







通过之前对 JAVA基础 —— 集合 的学习,我们对于集合的概念以及ArrayList都有了初步的了解。
| Collection单列集合 | JAVA基础(集合进阶) —— Collection单列集合 |
| List集合 | JAVA基础(集合进阶) —— List集合 |
| 泛型 | JAVA基础(集合进阶) —— 泛型 |
| Set集合 | JAVA基础(集合进价) —— Set集合 |
接下来我们将整体的了解集合的体系结构。
目录
Set系列集合:
- 无序:存取顺序不一样
- 不可重复:可以去除重复
- 无索引:没有带索引的方法,所以不能使用普通for循环遍历,也不能通过索引来获取元素。
Set集合的实现类:
- HashSet:无序、不重复、无索引
- LinkedHashSet:有序、不重复、无索引
- TreeSet:可排序、不重复、无索引
Set接口中的方法上基本上与Collection的API一致 ,所以在Set集合中没有额外方法,详细见Collection常用方法。
public class SetTest {
public static void main(String[] args) {
// 1.创建Set集合对象
Set<String> s = new HashSet<>();
// 2.添加元素
// 如果当前元素是第一次添加,那么可以添加成功,返回true
// 如果当前元素是第二次添加,那么添加失败,返回false
s.add("张三");
s.add("李四");
s.add("王五");
// 3.打印集合
// 无序
System.out.println(s); // [李四, 张三, 王五]
// 迭代器遍历
Iterator<String> it = s.iterator();
while (it.hasNext()) {
String str = it.next();
System.out.println(str);
}
// 增强for
for (String str : s) {
System.out.println(str);
}
// lambda表达式
s.forEach(str -> System.out.println(str));
}
}一、HashSet
HashSet底层原理:
- 无序、不重复、无索引
- HashSet集合底层采取哈希表存储数据。
- 哈希表是一种对于增删改查数据性能都较好的结构。
哈希表组成:
- JDK8之前:数组+链表
- JDK8开始:数组+链表+红黑树
1. 哈希值
- 概括hashCode方法算出来的int类型的整数
- 该方法定义在Object类中,所有的对象都可以调出,默认使用地址值进行计算
- 一般情况下,会重写hashCode方法,利用对象内部的属性值计算哈希值

对象的哈希值特点:
- 如果没有重写hashCode方法,不用对象计算出的哈希值是不同的。

- 如果已经重写hashCode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的。

- 在小部分情况下,不同的属性值或者不同的地址值计算出来的哈希值也有可能一样。(哈希碰撞)
public class HashSetTest {
public static void main(String[] args) {
// 创建对象
Student s1 = new Student("zhangsan", 23);
Student s2 = new Student("lisi", 24);
Student s3 = new Student("wangwu", 25);
// 1.如果没有重写hashCode方法,不用对象计算出的哈希值是不同的。
System.out.println(s1.hashCode()); // 2018699554
System.out.println(s2.hashCode()); // 1311053135
// 2.如果已经重写hashCode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的。
System.out.println(s1.hashCode()); // -1461067292
System.out.println(s2.hashCode()); // -1461067292
// 3. 在小部分情况下,不同的属性值或者不同的地址值计算出来的哈希值也有可能一样。
System.out.println("abc".hashCode()); // 96354
System.out.println("bcD".hashCode()); // 96354
}
}
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int hashCode() {
return Objects.hash(name,age);
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null || getClass() != obj.getClass())
return false;
Student student = (Student)obj;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
}
2. HashSet底层原理

- 创建一个默认长度16,默认加载因子为0.75的数组,数组名为table 。

- 根据元素的哈希值跟数组的长度计算出应存入的位置。

- 判断当前位置是否为null,如果是null直接存入。
- 如果位置不为null,表示有元素,则调用equals方法比较属性值。
-
一样: 不存
- JDK8以后,当链表长度超过8,而且数组长度大于等于64时,会自动转换成红黑树。
- 如果集合中存储的是自定义对象,必须重写hashCode和equals方法。
3. 练习: 利用HashSet集合去除重复元素
需求:创建一个存储学生对象的集合,存储多个学生对象。
使用程序实现在控制台遍历该集合。
要求:学生对象的成员变量值相同,我们就认为是同一个对象。
public class HashSetTest {
public static void main(String[] args) {
// 创建三个对象
Student s1 = new Student("zhangsan", 23);
Student s2 = new Student("lisi", 24);
Student s3 = new Student("wangwu", 25);
Student s4 = new Student("zhangsan", 23);
//2.创建集合用来添加学生
HashSet<Student> hs = new HashSet<>();
//3.添加元素
//重写hashCode和equals方法
System.out.println(hs.add(s1)); //true
System.out.println(hs.add(s2)); //true
System.out.println(hs.add(s3)); //true
System.out.println(hs.add(s4)); //false
//4.打印集合
System.out.println(hs);
//[Student [name=wangwu, age=25], Student [name=lisi, age=24],
// Student [name=zhangsan, age=23]]
}
}
二、 LinkedHashSet
LinkedHashSet底层原理:
- 有序、不重复、无索引
- 这里的有序指的是保证存储和取出的元素顺序一致
- 原理:底层数据结构依然是哈希表,只是每一个元素又额外的多了一个双链表的机制去记录存储的顺序。
在以后如果要数据去重,我们使用哪一个?
默认使用HashSet,如果要求去重且存在有序,才使用LinkedHashSet。
public class LinkedHashSetTest {
public static void main(String[] args) {
// 创建三个对象
Student s1 = new Student("zhangsan", 23);
Student s2 = new Student("lisi", 24);
Student s3 = new Student("wangwu", 25);
Student s4 = new Student("zhangsan", 23);
// 2.创建集合用来添加学生
LinkedHashSet<Student> lhs = new LinkedHashSet<>();
// 3.添加元素
// 重写hashCode和equals方法
System.out.println(lhs.add(s1)); // true
System.out.println(lhs.add(s2)); // true
System.out.println(lhs.add(s3)); // true
System.out.println(lhs.add(s4)); // false
// 4.打印集合
System.out.println(lhs);
}
}三、 TreeSet
TreeSet的特点:
- 不重复、无索引、可排序
- 可排序:按照元素的默认规则(由小到大)排序。
- TreeSet集合底层是基于红黑树的数据结构实现排序的,增删改查性能都比较好。
public class TreeSetTest {
public static void main(String[] args) {
// 创建TreeSet集合对象
TreeSet<Integer> ts = new TreeSet<>();
// 添加元素
ts.add(4);
ts.add(5);
ts.add(1);
ts.add(3);
ts.add(2);
// 打印集合
System.out.println(ts); // [1, 2, 3, 4, 5]
// 遍历集合(三种遍历)
// 迭代器遍历
Iterator<Integer> it = ts.iterator();
while (it.hasNext()) {
Integer i = it.next();
System.out.println(i);
}
// 增强for遍历
for (Integer it1 : ts) {
System.out.println(it1);
}
// lambda表达式遍历
ts.forEach(it2 -> System.out.println(it2));
}
}
1. TreeSet集合默认的规则
- 对于数组类型:Integer、Double,默认按照从小到大的顺序进行排序。
- 对于字符、字符串类型:按照字符在ASCII码表中的数字升序进行排序。
练习: TreeSet对象排序
需求:创建TreeSet集合,并添加3个学生对象。
学生对象属性:姓名,年龄。
要求按照学生的年龄进行排序。
同年龄按照姓名字母排列(暂不考虑中文)
同姓名,同年龄认为是同一个人。
public class TreeSetTest {
public static void main(String[] args) {
//方案一: 默认排序/自然排序
//Student实现Comparable接口:重写里面方法,指定比较规则
// 创建三个学生对象
Student s1 = new Student("zhangsan", 23);
Student s2 = new Student("lisi", 24);
Student s3 = new Student("wangwu", 25);
//创建集合对象
TreeSet<Student> ts = new TreeSet<>();
ts.add(s1);
ts.add(s2);
ts.add(s3);
System.out.println(ts);
//hashCode equals 和哈希表有关
//但是TreeSet底层是红黑树
}
}
//Student.java
public class Student implements Comparable<Student>{
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
@Override
public int compareTo(Student o) {
//指定排序规则
//只看年龄 升序排列
int result = this.getAge() - o.getAge();
return result;
}
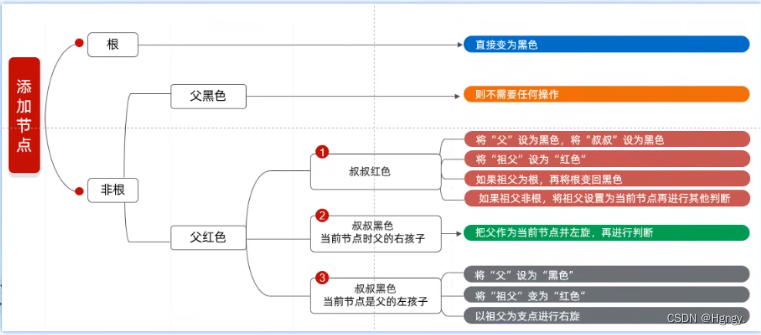
}
2. TreeSet的两种比较方式
- 方案一: 默认排序/自然排序: JavaBean类实现Comparable接口指定比较规则
- 方案二: 比较器排序: 创建TreeSet对象的时候,传递比较器Comparator制定规则。
使用原则:默认情况下使用第一种,如果第一种不能满足当前需求,就是用第二种。


练习:TreeSet对象排序
需求:请自行选择比较器排序和自然排序两种方式;
要求:存入四个字符串,“c" , "ab" , “df” , "qwer"
按照长度排序,如果一样长则按照首字母排序
public class TreeSetTest {
public static void main(String[] args) {
//第二种排序方式:比较器排序
//创建TreeSet对象的时候,传递比较器Comparator制定规则
//创建集合
TreeSet<String> ts = new TreeSet<>(new Comparator<String>() {
//o1:表示当前要添加元素
//o2:表示已经在红黑树中存在的元素
@Override
public int compare(String o1, String o2) {
//按照长度排序
int i = o1.length() - o2.length();
//如果一样长则按照首字母排序
i = i == 0 ? o1.compareTo(o2) : i ;
return i;
}
});
//添加数据
ts.add("c");
ts.add("ab");
ts.add("qwer");
ts.add("df");
//打印集合
//重写前
System.out.println(ts); //[ab,c,df,qwr]
//重写后
System.out.println(ts); //[c, ab, df, qwer]
}
}四、 使用场景
1.如果想要集合中的元素可重复
- 用ArrayList集合,基于数组的。(用的最多)
2.如果想要集合中的元素可重复,而且当前的增删操作明显多于查询
- 用LinkedList集合,基于链表的。
3.如果想对集合中的元素去重
- 用HashSet集合,基于哈希表的。(用的最多)
4.如果想对集合中的元素去重,而且保证存取顺序
- 用LinkedHashSet集合,基于哈希表和双链表,效率低于HashSet。
5.如果想对集合中的元素进行排序
- 用TreeSet集合,基于红黑树。后续也可以用List集合实现排序。
















 3622
3622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











