集合里的内容就是GC要收集的内容,从而避免了遍历所有的heap。而这些内容包括部分Old Generation的的对象和全部Young Generation的内容。(来源)

下面我们看看具体的步骤:
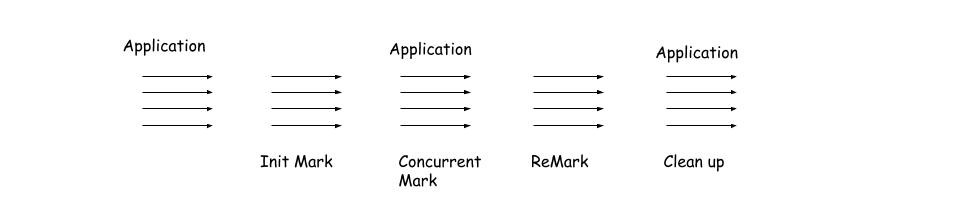
Init Mark:在这个阶段和CMS的过程差不多,标记所有的Root Set里面的东西;Concurrent Mark:大致部分和CMS的内容一样,也是从Root Set出发,标记所有可达的节点。不同的是,G1在标记的过程中,会计算每个Region的存活率(就是这个区域的Garbage多不多啦)ReMark:对于CMS的Final Mark的过程差不多。但是G1运用了snapshot-at-the-beginning(SATB)算法,比CMS使用的算法快很多。并且会回收空区域。Clean up:先清除存活率低的区域,在清理Remembered Set(后面再说)
注意一点:在Concurrent Mark区域会标记计算每个的Region的存活率,然后再Clean up阶段先清除存活率低的区域,这就是Garbage First 的原因。
关于上文说的Remembered Sets是什么?有什么用?下面进行解释:
由于G1算法把heap分成了许多的区域,这就导致了一个问题,如果引用在不同的区域存在该怎么办(Cross-Region,比如,在Region A里面有个对象引用了在B里面的一个对象),所以对于每一个Region都会维护一个Remembered Sets,在这里存储所有Cross-Region的引用。
为了维护这些RSets,在对Region执行写操作的时候,如果一个引用是Cross-Region的,那么就会有个Write Barrier中断写操作,把Cross-Region的信息用CardTable加入RSets里面去。(//Todo: 好吧,这段我也不是很明白)
最后在说一哈:用户可以制定GC打断应用程序的时间,但G1是一个软实时系统(soft real-time)。
可以这样设置:
-XX:+UseG1GC——让JVM使用G1垃圾回收器
-XX:MaxGCPauseMillis=200——设置GC暂停时间目标值,缺省200毫秒。但这不是硬指标,JVM会尽力满足。
-XX:InitiatingHeapOccupancyPercent=45——整个堆被占用多少之后开始进行GC,缺省为45,0表示持续不停进行GC
-XX:NewRatio=n——年轻代和老年代的比例,缺省为2
-XX:SurvivorRatio=n——Eden和Survivro的比例,缺省为8
-XX:G1ReservePercent=n——保留的堆大小,减少晋升过程中出错的可能性,也就是增加可用的to-space内存,缺省是10
-XX:G1HeapRegionSize=n——G1中,堆分为大小相等的区域。这个参数设置区域的大小,缺省值取决于堆的总大小,有效取值是1M-32M。好吧,就这些了,以后等我升级了在说。
七:各个算法比较
这部分,还没有真正的弄过,所以对不住各位了。// Todo















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









