







目录
一、集合
1、基本概念
数据结构中讨论的集合,一般有以下限制:
1)限制为有穷集;
2)所有元素属同一类型;
3)元素之间存在一个小于关系(有序集)。

2、集合的抽象数据类型

3、集合的表示
3.1、位向量表示
位向量是一种每个元素都是二进制位(即0/1值)的数组。当表示的集合存在某个不太大的公共超集时,采用位向量的方式来表示这种集合往往十分有效。
(使用位向量表示的集合的操作会涉及很多的位操作,有需要再补充)
typedef struct{
int size; //字符数组长度
char* array; //位向量空间,每一组元素保存8位
}BitSet;【注】存储结构比较简单,但是还有一个表示的细节需要考虑:在一个字符空间中,位向量元素的下标应该如何排列?一种自然的想法是,字符的8位从左至右下标递增排列。但是这种排列给集合类型的许多操作带来不便,所以选择了相反的排列。

二、字典
1、概念及存储方式
字典是一种集合,其中每个元素由两部分组成,分别称为关键码和属性(也称为值)。这种包含关键码和属性的二元组称做关联( association)。字典中的元素之间能够根据其关键码进行比较大小,对字典元素的插入、删除和检索等操作一般也以关键码为依据进行。

2、评价标准(ASL)

3、抽象数据类型(ADT)

4、字典的顺序表示
4.1 顺序检索算法
不难发现,该检索算法与求顺序表中某元素的下标类似。



4.2 二分检索
-与折半查找算法相同,先将字典的key按大小排序再折半查找
-只适用于顺序存储
-效率高于顺序检索
4.3 时间复杂度分析
4.3.1 顺序检索

4.3.2 二分检索
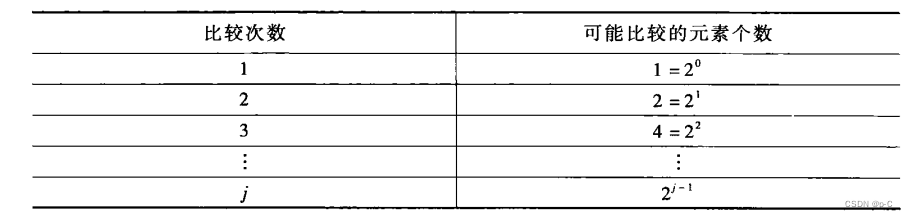
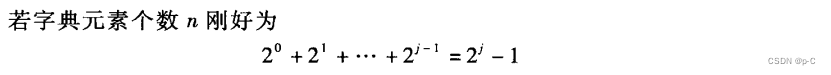

5、字典的散列表示
5.1 基本概念
- 散列表示就是通过散列函数将关键码转化为存储地址。
-装填因子 = 关键码数量 / 散列地址空间长度
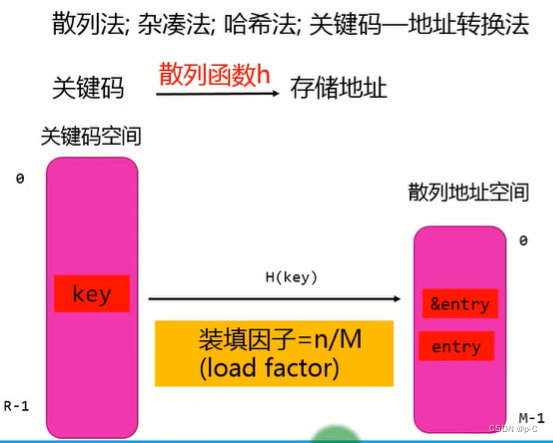
5.2 散列函数的确定
5.2.1 除余法
最常用的方法,h(key) = key mod m, m一般是取不大于基本区域长度的最大素数
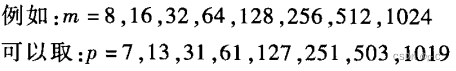
5.2.2 数字分析法
5.2.3 中平方法
5.2.4 基数转换法
5.3 散列表的碰撞以及解决方法
5.3.1.碰撞
用散列函数h计算得到多个相同的散列地址(即h( key1 ) = h( key2)),这种现象称为碰撞
5.3.2 重要概念:负载因子α
理想的负载因子应该大于 1/2。题目一般给出α,然后求出除余法的除数 m = 不大于基本区域长度的最大素数,用除余法确定散列函数
h(key) = key mod m

5.3.3 解决冲突的方法(线性探查&&二次函数探查&&双散列探查&&拉链法)

1)线性探查
不行就下一个
2)二次函数探查
3)双散列探查

4)拉链法
建立m条链表,将所有关键字为同义词的记录存储在同一条线性链表中.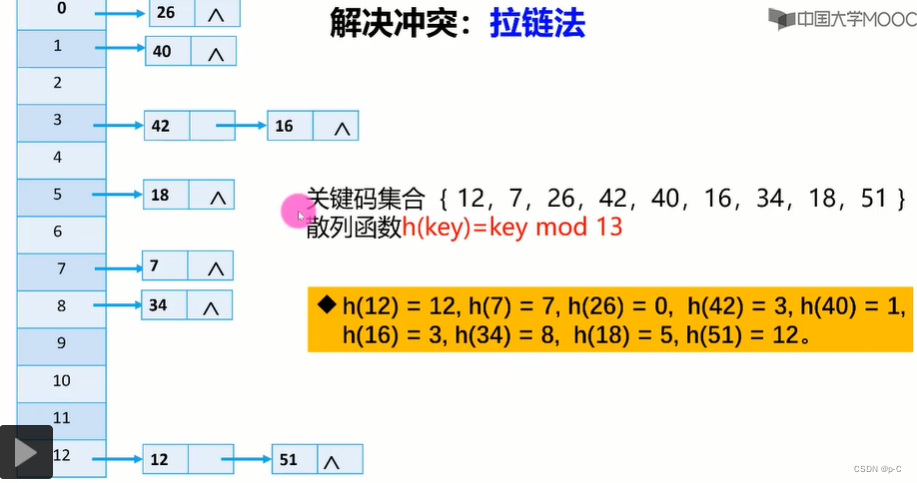
![]()
5.4散列表示的相关操作(查找、删除、插入)
5.4.1 查找
-线性探查:遇到同义词冲突时按顺序查找下一个散列地址,直到查到散列地址空间为空,则查找失败
-双散列探查

5.4.2 删除
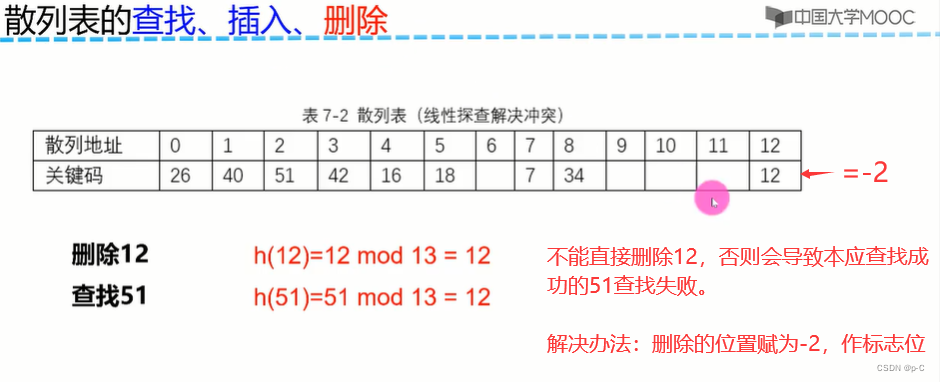
5.4.3 插入

















 8984
8984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









