






背景:
最近学习python,正好看到GitHub上有一个开源项目,一个百度云资源爬虫,感觉挺有意思就打算模仿一下,但是发现,好像现在百度云资源已经很难爬取了,于是就打算自己爬一个电影资源网站。
项目大体框架:
- 爬虫(数据库用的是mysql)
- xunsearch(一个开源的搜索引擎解决方案)
- 网页部分
- 数据统计
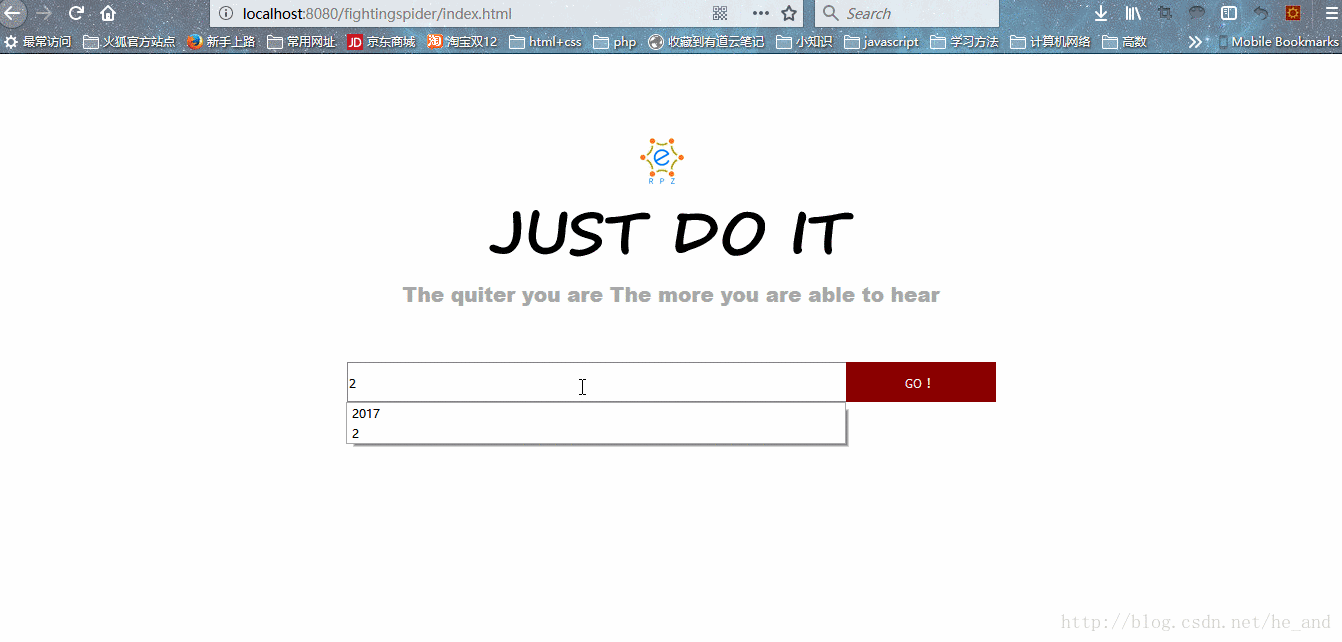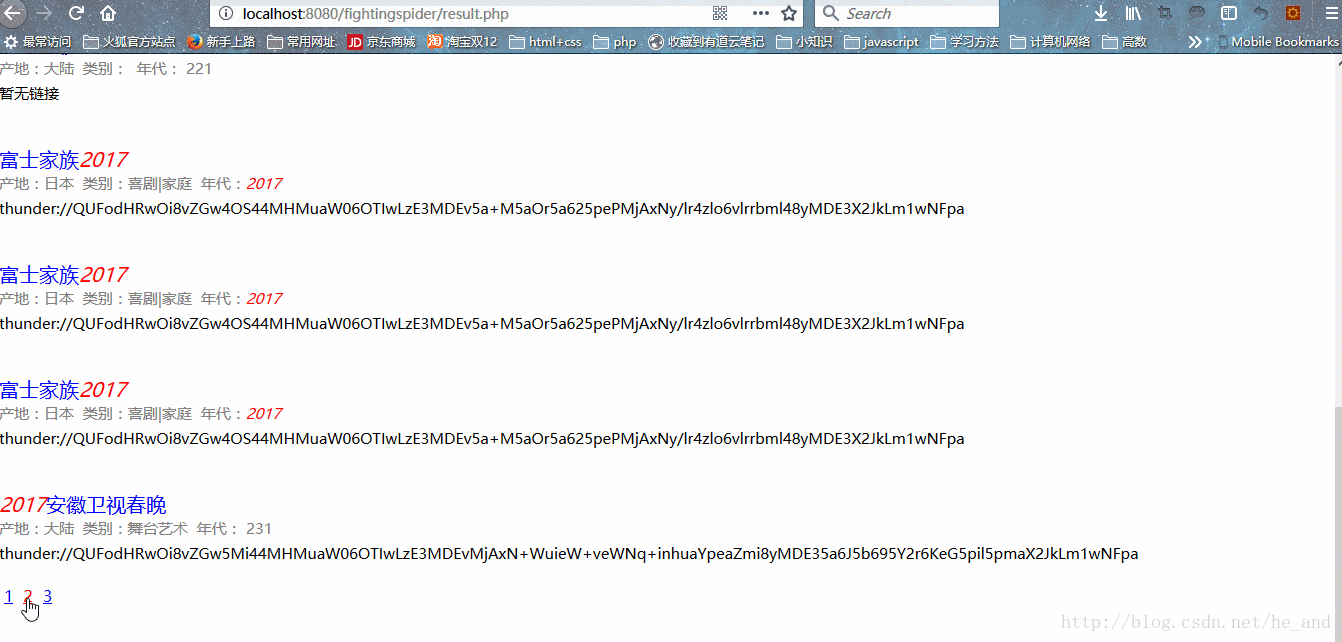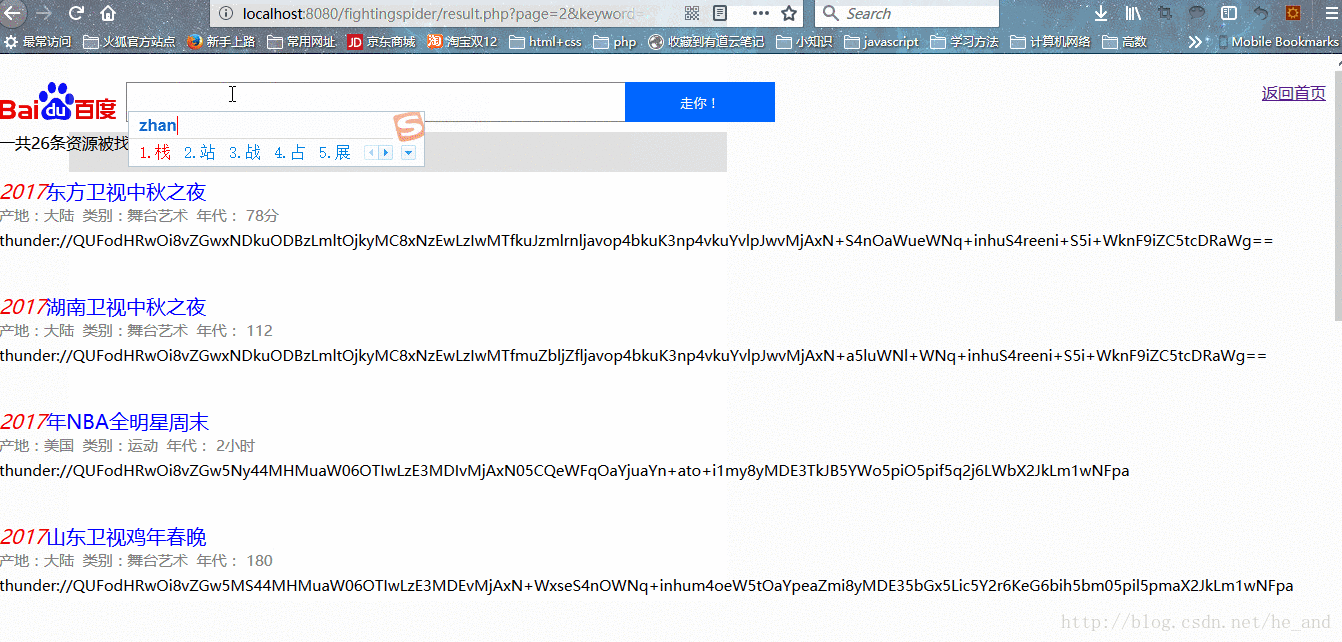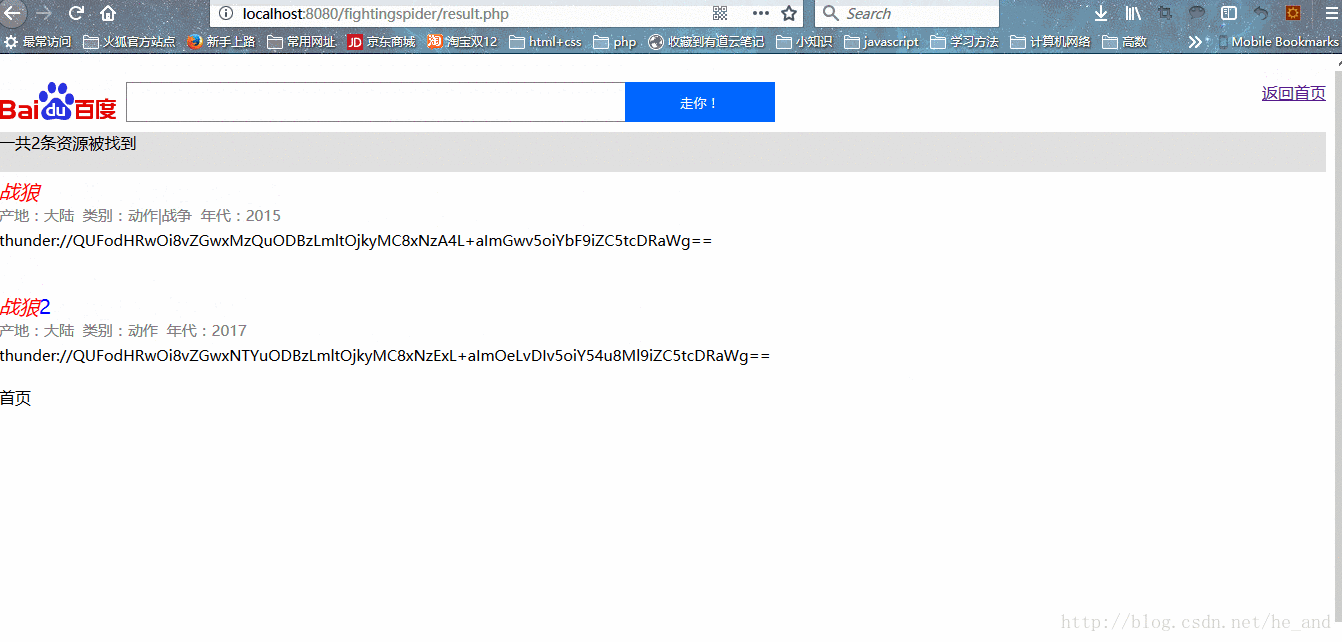
效果展示:
(忽略那个百度的图标,原谅一个工科男做不出好看的logo,只好借用一下啦,百度大大原谅我)
由于精力有限,很多想要的功能没有实现,只实现了基本的搜索功能。

**
下面具体介绍下每个部分:
**
1.爬虫
爬虫我用的是最简单的requests与beautifulsoup这两个库:
beautifulsoup文档
requests文档
其他库:
MySQLDb
mutiprocessing
下面我会提到爬虫经常用到的几个知识点:应对反爬虫、多线程爬虫、断点续爬、动态网页的爬取
爬虫我改了很多次,因为对方的管理人员反爬虫做的还是很不错的,总是出问题,一点奉献精神都没有
一开始也是我太天真了,没有做任何安全措施就直接裸奔着开着多个线程就开始干了,没想到爬到一千多条资源的时候就挂掉了,但是还好管理员手下留情没有封我ip,于是我做了简单反反爬虫,每爬10条数据就time.sleep(5),但是貌似还是总是会断开,我觉得会不会是管理员对我的ip做了什么限制,于是我就开始打代理的主意,说干就干,上
西刺代理爬了1600多个ip,贴上代码

#! /usr/bin/env python
#-*-coding:utf-8 -*-
#import MySQLdb
#import re
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36',
'Referrer':'http://www.dytt8.net/'
}
proxies_tmp = []
proxies = []
filehandle = open('G:/ip_pool/ip.txt','w')
print '开始自动获取代理。。。'
for page in range(1,31):
url = 'http://www.xicidaili.com/nn/{}'.format(str(page))
web_data = requests.get(url,timeout=0.1,headers=headers)
soup = BeautifulSoup(web_data.text,'html.parser')
ips = soup.select('tr')
for ip in ips:
tds = ip.find_all('td')
if len(tds)>0:
proxies_dict = {tds[5].string:tds[5].string+'://'+tds[1].string+':'+tds[2].string}
#proxies_tmp.append(tds[5].string+'://'+tds[1].string+':'+tds[2].string)
proxies_tmp.append(proxies_dict)
print proxies_tmp
#test_url = 'http://www.dytt8.net/'
test_url = 'http://www.ygdy8.net'
for ip in proxies_tmp:
#ip = ip.encode('utf-8')
r = requests.get(test_url,proxies=ip)
print r.status_code
print ip
filehandle.write(str(ip)+',\n')
proxies.append(ip)
filehandle.close()
print proxies
print '代理获取完毕!'
代码注释不完整,见谅
下面是我的ip池:
然后我又改变了一下策略,每爬四页就time.sleep(random.randint(1,3))
然后同时换一个ip,这样就避免了代理ip被封,为了以防万一,我也加上了请求头:
headers = {
‘User-Agent’:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36’
}
这样就更加逼真了吧
然而事实证明我还是太嫩了,爬虫还是会断,而且断了又需要从头开始爬取,那么我的数据库里的数据就只有全部删除,真的是让人头痛。看来断点续爬这个功能的实现迫在眉睫。
先来看下网站大概的结构:


就是一个主页面列出了所有的电影,然后点进去就是每部电影的详情页,所以我们就可以先把所有电影的链接先爬下来存在一个数据库里(links)
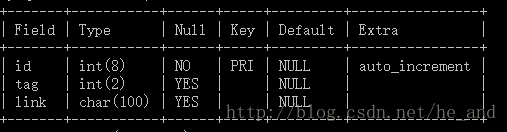
数据库结构:
爬完了过后,links1数据库的部分内容
tag是最重要的一个字段,tag是一个标志,如果爬过了的链接我就置该链接的tag为1,否则tag为0,下次我爬取数据时就会从这个数据表里提取link,所以这就实现了断点续爬,并且不会重复爬取。
这么一来就再也不担心爬虫挂了(发挥一下脑洞,可以实现断了然后重启爬虫继续爬,全自动化),现在不担心爬虫被封了,就要考虑效率的问题了,有两个选择,一是自己多开几个爬虫,还有就是多线程爬虫,我选择了后者,这就会用到mutiprocessing这个库,
mutiprocessing使用实例
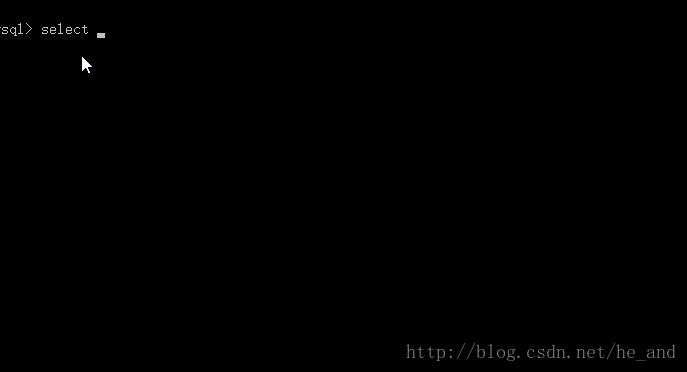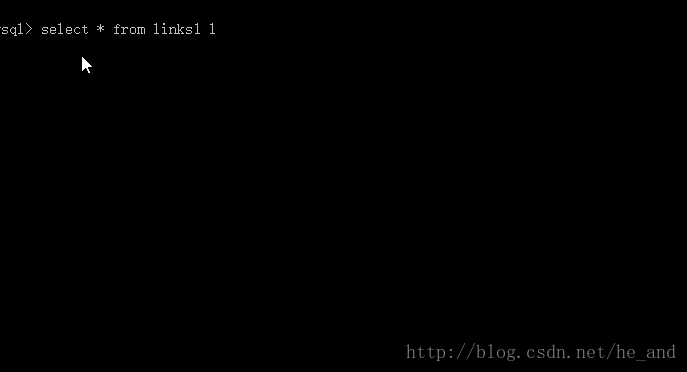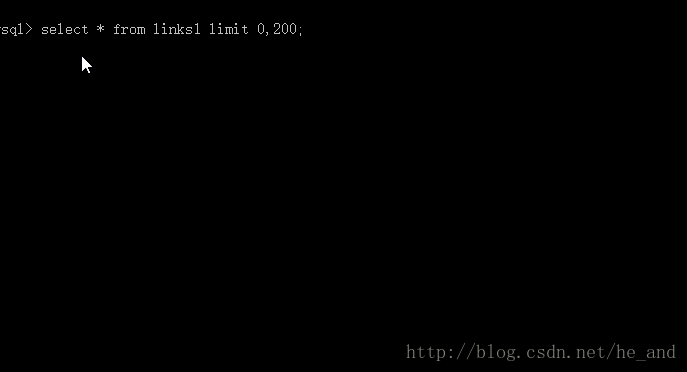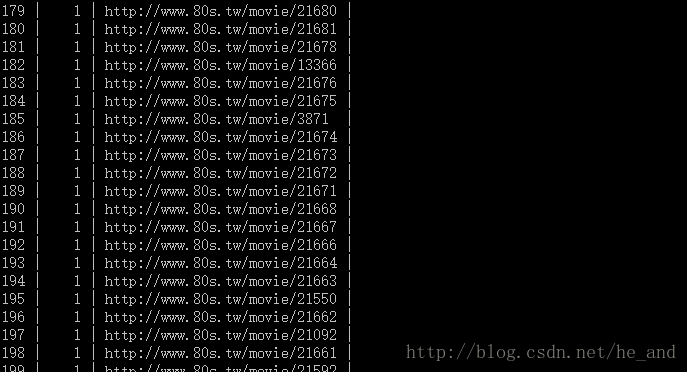
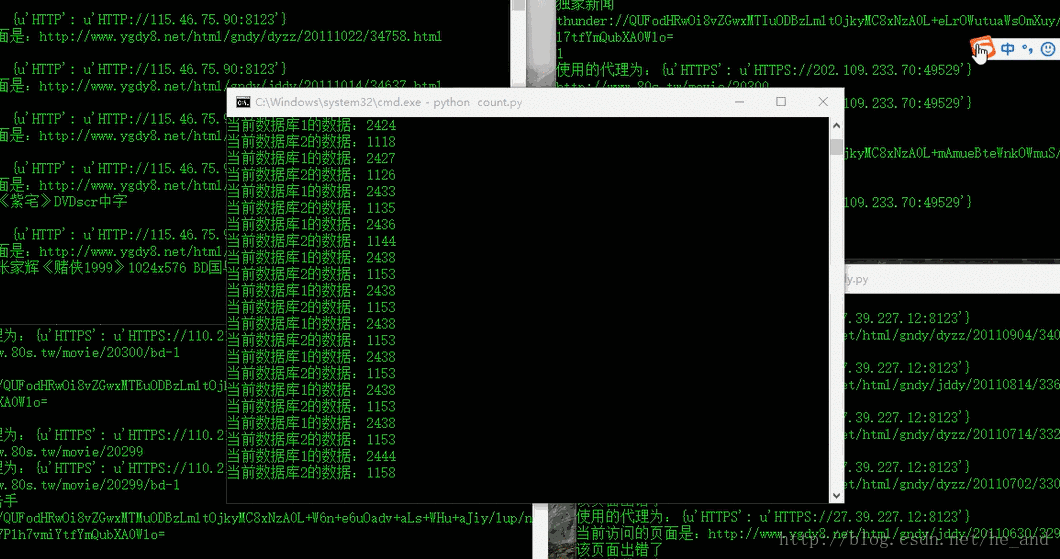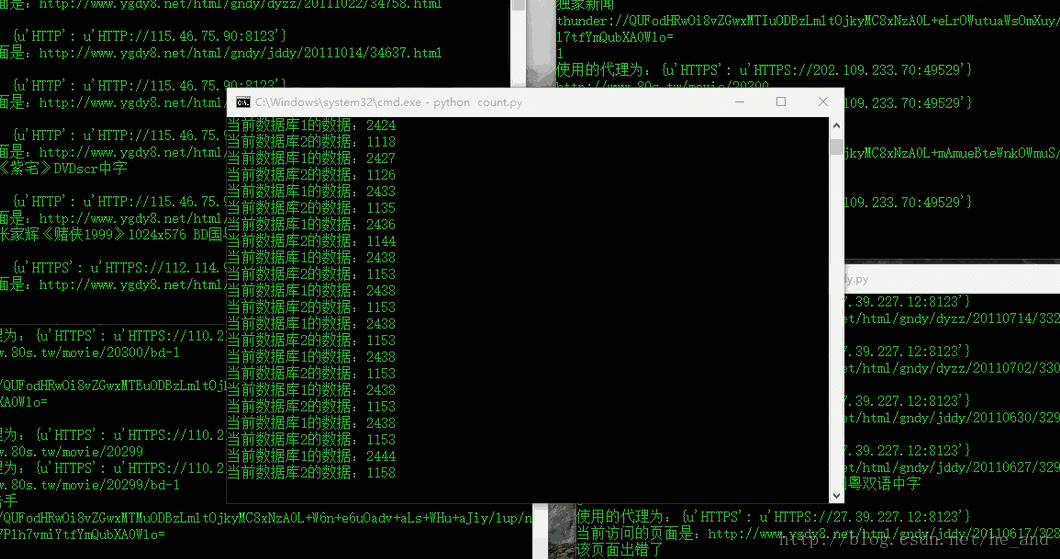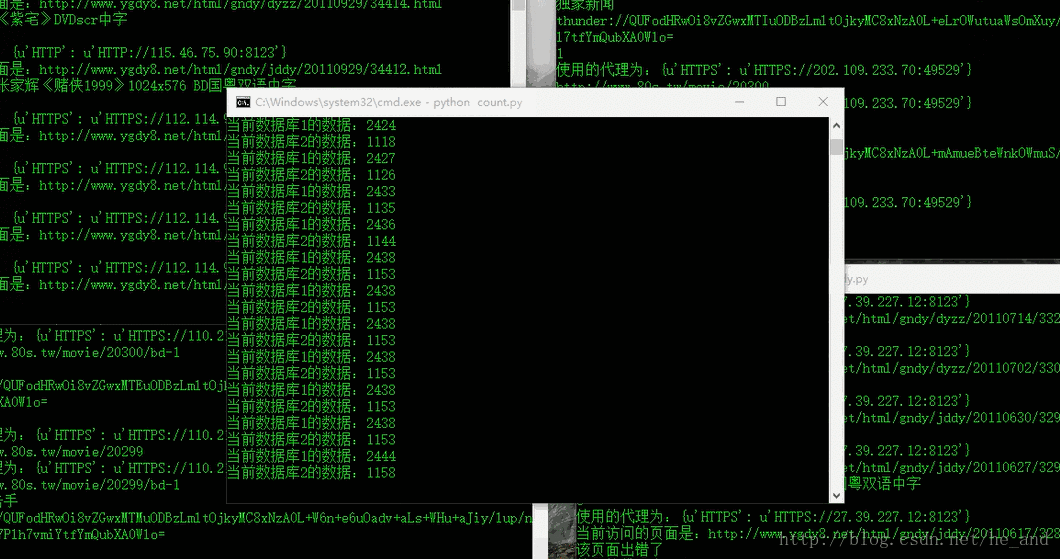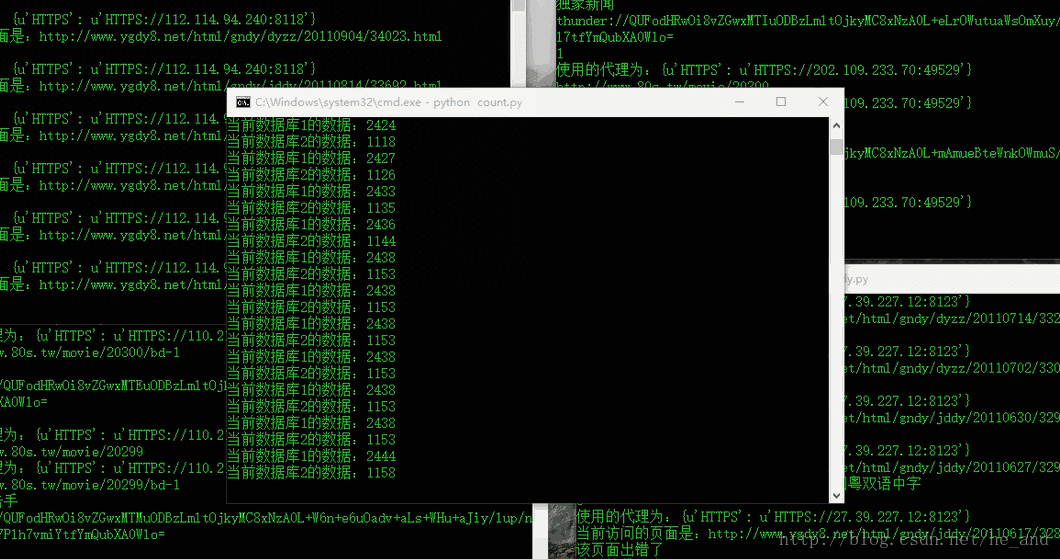
然后,爬虫终于可以愉快的跑起来了,一共爬了一万多条电影数据,下面是部分数据库数据:
除了上面所提到的与反爬虫做斗争外,还有一处知识点,那就是爬取动态的页面,如图所示:
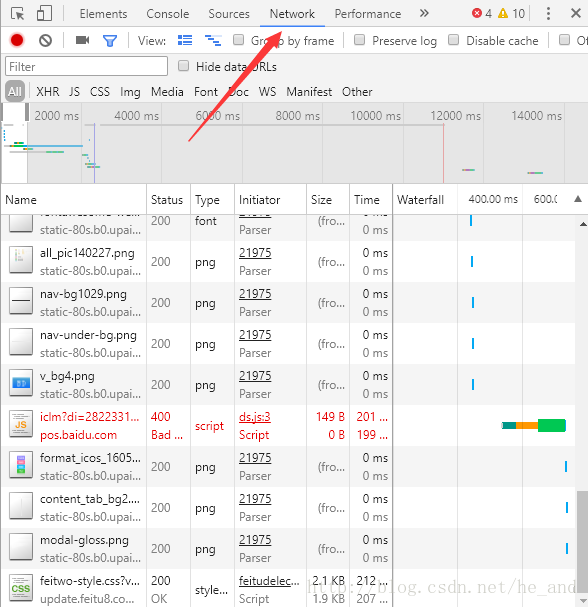
我需要的格式是1024平板MP4,但是个框里的数据时异步加载过来的,所以就只有采用特殊方法了,这个站还算是挺简单的,直接f12大法抓下包看一看就找到了数据源。下面是分析过程:
谷歌浏览器f12打开开发者工具,选择network栏,刷新下就可以捕获到数据包,然后我们点击选择1024平板mp4栏,看看都加载了哪些包
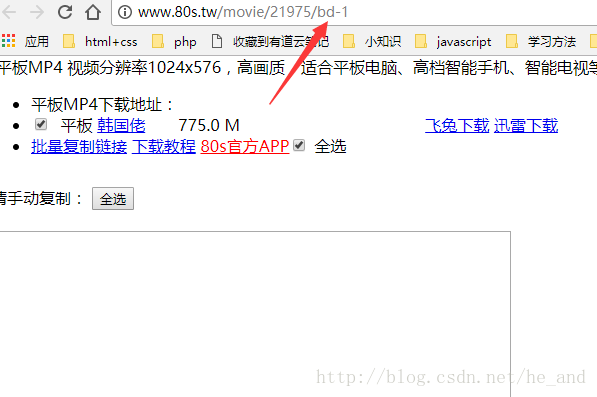
那个bd-1就是我需要的数据包,我直接访问它,就可以看到数据了:
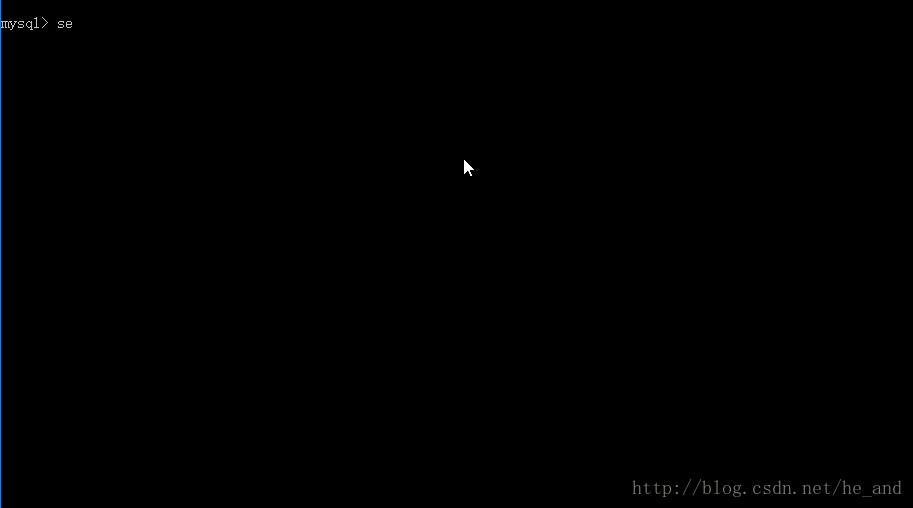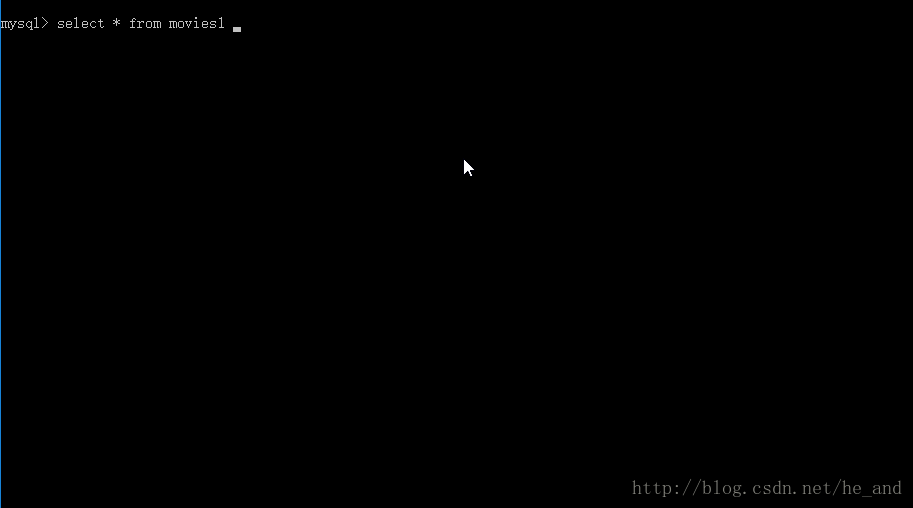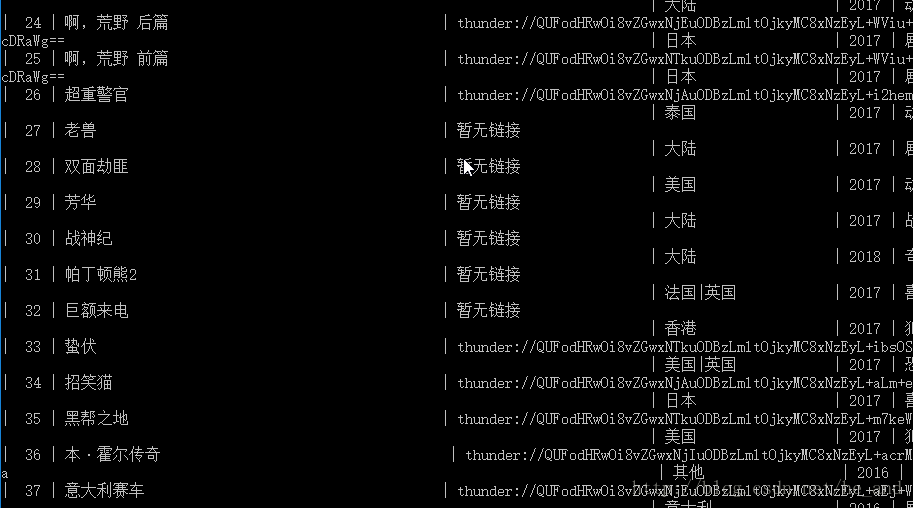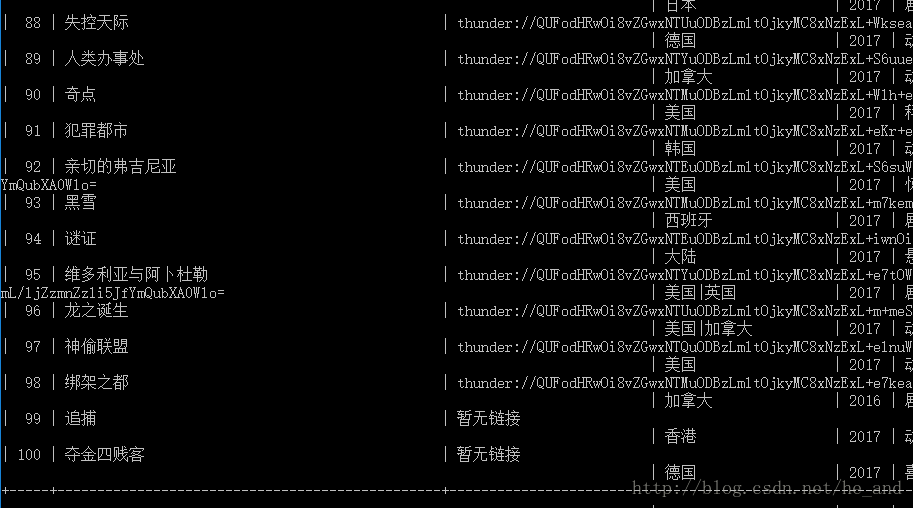
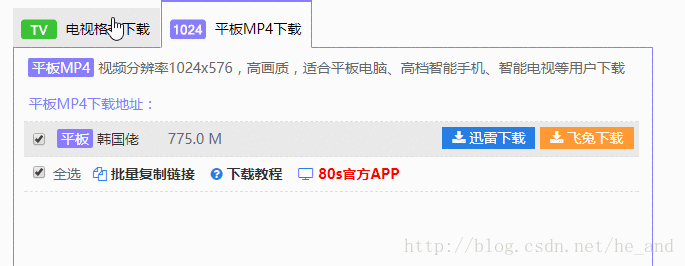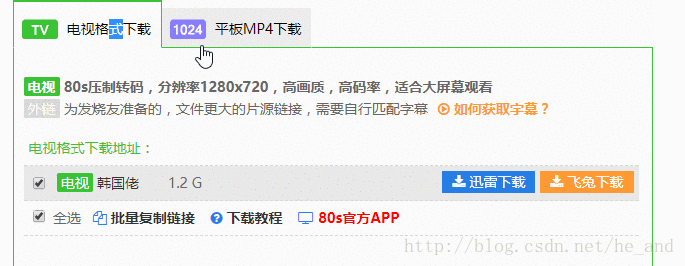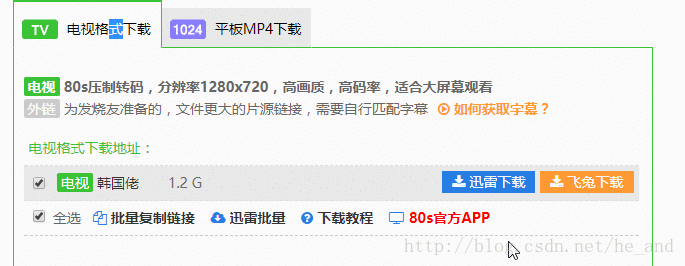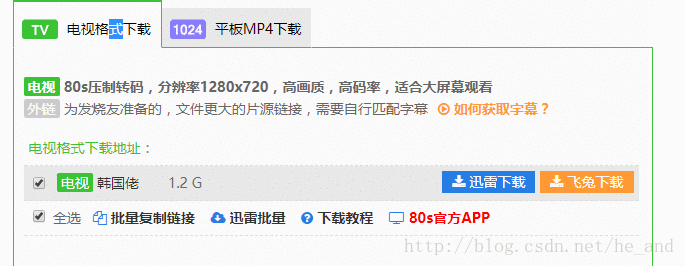
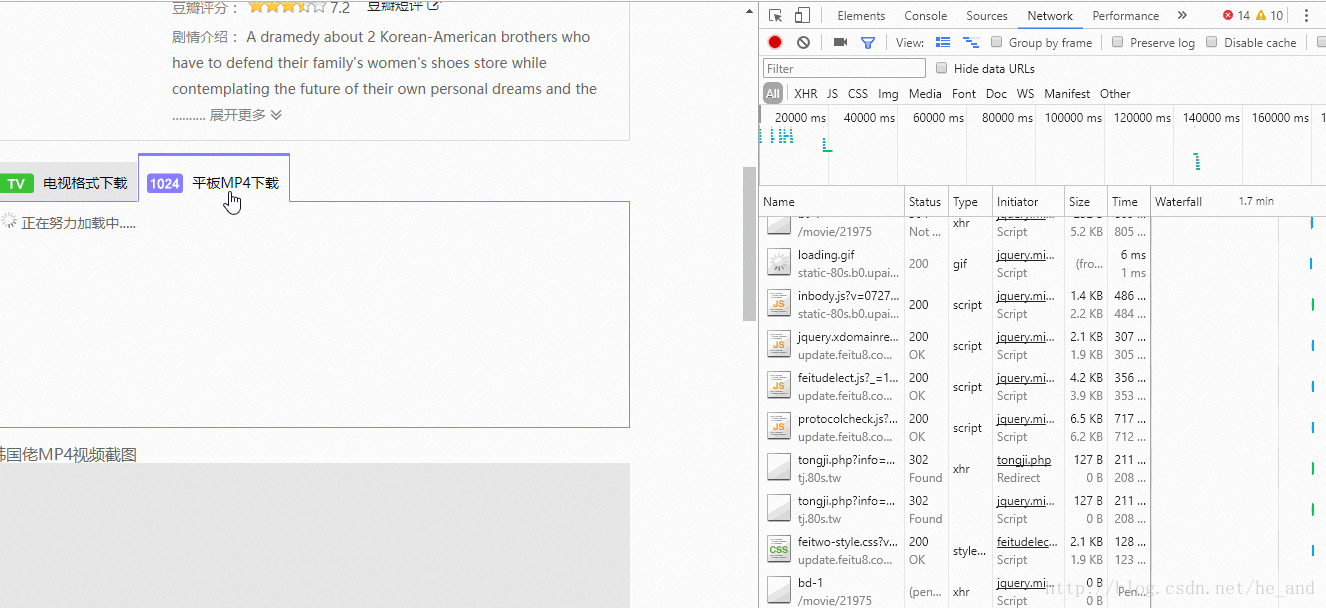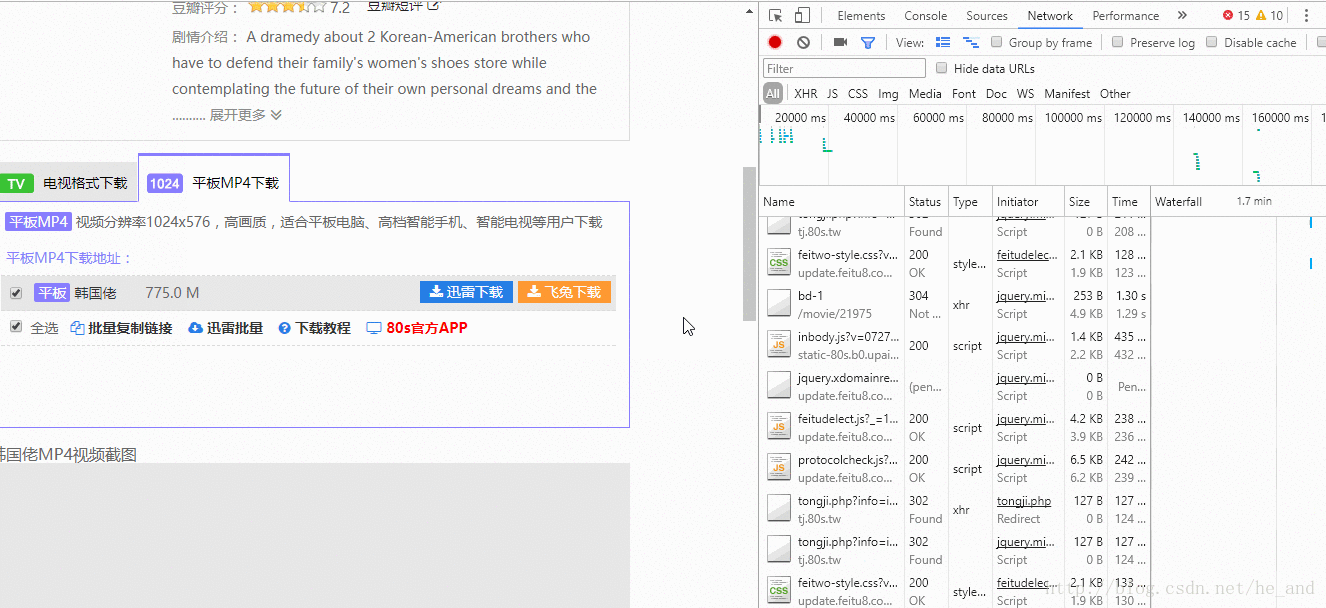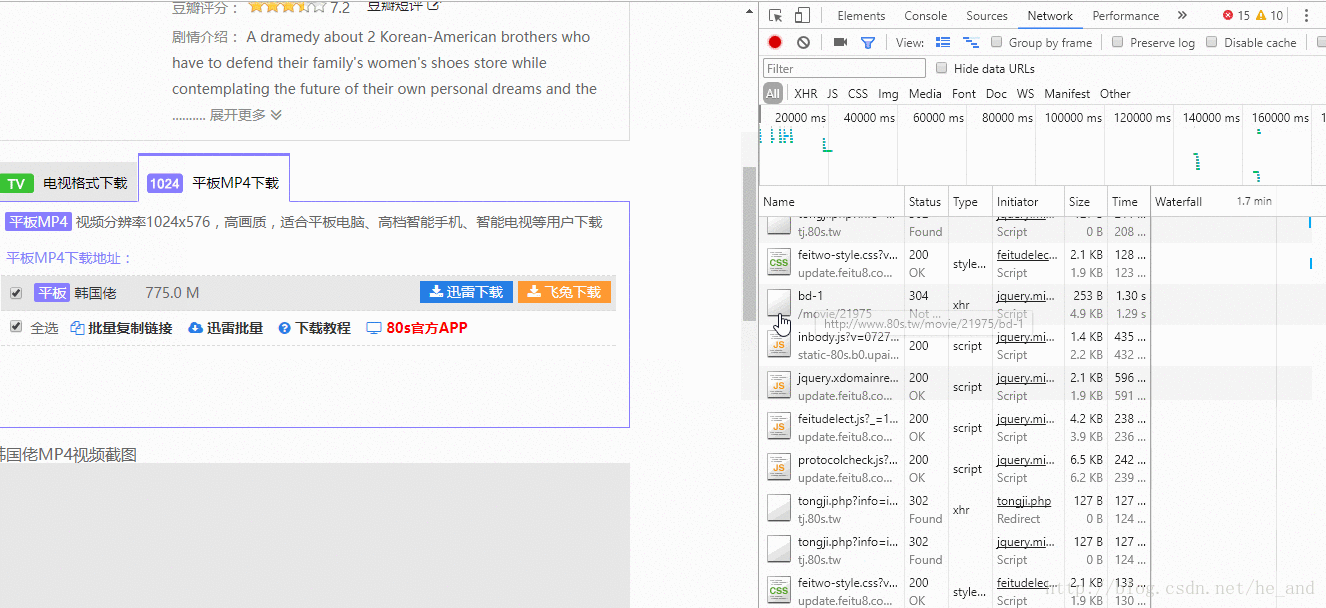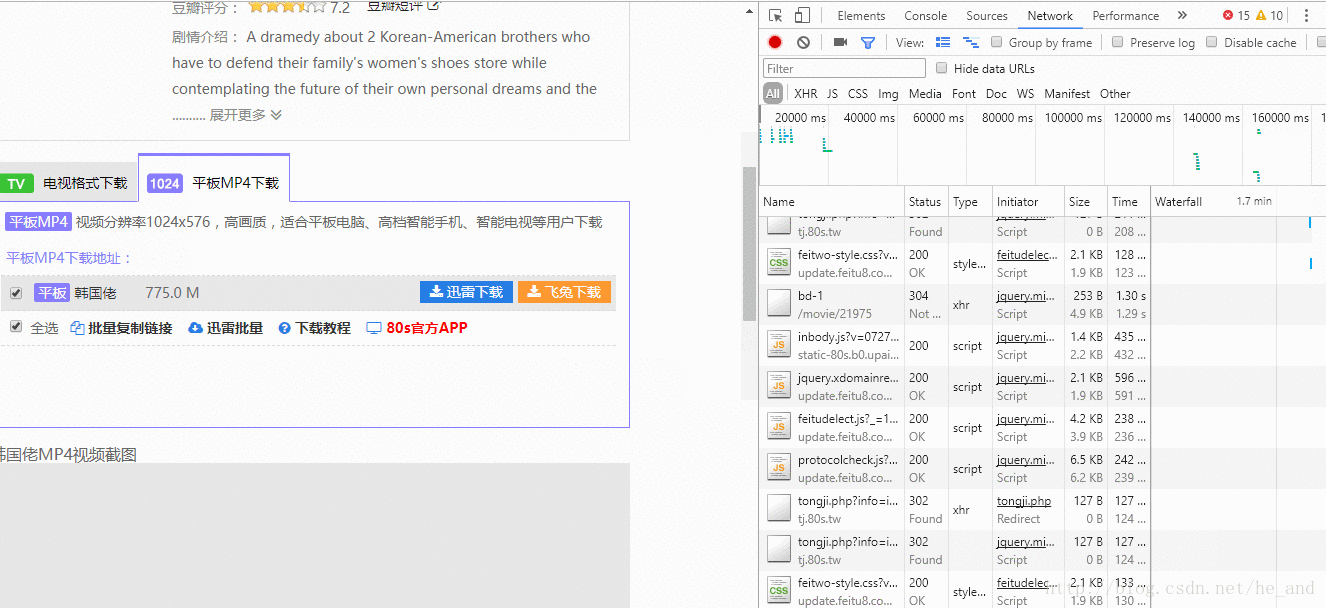
然后我就直接抓取这个链接里的数据就行了。这就算解决了异步数据的获取。
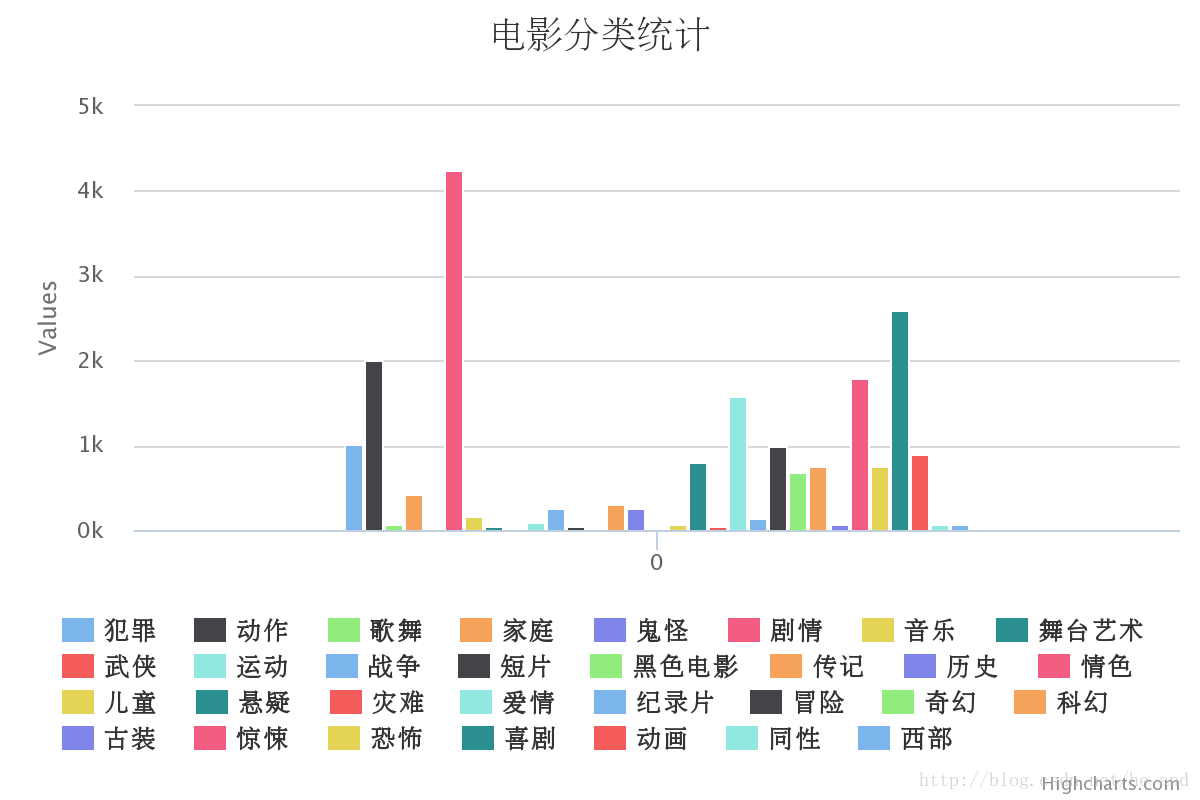
数据都爬完了,我也就顺便统计分析了一下:
数据可视化同样是使用的python实现的,用的是jupyter神器+charts这个库,charts就是python对highcharts的封装,写charts用法的博文比较少,我贴两篇篇还是不错的:
python charts库使用
jupyter+charts
xunsearch使用
xunsearch官方文档
xunsearch只能搭在linux上面,所以只有搭在我的虚拟机中,搭好后试一下在终端里使用下搜索功能,效果如下:
是不是很炫酷?
还有更炫酷的,就是加上网页前端啦,这个时候就需要用到xunsearch的sdk了,调用一下就行了。
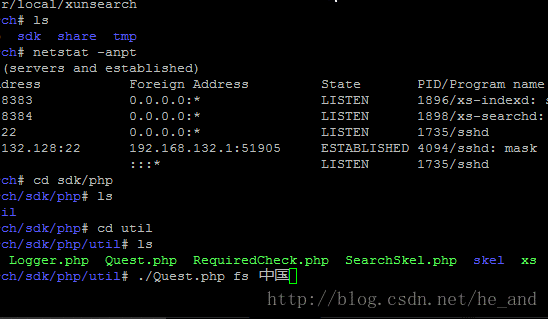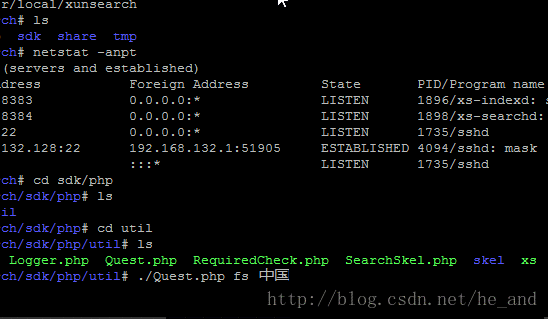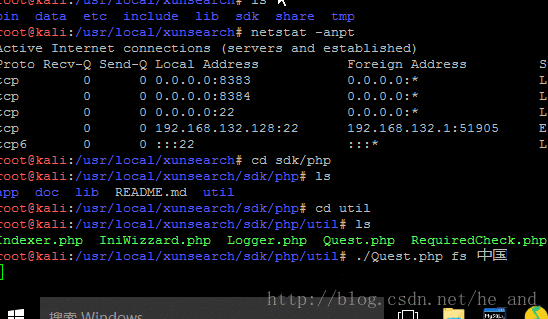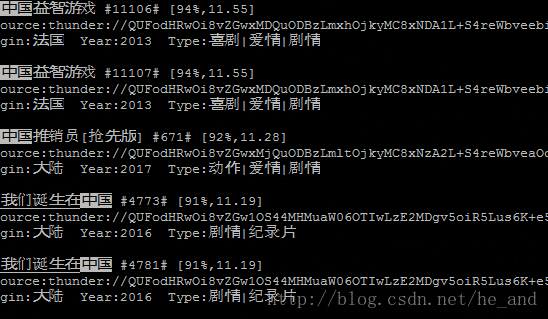

最后上一个爬虫图片压压惊















 2404
2404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









