







1.Hibernate和Mybatis的区别
Hibernate现在是主流框架,谁也不可否认,我也用,同样作为优秀的ORM框架Ibatis虽然不如Hibernate强势但也有着自己的市场竞争力,下面总结下Hibernate与Ibatis之间的区别:
1、封装上的区别
同样作为ORM对象关系映射框架,Hibernate对数据库表与java对象实体之间的映射有着完美的封装。实体类名与数据库表名、实体类成员变量与数据库字段都是一一对应的,还有与其他表之间的映射关系,就连字段的长度也在Hibernate的配置文件中配置了。
而且Hibernate可以自动生成sql语句并调用JDBC执行。
而Ibatis呢,Ibatis封装的是sql语句需要的参数与返回的结果 和 数据库表的字段的对应映射,Ibatis的sql语句需要程序员自己完成。
很显然,使用Hibernate框架开发会在开发效率以及代码简介的程度上压过Ibatis一头。但话说回来,存在就有存在的道理,Ibatis侧重的是sql的灵活掌控。
2、灵活性上
接着上文说,Ibatis对sql的灵活程度是优于Hibernate的,其实Ibatis就是牺牲了开发效率和数据库的可移植性来换取了sql的灵活应用,对于善于数据库编程的程序员,还是比较不错的选择。
还有一方面,有的系统数据量庞大、对性能要求很高,这个时候我们就应该选择Ibatis,因为我们可以对sql进行更加细粒度的优化。
在一方面,有的项目涉及到保密,开发过程中不会让程序员知道数据库的数据结构,这个时候选择Ibatis要比Hibernate方便的多。
3、数据库的可移植性
不用说,我们在Ibatis项目中写的sql语句的语法肯定是针对某一种数据库的,换了数据库指定不好使。对于Hibernate来说就不会出现这个问题了。
4、学习成本上
Hibernate入门门槛高,想要精通更难,Ibatis入门门槛低,容易上手。团队中没有Hibernate高手的话最好还是选择Ibatis,否则没等你体会到Hibernate的方便之处你就被他的复杂的OR映射折磨死了。
5、Hibernate文档方面要比Ibatis健全的多。
2.Mybatis的sqlMapConfig.xml配置文件
batis的配置文件通常命名为sqlMapConfig.xml ,但不是绝对的,只是通常习惯的命名。
sqlMapConfig.xml中就是包含了一些元素,有着不同的作用,分别说一下:
1、<properties>元素 用于引入标准java属性文件的。
引入的文件可以是相对的类路径,也可以是绝对路径< properties resource="cofig/jdbc.properties"/> <properties resource="file:///c:/config/jdbc.properties">.
我是一直没用到,现在Ibatis通常都和Spring整合在一起,数据源和事物管理都是在spring中进行管理的。
2、<typeAlias>元素 。 这个用的比较多,就是给java全类名起别名的。Ibatis也为我们封装了几个,例如JDBC、JTA、string 、map、int等。
<typeAlias alias="roleDto" type="com.glkj.role.dto.RoleDto" />
注意这个别名是全局的。
3、<setting>元素。看图吧:

前三个属性不必说,一看就明白 ,自己根据不同的情况进行设置。
缓存 和 延迟加载 以及字节码加强那个后面都专门说,这里略过。
4、<sqlMap>元素
就是用来引入其他配置文件的,跟struts2中的<include> 和spring配置文件中的<import>功能是一样的。
struts2中的: <include file="struts_manager.xml"/>
spring中的: <import resource="applicationContext_manager.xml" />
Ibatis中的 : <sqlMap resource="com/bh/chc/system/select/Select.xml"/>
5、至于其他的元素 例如配置数据源的、配置事务管理的就不说了,现在这活都归spring负责了。
3.Mybatis基本SQL语句
- <span style="font-family: Arial, Helvetica, sans-serif;">Ibatis映射文件中,首先要指定一个命名空间来代表自己</span>
<sqlMap namespace="xuesheng"></sqlMap>
1、在<sqlMap>元素内包含的就都是一些sql语句了,这些sql语句是由不同的元素“包裹”起来的,这些元素有<select> <insert> <update> <delete> <procedure>。 看这些元素名
字就知道他们分别是用来包裹哪一类sql语句的。还有一个元素<statement> 这个元素是通用的,可以包裹任意的sql语句,但是不怎么招人待见,反正我是一次没用过,据说他
也不是完全通用(据官方文档说 的) ,有些特性在这个元素下还是不好使的,例如<insert>元素下可以有<selectKey>元素,换成<statement>就不好使。
说到这个主键,我平时用sql server 做添加操作的时候并且主键还是自增长类型的我就在数据库里设置,用oracle的时候就用 seq_tableName.nextnvl 获取,一般不用他提供
的那个<selectKey>多折腾一下。
但也查了下用的时候该怎么用:
- <!-- Oracle SEQUENCE -->
- <insert id="insertProduct-ORACLE" parameterClass="com.domain.Product">
- <selectKey resultClass="int" keyProperty="id" type="pre">
- <![CDATA[SELECT STOCKIDSEQUENCE.NEXTVAL AS ID FROM DUAL]]>
- </selectKey>
- <![CDATA[insert into PRODUCT (PRD_ID,PRD_DESCRIPTION) values(#id#,#description#)]]>
- </insert>
- <!— Microsoft SQL Server IDENTITY Column Example -->
- <insert id="insertProduct-MS-SQL" parameterClass="com.domain.Product">
- insert into PRODUCT (PRD_DESCRIPTION)
- values (#description#)
- <selectKey resultClass="int" keyProperty="id" >
- SELECT @@IDENTITY AS ID
- </selectKey>
- </insert>
- <!-- Mysql 这个例子测试了,可以用-->
- <insert id="insertProduct-Mysql" parameterClass="com.domain.Product">
- insert into PRODUCT(PRD_DESCRIPTION)
- values (#description#)
- <selectKey resultClass="int" keyProperty="id">
- SELECT LAST_INSERT_ID()
- </selectKey>
(1)、首当其冲的就是sql语句结束之后不要写分号
(2)、Ibatis不支持sql语句中的某些特殊字符 例如> < 需要用<![CDATA[ ]]>将那部分包起来。
(3)、查询的字段一定要跟resultClass或者resultMap中的字段名称对应上,如果字段名字不对应,请 as 起别名。
(4)、## $$ 两种引用参数的方式是有区别的:
$$ 的实际作用是进行字符串拼接 等效于StringBuffer类的append方法。
## 的作用是用来做变量替换的。
举几个开发中遇到的例子:
A、
String tableName=t_apply;
select * from $tableName$ 这里就是拼接了一个字符串吗,这种情况下用##是会报错的,因为##只用来做变量替换的。
B、
String idStr="1,2,3,4,5";
select * from tableName where id in ($idStr$) 这里用## 也会报错 你用##的话他会把idStr的值当成一个
C、
String sql="select pid from t_table where t_table_id=1"
select * from tableName where id=($sql$) 这里你用##同样会报错的
说白了 ##里面传的字符串值到了数据库里是带着单引号的,$$传递的字符值到了数据库里 不会再加个单引号
也就是说A例子中如果用了## 那么执行的sql语句将是 select * from 't_applu' 想想 能用吗?
$$传参数会带来sql注入的问题 , 不需要用的时候千万别用。
(5)、突然想起来Ibatis的一个bug,不是关于写sql方面的,刚想起来就先放在这里了:
sqlMapConfig.xml中 引入映射文件的时候一定要注意顺序, 例如A映射文件中用到了B映射文件的内容 ,那么A一定要放在B的下面,否则启动程序报错,不信你去试一下。
(6)、写sql的时候给表起别名的时候有时候会加个as 例如 select a.* from apply as a 这句话在sql server 和 Mysql中都支持 ,在Oracle中竟然不支持,Oracle中给字段
起别名可以用as 给表起别名不可以用 就是select a.* from apply a; 想了一想应该是为了与存储过程、函数、视图中的as关键字进行区别,也是猜测。
先写到这 ,以后想到了再补充。
4.Mybatis分页机制的缺陷
我们知道,Ibatis为我们提供了可以直接实现分页的方法
queryForList(String statementName, Object parameterObject, int skipResults, int maxResults)
参数:
statementName :要调用的statement
parameterObject: 参数对象
skipResults :要查询的起始记录 ((page.getPageNo()-1)*page.getPageSize())
maxResults: 返回的最大记录条数 (page.getPageSize())
- private void handleResults(RequestScope request, ResultSet rs, int skipResults, int maxResults, RowHandlerCallback callback) throws SQLException {
- try {
- request.setResultSet(rs);
- ResultMap resultMap = request.getResultMap();
- if (resultMap != null) {
- // Skip Results
- if (rs.getType() != ResultSet.TYPE_FORWARD_ONLY) {
- if (skipResults > 0) {
- rs.absolute(skipResults);
- }
- } else {
- for (int i = 0; i < skipResults; i++) {
- if (!rs.next()) {
- break;
- }
- }
- }
- // Get Results
- int resultsFetched = 0;
- while ((maxResults == SqlExecutor.NO_MAXIMUM_RESULTS || resultsFetched < maxResults) && rs.next()) {
- Object[] columnValues = resultMap.resolveSubMap(request, rs).getResults(request, rs);
- callback.handleResultObject(request, columnValues, rs);
- resultsFetched++;
- }
- }
- } finally {
- request.setResultSet(null);
- }
- }
这个方法是翻阅ibatis源代码中找到的它实现分页查询的方法。
首先rs 是传过来的参数,rs在上级方法中是执行我们写的sql语句,将数据库中符合条件的所有数据查询出来得到的结果集
ResultSet.TYPE_FORWARD_ONLY是java.sql.ResultSet接口的方法,指的是数据库中的结果集只支持向前滚动。
rs.absolute(skipResults) 将游标移到相对第一行的指定行 为负数的话就是相对最后一行
下面的while就是取出我们最终要的分页结果放到某个对象中,返回给我们的查询方法。
通过分析源代码可知,ibatis分页有着很大的缺陷,首先将数据库中的所有数据取出来占用内存,其二采取游标滚动的方式取出我们所要的记录效率太低。我通过实际的例子测试,数据库中有300万条数据,每页显示10条,通过调用ibatis的分页方法和oracle 的sql两种方式实现分页查询。
结果表明,在前几页的查询两者效率相差不大,因为oracle的sql实现的分页也是将所有的数据查出来然后通过rownum属性取出我们所需要的。
越往后翻页ibatis分页的弱势(游标需要逐行滚动到2999990条)就越大,点击"尾页"链接进行查询后ibatis的分页查询已经比oracle sql的分页查询慢了5倍以上。
附 oracle sql分页的实现方法:
- <sql id="pageStart">
- <![CDATA[ select * from (select row_.*, rownum rownum_ from ( ]]>
- </sql>
- <sql id="pageEnd">
- <![CDATA[ )row_ where rownum<=#end# ) where rownum_>=#start# ]]>
- </sql>
- <!-- sql语句 -->
- <sql id="queryXsSql">
- SELECT XS_ID,
- XS_NAME,
- XS.ZY_ID,
- XS_NUM,
- XS_SFZ,
- XS_TEL,
- XS_EMAIL,
- XS_ADDRESS,
- XS_DATE,
- XS_SEX,
- ZY.ZY_NAME,
- XY.XY_NAME
- FROM XS XS
- INNER JOIN ZY ZY
- ON XS.ZY_ID = ZY.ZY_ID
- INNER JOIN XY
- ON XY.XY_ID = ZY.XY_ID
- <dynamic prepend="where">
- <isNotEmpty prepend="and" property="xs_name" >
- xs.xs_name like '%'||#xs_name#||'%'
- </isNotEmpty>
- <isNotEmpty prepend="and" property="xs_num" >
- xs.xs_num like '%'||#xs_num#||'%'
- </isNotEmpty>
- <isEqual prepend="and" property="xs_sex" compareValue="0" >
- xs.xs_sex='0'
- </isEqual>
- <isEqual prepend="and" property="xs_sex" compareValue="1" >
- xs.xs_sex='1'
- </isEqual>
- <isNotEmpty prepend="and" property="dateFrom" >
- <![CDATA[
- to_date(xs.xs_date,'yyyy-MM-dd')>=to_date(#dateFrom#,'yyyy-MM-dd')
- ]]>
- </isNotEmpty>
- <isNotEmpty prepend="and" property="dateTo" >
- <![CDATA[
- to_date(xs.xs_date,'yyyy-MM-dd')<=to_date(#dateTo#,'yyyy-MM-dd')
- ]]>
- </isNotEmpty>
- </dynamic>
- order by xs.xs_id desc
- </sql>
- <select id="queryByOrclPage" parameterClass="com.bh.chc.manager.xs.XueShengPage" resultClass="xuesheng">
- <include refid="pageStart"/>
- <include refid="queryXsSql"/>
- <include refid="pageEnd"/>
- </select>
- <select id="queryByOrclPageCount" resultClass="java.lang.Integer" parameterClass="com.bh.chc.manager.xs.XueShengPage">
- select count(*)
- from
- (
- <include refid="queryXsSql"/>
- )
- </select>
5.Ibatis调用存储过程实现增删改以及分页查询
1、Ibatis实现增删改操作很简单了,通常我是将某一模块的增删改功能写在一个存储过程里,通过一个标识符去区分执行增加还是修改抑或删除操作。
statement:
- <!-- 存储过程:实现学生的增删改操作 -->
- <procedure id="crud" parameterClass="xuesheng" >
- {call PRO_STUDENT_SUBMIT(
- #xs_id#,
- #xs_name#,
- #zy_id#,
- #xs_num#,
- #xs_sfz#,
- #xs_tel#,
- #xs_email#,
- #xs_address#,
- #xs_sex#,
- #xs_date#,
- #bq#
- )}
- </procedure>
- create or replace procedure PRO_STUDENT_SUBMIT(
- v_xs_id in varchar2,
- v_xs_name in varchar2,
- v_zy_id in varchar2,
- v_xs_num in varchar2,
- v_xs_sfz in varchar2,
- v_xs_tel in varchar2,
- v_xs_email in varchar2,
- v_xs_address in varchar2,
- v_xs_sex in varchar2,
- v_xs_date in varchar2,
- v_bq in varchar2
- ) is
- begin
- --当bq为1时,执行添加操作;为2时,执行修改操作;为3时执行删除操作
- if (v_bq = '1') then
- insert into xs
- (xs_id, xs_name, zy_id, xs_num, xs_sfz, xs_tel, xs_email, xs_address, xs_sex,xs_date)
- values
- (seq_xs.nextval , v_xs_name, v_zy_id, v_xs_num, v_xs_sfz, v_xs_tel, v_xs_email, v_xs_address, v_xs_sex,v_xs_date);
- end if;
- if (v_bq = '2') then
- update xs
- set xs_id = v_xs_id,
- xs_name = v_xs_name,
- zy_id = v_zy_id,
- xs_num = v_xs_num,
- xs_sfz = v_xs_sfz,
- xs_tel = v_xs_tel,
- xs_email = v_xs_email,
- xs_address = v_xs_address,
- xs_sex = v_xs_sex,
- xs_date=v_xs_date
- where xs_id = v_xs_id;
- end if;
- if (v_bq = '3') then
- delete xs
- where xs_id = v_xs_id;
- end if;
- end PRO_STUDENT_SUBMIT;
2、重要要说的是通过ibatis调用存储过程实现分页查询(带模糊查询),我们需要有一个返回参数,该参数是游标类型。
通过调用存储过程实现的分页查询要比上文介绍的ibatis分页查询性能上好很多。
代码实例如下(经测试完全好使,ibatis版本2.3)
- /**
- * 在存储过程内实现查询的分页 与 模糊查询
- * 需要传入到存储过程的参数 模糊查询的包括 学生姓名 学号 性别 入学时间的起止两个时间 一共5个
- * 分页需要的参数 那就是 pageNo pageSize 一共2个 总共需要7个IN参数 返回的肯定是游标了 所以有一个OUT 类型的 CURSOR;
- * 这些IN 参数都可以通过page对象传过去
- */
- public String queryByPro (){
- ((XueShengPage)page).setXs_name(xs.getXs_name());
- ((XueShengPage)page).setXs_num(xs.getXs_num());
- ((XueShengPage)page).setDateFrom(xs.getPage_dateFrom());
- ((XueShengPage)page).setDateTo(xs.getPage_dateTo());
- ((XueShengPage)page).setXs_sex(xs.getXs_sex());
- Date nowMilDate = new Date();
- long time1 = nowMilDate.getTime();
- xsList=this.xsService.queryByPro((XueShengPage)page);
- Date time2 = new Date();
- LogUtil.info("存储过程实现分页查询用时:"+(time2.getTime()-time1));
- return "query";
- }
- public List queryByPro(XueShengPage page) {
- int rowCount=this.dao.queryForInt("xuesheng.queryListCount", page);//查询总条数
- page.setRowCount(rowCount);
- page.accountPageCount();//计算总页数
- List xsList=new ArrayList();
- Map map1 = new HashMap();
- map1.put("xs_name",page.getXs_name());
- map1.put("xs_num", page.getXs_num());
- map1.put("xs_sex", page.getXs_sex());
- map1.put("dateFrom", page.getDateFrom());
- map1.put("dateTo", page.getDateTo());
- map1.put("pageNo", page.getPageNo());
- map1.put("pageSize", page.getPageSize());
- this.dao.queryOne("xuesheng.pro_cursor", map1);
- List<Map> list=(List<Map>) map1.get("backcursor");//调用存储过程进行查询
- for(int i=0;i<list.size();i++){
- XueSheng xs=new XueSheng();//需要传递模糊查询 和 分页所需要的参数(页号pageNo和每页显示多少条pageSize)
- xs.setXs_id(list.get(i).get("xs_id").toString());
- xs.setXs_address(list.get(i).get("xs_address").toString());
- xs.setXs_date(list.get(i).get("xs_date").toString());
- xs.setXs_email(list.get(i).get("xs_email").toString());
- xs.setXs_name(list.get(i).get("xs_name").toString());
- xs.setXs_num(list.get(i).get("xs_num").toString());
- xs.setXs_sex(list.get(i).get("xs_sex").toString());
- xs.setXs_sfz(list.get(i).get("xs_sfz").toString());
- xs.setXs_tel(list.get(i).get("xs_tel").toString());
- xs.setXy_name(list.get(i).get("xy_name").toString());
- xs.setZy_id(list.get(i).get("zy_id").toString());
- xs.setZy_name(list.get(i).get("zy_name").toString());
- xsList.add(xs);
- }
- return xsList;
- }
- <resultMap class="hashmap" id="backmap">
- <result property="xs_id" column="XS_ID"/>
- <result property="xs_name" column="XS_NAME"/>
- <result property="zy_id" column="ZY_ID"/>
- <result property="xs_num" column="XS_NUM"/>
- <result property="xs_sfz" column="XS_SFZ"/>
- <result property="xs_tel" column="XS_TEL"/>
- <result property="xs_email" column="XS_EMAIL"/>
- <result property="xs_address" column="XS_ADDRESS"/>
- <result property="xs_date" column="XS_DATE"/>
- <result property="xs_sex" column="XS_SEX"/>
- <result property="zy_name" column="ZY_NAME"/>
- <result property="xy_name" column="XY_NAME"/>
- </resultMap>
- <parameterMap class="hashmap" id="pro_cursor_map">
- <parameter property="backcursor" javaType="java.sql.ResultSet" jdbcType="ORACLECURSOR" mode="OUT" resultMap="backmap"/>
- <parameter property="xs_name" javaType="String" jdbcType="VARCHAR" mode="IN"/>
- <parameter property="xs_num" javaType="String" jdbcType="VARCHAR" mode="IN"/>
- <parameter property="xs_sex" javaType="String" jdbcType="VARCHAR" mode="IN"/>
- <parameter property="dateFrom" javaType="String" jdbcType="VARCHAR" mode="IN"/>
- <parameter property="dateTo" javaType="String" jdbcType="VARCHAR" mode="IN"/>
- <parameter property="pageNo" javaType="int" jdbcType="NUMBER" mode="IN"/>
- <parameter property="pageSize" javaType="int" jdbcType="NUMBER" mode="IN"/>
- </parameterMap>
- <procedure id="pro_cursor" parameterMap="pro_cursor_map">
- {call <span style="font-family: Arial, Helvetica, sans-serif;">queryXsByPro</span>(?,?,?,?,?,?,?,?)}
- </procedure>
- create or replace procedure queryXsByPro
- (
- my_cursor out sys_refcursor,
- v_xs_name IN VARCHAR2,
- v_xs_num in varchar2,
- v_xs_sex in varchar2,
- v_dateFrom in varchar2,
- v_dateTo in varchar2,
- v_pageNo in number,
- v_pageSize in number
- )
- as
- xs_begin number(10);--从哪条记录开始查
- xs_end number(10);--查到哪条记录结束
- v_sql varchar2(1000);
- begin
- xs_begin:=(v_pageNo-1)*v_pageSize+1;
- xs_end :=xs_begin+v_pageSize;
- v_sql :=
- 'SELECT
- XS_ID,
- XS_NAME,
- XS.ZY_ID,
- XS_NUM,
- XS_SFZ,
- XS_TEL,
- XS_EMAIL,
- XS_ADDRESS,
- XS_DATE,
- XS_SEX,
- ZY.ZY_NAME,
- XY.XY_NAME
- FROM XS XS
- INNER JOIN ZY ZY
- ON XS.ZY_ID = ZY.ZY_ID
- INNER JOIN XY
- ON XY.XY_ID = ZY.XY_ID
- WHERE 1=1 ';
- if v_xs_sex is not null then
- v_sql :=v_sql||' and xs_sex=v_xs_sex ';
- end if;
- if v_dateFrom is not null then
- v_sql :=v_sql||' and to_date(xs_sex,''yyyy-MM-dd'')>=to_date(v_dateFrom,''yyyy-MM-dd'') ';
- end if;
- if v_dateTo is not null then
- v_sql :=v_sql||' and to_date(xs_sex,''yyyy-MM-dd'')<=to_date(v_dateTo,''yyyy-MM-dd'') ';
- end if;
- v_sql:='select * from (select row_.*, rownum rownum_ from ('||v_sql;
- v_sql:=v_sql || ')row_ where rownum<=' || xs_end || ' ) where rownum_>=' || xs_begin;
- open my_cursor for v_sql;
- end;
6.Mybatis动态SQL
ibatis的动态sql比较简单,网上说的也都大同小异,直接转载一篇:
直接使用JDBC一个非常普遍的问题就是动态SQL。使用参数值、参数本身和数据列都是动态SQL,通常是非常困难的。典型的解决办法就是用上一堆的IF-ELSE条件语句和一连串的字符串连接。对于这个问题,Ibatis提供了一套标准的相对比较清晰的方法来解决一个问题,这里有个简单的例子:
<select id="getUserList" resultMap="user">
select * from user
<isGreaterThan prepend="and" property="id" compareValue="0">
where user_id = #userId#
</isGreaterThan>
order by createTime desc
</select>
上面的例子中,根据参数bean“id”属性的不同情况,可创建两个可能的语句。如果参数“id”大于0,将创建下面的语句:
select * from user where user_id = ? order by createTime desc
或者,如果“id”参数小于等于0,将创建下面的语句:
select * from user order by createTime desc
以上的这个例子是否可以看出Ibatis里提供的简单的写法来实现了复杂拖沓的动态SQL呢?我们在做查询的时候,对于同一个表,甚至可以用来定义一个动态SQL,做到重用的地步,还是上面那个例子:
<sql id="queryCondition">
<dynamic prepend="WHERE">
<isGreaterThan prepend="and" property="id" compareValue="0">
where user_id = #userId#
</isGreaterThan>
</dynamic>
</sql>
<select id="getUserList" resultMap="user">
select * from user
<!-- 引入动态的查询条件 -->
<include refid="queryCondition"/>
order by createTime desc
</select>
这个使用的话是否更加的具有公用性能,这就是Ibatis带来的便利。
在Ibatis中,动态的条件元素包含一下几种:二元条件元素、一元条件元素和其他条件元素:
(1)、二元条件元素:将一个属性值和静态值或另一个属性值比较,如果条件为真,元素将被包容在查询SQL语句中。
二元条件元素的属性:
perpend——可被覆盖的SQL语句组成部分,添加在语句的前面(可选)
property——是比较的属性(必选)
compareProperty——另一个用于和前者比较的属性(必选或选择compareValue)
compareValue——用于比较的值(必选或选择compareProperty)
| <isEqual> | 比较属性值和静态值或另一个属性值是否相等。 |
| <isNotEqual> | 比较属性值和静态值或另一个属性值是否不相等。 |
| <isGreaterThan> | 比较属性值是否大于静态值或另一个属性值。 |
| <isGreaterEqual> | 比较属性值是否大于等于静态值或另一个属性值。 |
| <isLessThan> | 比较属性值是否小于静态值或另一个属性值。 |
| <isLessEqual> | 比较属性值是否小于等于静态值或另一个属性值。 |
举个小例子:
<isLessEqual prepend=”AND” property=”age” compareValue=”18”>
ADOLESCENT = ‘TRUE’
</isLessEqual>
如果大于等18岁时,则为成年人
(2)、一元条件元素:一元条件元素检查属性的状态是否符合特定的条件。
一元条件元素的属性:
prepend——可被覆盖的SQL语句组成部分,添加在语句前面(可选)
property——被比较的属性(必选)
| <isPropertyAvailable> | 检查是否存在该属性(存在parameter bean的属性) |
| <isNotPropertyAvailable> | 检查是否不存在该属性(不存在parameter bean的属性) |
| <isNull> | 检查属性是否为null |
| <isNotNull> | 检查属性是否不为null |
| <isEmpty> | 检查Collection.size()的值,属性的String或String.valueOf()值,是否为null或空(“”或size() < 1) |
| <isNotEmpty> | 检查Collection.size()的值,属性的String或String.valueOf()值,是否不为null或不为空(“”或size() > 0) |
小例子:
<isNotEmpty prepend="AND" property="firstName" >
FIRST_NAME=#firstName#
</isNotEmpty>
(3)、其他元素条件
(a).Parameter Present:这些元素检查参数对象是否存在
Parameter Present条件的属性
prepend - 可被覆盖的SQL语句组成部分,添加在语句的前面(可选)
| <isParameterPresent> | 检查是否存在参数对象(不为null) |
| <isNotParameterPresent> | 例子: <isNotParameterPresent prepend=”AND”> EMPLOYEE_TYPE = ‘DEFAULT’ </isNotParameterPresent> |
(b)、Iterate:这属性遍历整个集合,并为List集合中的元素重复元素体的内容。
Iterate的属性:
prepend - 可被覆盖的SQL语句组成部分,添加在语句的前面(可选)
property - 类型为java.util.List的用于遍历的元素(必选)
open - 整个遍历内容体开始的字符串,用于定义括号(可选)
close -整个遍历内容体结束的字符串,用于定义括号(可选)
conjunction - 每次遍历内容之间的字符串,用于定义AND或OR(可选)
| <iterate> | 遍历类型为java.util.List的元素。 例子: <iterate prepend="AND" property="userNameList" open="(" close=")" conjunction="OR"> username=#userNameList[]# </iterate> 注意:使用<iterate>时,在List元素名后面包括方括号[]非常重要,方括号[]将对象标记为List,以防解析器简单地将List输出成String。 |
以上讲述了关于Ibatis的动态SQL的功能,是否觉得非常强大,并且优雅呢?那还犹豫什么呢?行动起来。
7.Mybatis缓存机制
我们知道Hibernate有自己的缓存机制,Hibernate中分为一级缓存和二级缓存,其中的一级缓存是session缓存,是Hibernate封装好的,不需要我们做任何配置的,一级缓存是与session绑定的,当session生命周期结束的时候对应的一级缓存也就消失了。Hibernate的二级缓存需要自己配置的,很遗憾,一直没去深入了解过,等过了这阶段比较忙的时间一定得好好研究研究Hibernate
至于我们的Ibatis,也是有着自己的缓存机制的,使用ibatis的缓存的时候我们要特别的小心谨慎,保证对缓存对象操作的同步性。
- <!-- 定义缓存 -->
- <cacheModelidcacheModelid="query_cache_xy" readOnly="false" serialize="true" type="LRU">
- <flushInterval hours="24" />
- <flushOnExecute statement="xueyuan.save" />
- <flushOnExecute statement="xueyuan.edit" />
- <flushOnExecute statement="xueyuan.del" />
- <property value="600" name="size" />
- </cacheModel>
这是一个典型的缓存例子,下面我们参照这个例子看看定义缓存的时候需要制定哪些属性,又包含哪些子元素
id属性 这个不用说,唯一标识
readOnly属性:定义是否是只读缓存
为true的时候表示该缓存为只读缓存 ,这里的只读并不是意味着数据对象一旦放入缓存中就无法再对数据进行修改,而是当数据对象发生变化的时候,如数据对象中的某个属性发生变化,那么数据将从缓存中被废除,下次需要重新从数据库中读取数据,构造新的数据对象。
只读缓存由于他可以被多个用户共享,所以可以提高程序性能,但是有数据更改的时候就会降低效率。还有一方面当用户访问只读缓存的时候,框架会将缓存对象的引用直接返回给用户,当多个线程同时访问的时候,就会出现多个线程同时操作一个对象的问题,会出现线程同步的问题。
当为可读写缓存的时候,当读取到缓存对象的 时候,缓存会返回给你一个原对象的副本,而不是直接将原对象的引用直接返回给你,这样即时是多线程访问该缓存,由于他每个线程获得的都是一个内容相同的对象副本,不会出现线程同步的问题。
同时可读写缓存是可更新的。
serialize 是否为全局缓存,true代表全局缓存
当设置全局缓存的时候,表示多个session访问该缓存的时候会获得相同内容的不同实例对象,也就是前面说的原对象的副本。所以serialize 值为true的前提是readOnly属性必须为true。
下面就该说下type属性了,代表的是应用哪种缓存模型,一共有四种缓存模型供我们选择:
(1)、"MEMORY” (com.ibatis.db.sqlmap.cache.memory.MemoryCacheController)。ibatis直接将数据放进内存中,由GC负责管理,如果属性<property name="reference-type"value="WEAK"/>的值为WEAK、SOFT,GC将根据内存使用情况清理缓存如果该值为Strong,缓存将一直保存,一直到flush。
(2)、“LRU”(com.ibatis.db.sqlmap.cache.lru.LruCacheController)。LRU Cache实现用“近期最少使用”原则来确定如何从 Cache 中清除对象。当 Cache溢出时,最近最少使用的对象将被从 Cache 中清除。使用这种方法,如果一个特定的对象总是被使用,它将保留在 Cache中,而且被清除的可能性最小。对于在较长的期间内,某些用户经常使用某些特定对象的情况(例如,在PaginatedList 和常用的查询关键字结果集中翻页) ,LRU Cache 是一个不错的选择。
(3)、“FIFO”(com.ibatis.db.sqlmap.cache.fifo.FifoCacheController)。FIFO Cache实现用“先进先出”原则来确定如何从 Cache 中清除对象。当 Cache 溢出时,最先进入Cache 的对象将从 Cache 中清除。对于短时间内持续引用特定的查询而后很可能不再使用的情况,FIFO Cache 是很好的选择。
(4)、“OSCACHE” (com.ibatis.db.sqlmap.cache.oscache.OSCacheController) 。OSCACHE Cache 实现是OSCache2.0缓存引擎的一个 Plugin。它具有高度的可配置性,分布式,高度的灵活性。
根据不同的要求选择不同的缓存模型,当然我们也可以写自定义缓存,需要实现CacheController接口,type属性的值就是类的名称
再说说他 的子元素:
<flushIntervalhours="24" /> 指的是多长时间刷新,此处指24小时,也可设置分钟、秒等单位
<flushOnExecute statement="xueyuan.save" />
<flushOnExecute statement="xueyuan.edit" />
<flushOnExecute statement="xueyuan.del" /> 这个属性指的是当程序调用了这几个statement后缓存会刷新
写个实例验证下缓存,代码如下(测试完全好使):
- <!-- 定义缓存 -->
- <cacheModel id="query_cache_xy" type="LRU" readOnly="false" serialize="true">
- <flushInterval hours="24" />
- <flushOnExecute statement="xueyuan.save" />
- <flushOnExecute statement="xueyuan.edit" />
- <flushOnExecute statement="xueyuan.del" />
- <property value="600" name="size" />
- <span style="white-space:pre"> </span></cacheModel>
- <!-- 查询学院 应用缓存 -->
- <select id="queryXyList" resultClass="xueyuan" cacheModel="query_cache_xy" >
- select a.xy_id, a.xy_name from xy a
- </select>
例子当中的<property value="600" name="size" >指定缓存对象的数量最大为600条
平时用用这个ibatis的缓存也是不错滴。
8.Mybatis懒加载
我们知道Hibernate中有get()和load()两种方法,load()采用的是延迟加载的机制,同样的对于Ibatis也有着自己的延迟加载机制,
什么是延迟加载呢,就是将暂时不需要的对象不真正的载入内存,而是在内存中为该对象创建一个代理对象,当我们使用到该对象的时候再去加载该对象。
为什么要使用延迟加载呢,举个例子说明一下,全国有1000个学校,每个学校有1000个专业 ,每个专业有1000个学生
< result property ="xy_id" column ="xy_id" />
< result property ="xy_name" column ="xy_name" />
< result property ="zhuanye" column ="xy_id" select ="getZhuanYe" />
</ resultMap >
< resultMap class ="zhuanye" id ="zhuanye_result" >
< result property ="zy_id" column ="zy_id" />
< result property ="zy_name" column ="zy_name" />
< result property ="xy_id" column ="xy_id" />
< result property ="xuesheng" column ="zy_id" select ="getXueSheng" />
</ resultMap >
< select id ="getXueYuan" resultMap ="xueyuan_result" >
select xy_id,xy_name from xy
</ select >
< select id ="getZhuanYe" resultMap ="zhuanye_result" parameterClass ="string" >
select zy_id,zy_name ,xy_id where xy_id=#xy_id#
</ select >
< select id ="getXueSheng" resultClass ="xuesheng" parameterClass ="string" >
select xs_id,xs_name,zy_id from xs where zy_id=#zy_id#
</ select >
根据上面的代码我们知道,我们在调用的getXueYuan时候会执行1+1000*1000+1000*1000*1000条sql语句,创建了1000+1000*1000+1000*1000*1000个对象,我们会疯掉的。
所以我们需要配置延迟加载,也就是在sqlMapConfig中的setting元素中配置:
<settings lazyLoadingEnabled="true" enhancementEnabled="true"/>
enhancementEnabled设置为true的时候是使用字节码增强机制,可以优化延迟加载机制,也就是对延迟加载机制有所加强。
设置完延迟加载后,我们再调用getXueYaun方法的时候就会只执行一条sql语句 创建1000个对象,而下属的专业、学生对象都是在内存中创建了一个代理对象,并没有被加载到内存当中。 当用到他们的时候才会执行select语句。
9.Mybatis技巧之 实现ibatis手动控制加载sqlmap文件,终于不用重启应用了
大学毕业之后到公司,就是velocity+springMVC+srping+ibatis,所以一直在用ibatis做持久层,其他的几个框架也都是稍有了解。
好了屁话少说进入正题:之前有写一篇文章 《java webapp嵌入jetty》 为的就是能快速开发,直接在eclipse做debug很是方便。但是呢,用了ibatis,在sqlmap中写了sql,如果每次修改了sqlmap,那么就要每次都重启应用才行,使用起来很是蛋疼,如果项目小,也就是分分钟的事,如果工程足够大,那么重启一次就够受了!
于是就在考虑,能否每次手动来控制ibatis重新加载已经修改好的sqlmap呢?这就可以不用重启了。
答案肯定是可以的~ 毕竟在spring做bean初始化的时候就会加载ibatis的sqlmap,所以只要我们找到对应的代码,然后做出一些调整就可以实现重新加载了。
OK,看代码~~

首先SqlmapClientFactoryBean是spring给ibatis做的适配,那么我们就要从这个类看起。
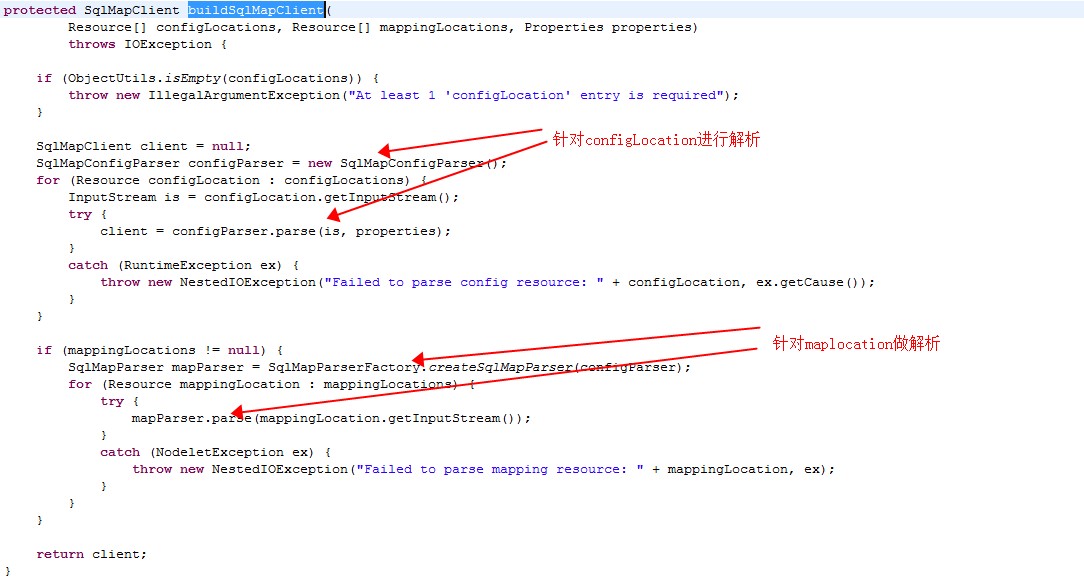
可以看到ibatis的sqlmapClient是通过configParser返回的。
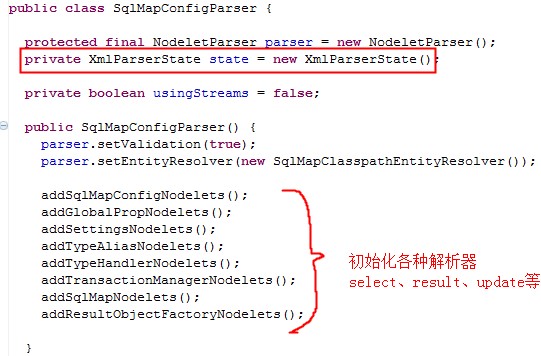
在new SqlMapConfigParser()的时候,由于以下的引用关系。
SqlMapConfigParser--XmlParserState--SqlMapConfiguration---SqlMapExecutorDelegate
SqlMapConfigParser会 将上面的类初始化,并且在SqlMapConfiguration初始化的时候,将new的SqlMapExecutorDelegate赋值给SqlMapClientImpl而SqlMapExecutorDelegate才是真正的执行代理类,并且所有的sqlmap解析都被它保存着。
解析过程不详细表述了,感兴趣的同学可以看源码。
最终通过SqlMapExecutorDelegate.addMappedStatement方法,把解析出来的sqlmapstatement保存到map中sqlmap的id为key值
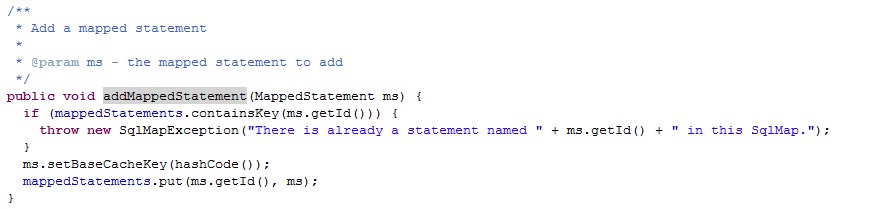
代码如上,可以看到每次添加会验证id是否重复。这也就是为啥一个sql中如果有两个相同id就会报错的原因。
好了!代码看清楚了,接下来就看我们怎么来修改代码了。
主要就是SqlmapClientFactoryBean、SqlMapExecutorDelegate、SqlMapClientImpl三个类
我们想重新刷新,那么就要操作SqlMapExecutorDelegate中的map,然后ibatis和spring的接口只有SqlMapClientImpl这个类,并且spring的适配是SqlmapClientFactoryBean
于是乎,思路就来了,只要我们重写SqlmapClientFactoryBean让它返回我们重写过的SqlMapClientImpl,在SqlMapClientImpl添加刷新的方法,然后通过SqlMapClientImpl来调用我们代理的SqlMapExecutorDelegate就可以实现重新加载了~
代码如下:
SqlmapClientFactoryBean
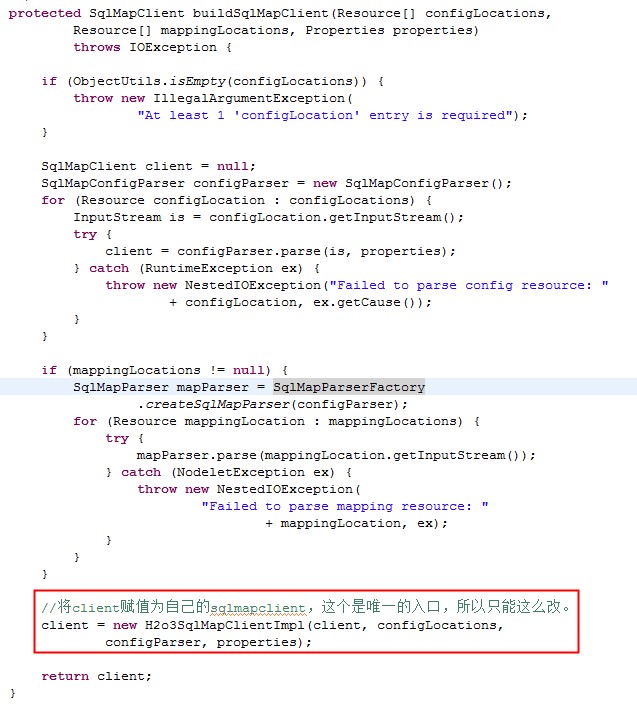
在添加返回前,声明出我们重写的对sqlmapClientImpl的代理
- package com.h2o3.right.dal.platform;
- import java.io.IOException;
- import java.io.InputStream;
- import java.lang.reflect.Field;
- import java.util.Properties;
- import org.springframework.core.NestedIOException;
- import org.springframework.core.io.Resource;
- import com.ibatis.sqlmap.client.SqlMapClient;
- import com.ibatis.sqlmap.engine.builder.xml.SqlMapConfigParser;
- import com.ibatis.sqlmap.engine.builder.xml.XmlParserState;
- import com.ibatis.sqlmap.engine.config.SqlMapConfiguration;
- import com.ibatis.sqlmap.engine.impl.ExtendedSqlMapClient;
- import com.ibatis.sqlmap.engine.impl.SqlMapClientImpl;
- /**
- * sqlMapClientImpl的代理类。
- *
- * <pre>
- * 这个类是所有sql操作的入口,并且存放了SqlMapExecutorDelegate这个sql执行器的代理类。
- * 并且这个类是在spring中的入口。
- *
- * 所以代理这个类,将自己的delegate设置进去,并且反射自己的delegate到SqlMapConfiguration中
- * 保证重新加载sqlmap的时候,操作的是自己的delegate,这样就不会触发原生delegate中的重复判断。
- * </pre>
- *
- * @author yuezhen
- *
- */
- public class H2o3SqlMapClientImpl extends SqlMapClientImpl {
- /**
- * Delegate for SQL execution
- */
- public H2o3SqlMapExecutorDelegate h2o3Delegate;
- /**
- * sqlmap的路径
- */
- private Resource[] configLocations;
- /**
- * config转换器
- */
- private SqlMapConfigParser configParser;
- /**
- * sqlmapclient配置的properties,spring传入
- */
- private Properties properties;
- /**
- * 构造方法。
- *
- * @param client
- * @param configLocations
- * @param configParser
- * @param properties
- */
- public H2o3SqlMapClientImpl(SqlMapClient client,
- Resource[] configLocations, SqlMapConfigParser configParser,
- Properties properties) {
- super(new H2o3SqlMapExecutorDelegate(((ExtendedSqlMapClient) client)
- .getDelegate()));
- this.h2o3Delegate = (H2o3SqlMapExecutorDelegate) this.delegate;
- this.configLocations = configLocations;
- this.configParser = configParser;
- this.properties = properties;
- relfectDelegate();
- }
- /**
- * 重新刷新。
- *
- * @throws IOException
- */
- public void fresh() throws IOException {
- // 调用configParser来重新加载
- for (Resource configLocation : configLocations) {
- InputStream is = configLocation.getInputStream();
- try {
- configParser.parse(is, properties);
- } catch (RuntimeException ex) {
- throw new NestedIOException("Failed to parse config resource: "
- + configLocation, ex.getCause());
- }
- }
- }
- /**
- * 反射将自己的delegate,反射到SqlMapConfiguration中。
- */
- public void relfectDelegate() {
- try {
- Field stateField = this.configParser.getClass().getDeclaredField(
- "state");
- stateField.setAccessible(true);
- XmlParserState state = (XmlParserState) stateField
- .get(this.configParser);
- Field configFiled = state.getClass().getDeclaredField("config");
- configFiled.setAccessible(true);
- SqlMapConfiguration configField = (SqlMapConfiguration) configFiled
- .get(state);
- Field clientField = configField.getClass().getDeclaredField(
- "client");
- clientField.setAccessible(true);
- clientField.set(configField, this);
- Field delegateField = configField.getClass().getDeclaredField(
- "delegate");
- delegateField.setAccessible(true);
- delegateField.set(configField, this.delegate);
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- public H2o3SqlMapExecutorDelegate getMydelegate() {
- return h2o3Delegate;
- }
- }
代理中做保存自己所写的SqlMapExecutorDelegate代理,并且把自己的SqlMapExecutorDelegate通过反射的方式放到SqlMapConfiguration中,以保证从新加载的时候用的是我们的SqlMapExecutorDelegate。
并且实现刷新的方法:将传入的sqlmap路径,在调用一次parser的解析。
在SqlMapExecutorDelegate方法中,由于这个类太多不可见,没办法,只能很土的方法,一是写个代理,代理他所有的方法,并且重写addmapping的方法。二是通过反射把所有的属性反射进去。然后重写addmapping。
这里采用第一种方案

将以前的重复判断给去掉。
最后,web层做一个刷新的controller,将sqlmapclient注入进去,然后通过refesh方法来进行刷新即可。

这样,每次修改了sql之后,访问一下refersh.htm就重新加载了sqlmap!!
这里只是实现通过url手动刷新,如果大家感兴趣,还可以设置,没法访问db都去刷新,方法类似,都是修改SqlMapExecutorDelegate这个类的不同调用方法即可。
已经测试通过,ibatis基于org/apache/ibatis/ibatis-sqlmap/2.3.4.726/ibatis-sqlmap-2.3.4.726-sources.jar
附上四个文件下载链接 http://download.csdn.net/detail/lywybo/5613303
H2o3SqlMapClientFactoryBean.java
H2o3SqlMapClientImpl.java
H2o3SqlMapExecutorDelegate.java
RefershController.java
使用的时候将文件放到代码中,然后配置sqlmapclient为H2o3SqlMapClientFactoryBean即可。

然后配合上篇文章 《java webapp嵌入jetty》 来启动,一个很方便的开发环境就做好了。
等过几天有空,会把这个空的框架搭起来,方便大家使用。















 209
209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









