









python虽好用,编码愁死人
做一个服务,需要把数据以json的形式发送出去,服务端写的时候是先把数据保存到字典里,然后通过json的dumps()转化为json ,这里就需注意dumps的具体用法,如下例子所示:
import json
json.dumps("中国")
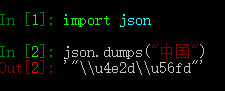
这里输出的是汉字的ascii码,想要输出汉字就需要把参数设置好ensure_ascii=False
json.dumps('中国',ensure_ascii=False)

接下来我们来看一下源码把
def dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True,
allow_nan=True, cls=None, indent=None, separators=None,
default=None, sort_keys=False, **kw):
"""Serialize ``obj`` to a JSON formatted ``str``.
If ``skipkeys`` is true then ``dict`` keys that are not basic types
(``str``, ``int``, ``float``, ``bool``, ``None``) will be skipped
instead of raising a ``TypeError``.
If ``ensure_ascii`` is false, then the return value can contain non-ASCII
characters if they appear in strings contained in ``obj``. Otherwise, all
such characters are escaped in JSON strings.
If ``check_circular`` is false, then the circular reference check
for container types will be skipped and a circular reference will
result in an ``OverflowError`` (or worse).
If ``allow_nan`` is false, then it will be a ``ValueError`` to
serialize out of range ``float`` values (``nan``, ``inf``, ``-inf``) in
strict compliance of the JSON specification, instead of using the
JavaScript equivalents (``NaN``, ``Infinity``, ``-Infinity``).
If ``indent`` is a non-negative integer, then JSON array elements and
object members will be pretty-printed with that indent level. An indent
level of 0 will only insert newlines. ``None`` is the most compact
representation.
If specified, ``separators`` should be an ``(item_separator, key_separator)``
tuple. The default is ``(', ', ': ')`` if *indent* is ``None`` and
``(',', ': ')`` otherwise. To get the most compact JSON representation,
you should specify ``(',', ':')`` to eliminate whitespace.
``default(obj)`` is a function that should return a serializable version
of obj or raise TypeError. The default simply raises TypeError.
If *sort_keys* is true (default: ``False``), then the output of
dictionaries will be sorted by key.
To use a custom ``JSONEncoder`` subclass (e.g. one that overrides the
``.default()`` method to serialize additional types), specify it with
the ``cls`` kwarg; otherwise ``JSONEncoder`` is used.
"""
# cached encoder
if (not skipkeys and ensure_ascii and
check_circular and allow_nan and
cls is None and indent is None and separators is None and
default is None and not sort_keys and not kw):
return _default_encoder.encode(obj)
if cls is None:
cls = JSONEncoder
return cls(
skipkeys=skipkeys, ensure_ascii=ensure_ascii,
check_circular=check_circular, allow_nan=allow_nan, indent=indent,
separators=separators, default=default, sort_keys=sort_keys,
**kw).encode(obj)
函数中有如下的说明,If ensure_ascii is false, then the return value can contain non-ASCII
characters if they appear in strings contained in obj. Otherwise, all
such characters are escaped in JSON strings.
如果是false的话就会返回给JSONEncoder以进行 编码,以返回非ascii码
if isinstance(o, str):
if self.ensure_ascii:
return encode_basestring_ascii(o)
else:
return encode_basestring(o)
def encode_basestring(string): # real signature unknown; restored from __doc__
"""
encode_basestring(string) -> string
Return a JSON representation of a Python string
"""
return ""
之后转json的时候一定的注意这个问题
编码就是使用python中最常出现的问题,真是。。。















 544
544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









