Dataset&DataFrame介绍
- Dataset是特定领域对象的强类型分布式数据集合
- 与RDD类似,Dataset的操作分为transformation和action两类,只有调用action操作时,才会触发transformation类计算操作
- Dataset内部包括Encoder,负责特定领域对象到spark内部类型系统的序列化和反序列化(即把领域对象转换为关系表的行列格式)
- DataFrame是数据类型为Row的Dataset(Dataset[Row])
sql到Dataset
sql解析流程
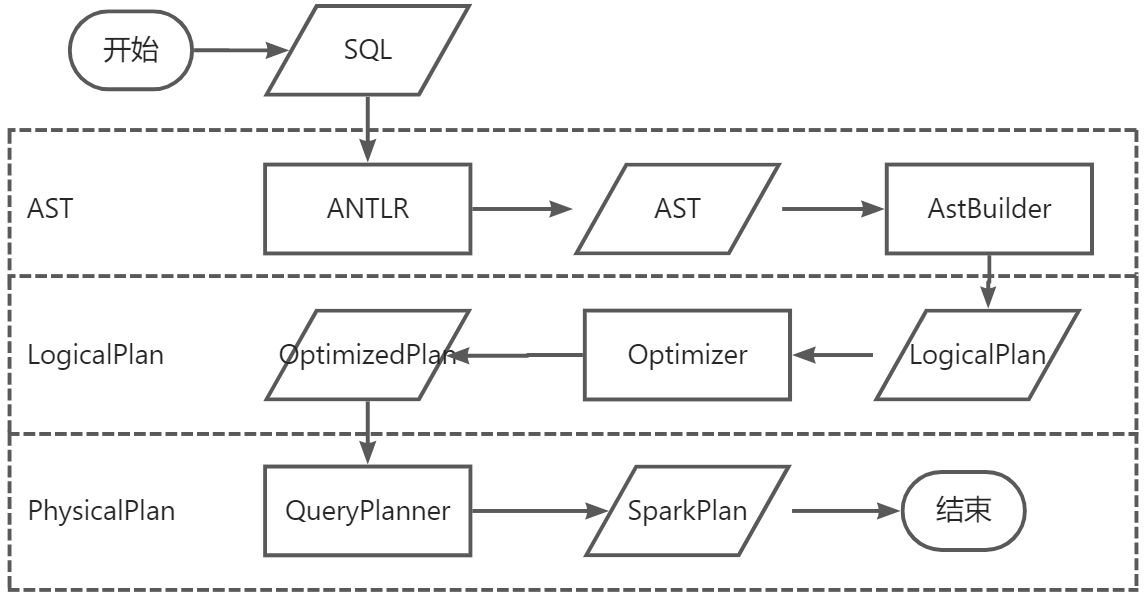
- sql语句通过antlr进行词法和语法分析后形成抽象语法树
- antlr运行时,提供了监听器和访问者模式实现对生成的语法树进行遍历,监听器自动进行,而访问者模式需要调用visit方法来访问节点
- AstBuilder扩展了antlr 生成的默认访问者模式实现类,从而实现从抽象语法树到LogicalPlan的转换
- LogicalPlan被优化后通过QueryPlanner转换成物理执行计划(SparkPlan)
LogicalPlan&SparkPlan
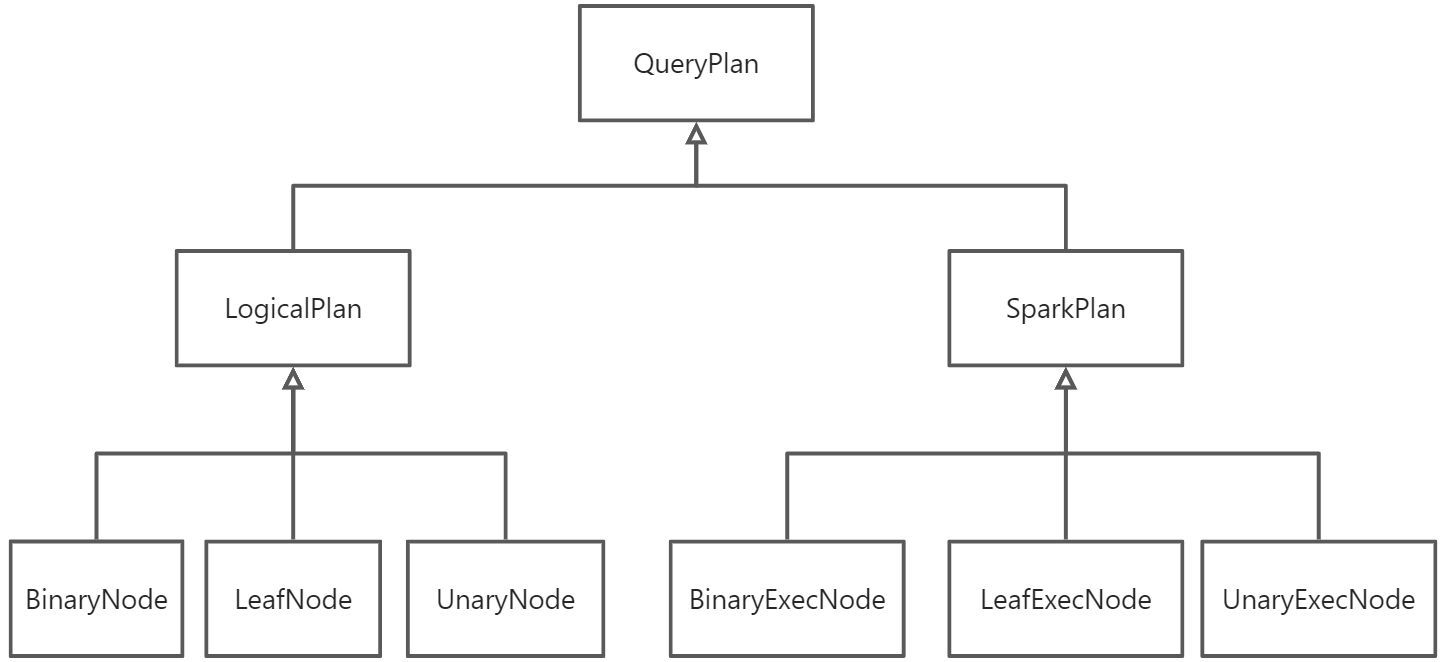
- LogicalPlan和SparkPlan都是树形结构
- 包括叶子节点(LeafNode、LeafExecNode)、单亲节点(UnaryNode、UnaryExecNode)、双亲节点(BinaryNode、BinaryExecNode)三种节点类型
Dataset生成
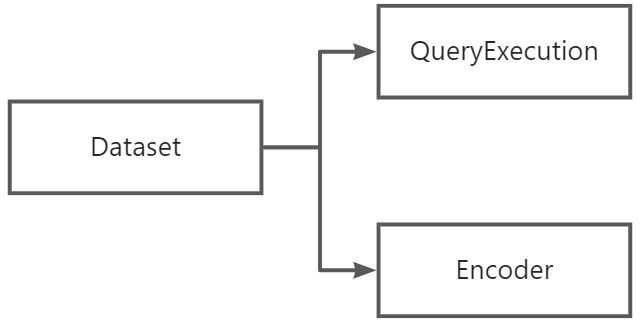
- sql被解析成LogicalPlan后会被封装成QueryExecution
- QueryExecution负责管理LogicalPlan的优化以及到物理计划的转换
- 每个Dataset除了携带Encoder(负责领域对象到内部类型系统的序列化和反序列化)之外,还包括描述计算的LogicalPlan
- Dataset生成之后,只有在调用action类方法时才会触发计算
def sql(sqlText: String): DataFrame = {
Dataset.ofRows(self, sessionState.sqlParser.parsePlan(sqlText))
}
def ofRows(








 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3023
3023











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









