







目录
接着上篇文章调试Spring Cloud留下的问题{"code":-107,"message":"Can not find selector, please check your configuration!","data":null},我们继续。
学习java8 stream
从昨天留下的问题,我们定位到下面这段代码匹配返回null,在今天开始前,我们不妨细细来了解下这几行代码做了什么事情?首先selectors.stream()的用法,未曾去了解过,网上搜索了解下,这是什么写法?

什么是 Stream?
Stream(流)是一个来自数据源的元素队列并支持聚合操作
- 元素是特定类型的对象,形成一个队列。 Java中的Stream并不会存储元素,而是按需计算。
- 数据源 流的来源。 可以是集合,数组,I/O channel, 产生器generator 等。
- 聚合操作 类似SQL语句一样的操作, 比如filter, map, reduce, find, match, sorted等。
和以前的Collection操作不同, Stream操作还有两个基础的特征:
- Pipelining: 中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluent style)。 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路( short-circuiting)。
- 内部迭代: 以前对集合遍历都是通过Iterator或者For-Each的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。 Stream提供了内部迭代的方式, 通过访问者模式(Visitor)实现。
生成流
在 Java 8 中, 集合接口有两个方法来生成流:
-
stream() − 为集合创建串行流。
-
parallelStream() − 为集合创建并行流。
简单使用介绍
- filter:过滤流中的某些元素
- limit(n):获取n个元素
- skip(n):跳过n元素,配合limit(n)可实现分页
- distinct:通过流中元素的 hashCode() 和 equals() 去除重复元素
- findFirst:返回流中第一个元素
Stream<Integer> stream = Stream.of(6, 4, 6, 7, 3, 9, 8, 10, 12, 14, 14);
Stream<Integer> newStream = stream.filter(s -> s > 5) //6 6 7 9 8 10 12 14 14
.distinct() //6 7 9 8 10 12 14
.skip(2) //9 8 10 12 14
.limit(2); //9 8
newStream.forEach(System.out::println);针对源码写test

翻译源码

selectors会被遍历判断每个SelectorData对象是否enable为true且是否满足选择器的过滤条件,返回整个集合中满足条件的第一个对象,如果都不满足则返回null,我们拿到的结果时null,那么就是filterSelector被返回false了,继续往里面跟。
学习Google Guava的splitter用法
跟到最里边,源码截图如下,发现最终会拿到这个插件的条件来进行匹配,因为我们是被识别到divide插件进入到match方法里面了,所以具体看下matchUrls为matchUrls = "/http/**" , path ="/springCloud/order/findById",好咧,splitter又是啥,又碰到新知识了,那么我们继续网上学习下


初识spliiter
google的guava库是个很不错的工具库,其中spliiter是一个专门用来分隔字符串的工具类。其中有四种用法,分别为根据分隔符分割的基础用法;去除空格,使用omitEmptyStrings ;去除每一行的空格;指定使用哪些字符去除的用法。
具体用法示例可以查看https://blog.csdn.net/qq_17864929/article/details/47805683,写的很好,用一个极好的例子,去讲述了四种用法。
写一个test认识下源码

翻译一下源码意思就是去除matchUrls的每一行的空格,然后以逗号分割转换成list用stream流处理任意匹配,这里用matchUrls就跟path匹配不上,所以就返回false了。再回到最开始的调用方法看一下,截图如下:

但问题来了:为啥传进来的是divide的插件,且做了一圈匹配后,没匹配到就抛出错误了,我们传的是/springCloud/findById,不应该找到springCloud做匹配才对吗?顺着这个疑问,继续往前走,到底是因为什么原因导致传进来的是divide?找到调用的一个方法截图如下:

好吧,又有点没看懂了,那么我们继续做下mono.defer的了解。
学习Mono.defer
反应式编程又叫响应式编程,在维基百科中,其属于声明式编程,数据流。其定义为:反应式编程 (reactive programming) 是一种基于数据流 (data stream) 和 变化传递 (propagation of change) 的声明式 (declarative) 的编程范式。
而今天我们就先来做下反应式编程Mono.defer的了解。
mono.defer方法创建数据源属于懒汉型,当然还有饿汉型,mono.just。
下面我们用一个简易例子做下了解:

我们可以看到,创建了两个数据源,一个使用Mono.just创建,一个用Mono.defer创建,然后分别通过lambda表达式订阅这两个publisher,可以看到两个输出的时间都是10:22:51,延迟5秒钟后重新订阅,Mono.just创建的数据源时间没变,但是Mono.defer创建的数据源时间相应的延迟了5秒钟,原因在于Mono.just会在声明阶段构造Date对象,只创建一次,但是Mono.defer却是在subscribe阶段才会创建对应的Date对象,每次调用subscribe方法都会创建Date对象。参考链接:https://blog.csdn.net/john1337/article/details/104205774。
跟踪源码找真相
有了基本的mono.defer的基本认识后,我们再回到源码,能够了解到是通过一个响应式编程懒加载的方式去做了插件匹配的入口判断,且会通过循环来进行判断每一个插件,这时候先启用sofa来debug看看divide插件的时候,就会发现sofa skip为true,而spring cloud的时候为false。

似乎有点眉目了,再往里看看divide插件的skip逻辑,最终会从exchange这个上下文对象里getAttribute(“context”),然后拿到rpcType来进行判断,而这时候rpcType竟然为http。

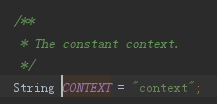
疑问又来了,我们做的是springCloud请求,rpcType为什么会为http呢?继续全文搜索看下什么地方放入context了,找到源码如下:


找到关键点了,会通过metaData元数据的rpcType做一个判断,然后来setRpcType,再来往前走下,metaData是怎么拿到的?
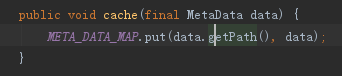


看以上源码,是通过meta_data_map这么个map对象的key来进行匹配的,而这个key是path路径,所以翻译过来就是会拿元数据的path跟请求的path来判断,然后获取metaData对象的,我们查看admin的metaData如下:

path为/springcloud/**,而我们请求路径为springCloud自然就啥都没匹配到,rpcType就只能给个默认http,然后divide插件判断的时候匹配上了,然后匹配divide的规则,然后没匹配到就抛出{"code":-107,"message":"Can not find selector, please check your configuration!","data":null}了,真相大白,我们改下请求的路径为/springcloud/order/findById,终于插件匹配正常了,然后又抛出错误了,错误如下:
{"code":-106,"message":"Can not find url, please check your configuration!","data":null}仔细检查路径正常,那么又是什么其他原因呢?由于时间问题,明天源码跟踪找真相。















 613
613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









