






大数据系统综述
大数据的特征(five V):
1.体量大(volume)
2.速度快(velocity)
3.模态多(variety)
4.难辨识(veracity)
5.价值大密度低(value)
大数据难点:
1.数据类型多(variety)
2.要求及时响应(velocity)
3.数据的不确定性(veracity)
大数据时代处理数据的理念:
1.要全体不要抽样
2.要效率不要绝对精确
3.要相关不要因果
大数据处理形式:
- 对静态数据的批量处理(1-1)
- 对在线数据的实时处理
1. 对流式数据的处理(1-2)
2. 实时交互计算(1-3) - 对图数据(graph)的综合处理(1-4)
1-1批量数据处理
数据特征:
1.体量大(PB级别)。静态形式存在硬盘中,很少更新,存储时间长,可重复利用。
2.数据精度高。往往是从应用中沉淀下来的,宝贵财富。
3.价值密度低。以视频批量数据为例,可能有用的数据仅为一两秒。需要通过合理的算法从批量数据中抽取有用的价值。
批量处理比较耗时,不提供用户与系统的交互手段。所以当发现结果和预期或以往结果差别较大时,会浪费时间。因此,批量数据处理适合大型的相对成熟的作业。
典型应用:
1.以人为核心的社交网络产生了大量文本,图片,音视频等不同形式的数据。对社交网络进行分析,发现人与人之间隐含的关系,推荐朋友或相关的主题,提升用户体验。
2.电子商务中大量购买历史记录,商品评论,商品网页的访问次数和驻留时间等数据。分析出用户的消费行为,为客户推荐相关商品,提升优质客户数量。
3.搜索引擎的广告分析系统,改善广告的投放效果提高点击量。
代表性处理系统:
Google文件系统GFS,MapReduce编程模型(由于未开源,后来被Hadoop的开源产品:HDFS,MapReduce.Hadoop部分取代)。
由HDFS负责静态数据的存储,并通过MapReduce将计算逻辑分配到各数据节点进行数据计算和价值发现。
1-2流式数据处理系统
流式数据处理源于服务器日志的实时采集,交互式数据处理的目标是将PB级别的处理时间缩短到秒级。
数据特征:
流式数据是一个无穷的数据序列,序列中每个元素来源各异。
共同点:
1.序列往往包含时序特性,或者其他的有序标签(如IP报文中的序号)
2.数据流中数据格式可以是结构化,半结构化,甚至无结构化。
3.数据是流动的(用完即弃)
典型应用:
1.传感器采集系统(物联网)通过采集传感器的信息,实习分析提供动态的信息显示,应用于智能交通,环境监控,灾难预警。
2.Web数据采集系统利用网络爬虫程序抓取Web上的内容,通过清洗,归类,分析并挖掘其数据价值。
流式数据对应的处理工具需具备高性能,实时,可扩展等特性。
代表性处理系统:
Storm,Nutch。
Storm系统:
其流式处理作业被分发至不同类型的组件,每个组件负责一项简单,特定的处理任务。
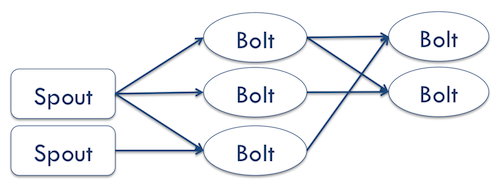
1.Spout组件:Storm集群的输入流,Spout组件将数据传递给名为Bolt的组件。
2.Bolt组件:以特定方式处理数据,如持久化或转发给另外的Bolt。
Storm集群可以看成一条由Bolt组件组成的链(称为一个Topology)。每个Bolt对Spout产生出来的数据做某种方式的额处理。
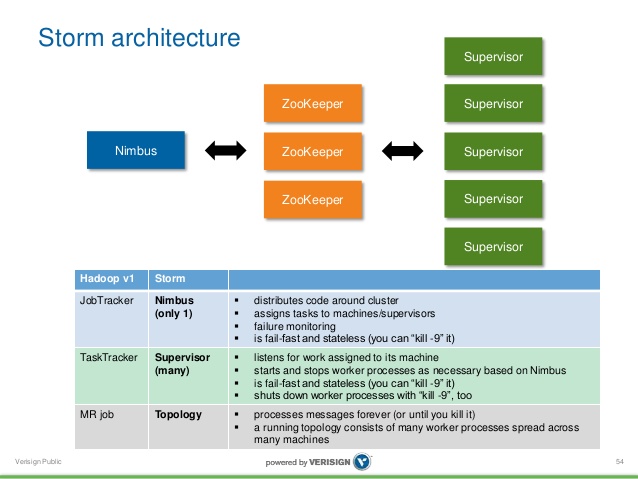
1.Nimbus节点:负责提交任务,分发执行代码,为每个工作结点指派任务和监控失败的任务
2.Zookeeper节点:负责Storm集群的协同操作
3.Supervisor节点:负责启动多个Worker进程,执行Topology的一部分,这个过程是通过Zookeeper节点与Nimbus节点通信完成的。
因为Storm将所有的集群状态保存在Zookeeper或者本地磁盘上,Supervisior节点是无状态的,因此其失败或者重启不会引起全局的重新计算。
1-3交互式数据处理
数据特征:
人机对话的方式,操作人员提出请求,数据以对话的方式输入,系统便提供相应的数据或提示信息,引导操作人员逐步完成所需的操作,直至获取最后处理结果。
典型应用:
1.信息处理系统领域,目前基于开源体系架构下的数据仓库系统以Hive,Pig为代表的分布式数据仓库发展迅速。
2.互联网领域,主要体现人际间的交互。为了交互性数据处理的实时性需求,各大平台主要使用NoSQL类型的数据库系统。如HBase采用多维有序表的列式存储方式;MongoDB采用JSON格式的数据嵌套存储方式。大多NoSQL数据不提供Join等关系型数据库的操作模式,以增加数据操作的实时性。
代表性处理系统:
Spark:基于内存计算的可扩展的开源集群计算系统。针对MAPReduce的不足(大量的网络传输和磁盘I/O),Spark使用内存进行数据计算以便快速处理查询。
Spark的计算架构3特点:
1.拥有轻量级的集群计算框架
2.包含大数据领域的数据流计算和交互式计算。Spark可以与HDFS交互取得里面的数据文件,同时Spark的迭代,内存计算,以及交互式计算为数据挖掘和机器学习提供了很好的框架。
3.有很好的容错机制。
1-4图数据处理系统
图由于自身的结构特征,可以很好地表示事物之间的关系。图中点和边的强关联性,需要图数据处理系统对图数据进行操作,包括图数据的存储,图查询,最短路径查询,关键字查询,图模式挖掘以及图数据的分类,聚类等。
数据特征:
1.节点间的关联性。
2.图数据种类繁多。
3.图数据计算的强耦合性。在图中,数据间相互关联,对图数据的计算也是相互关联的。大数据是无法使用单台机器进行处理的,当如果对大图数据进行并行处理,对于每个顶点之间都是连通的图来讲,难以分割成若干完全独立的子图进行独立的并行处理;即使可以分割,也会面临并行机器的协同处理,以及将最后处理结果进行合并等一系列问题。(难点)
代表性图数据处理系统:
Pregel,Neo4j,Trinity
小结
面对大数据,各种处理系统层出不穷。总体来说,有3种发展趋势:
1.数据处理引擎专用化:为了降低成本,提高能效,大数据系统需要摆脱传统的通用体系,趋向专用化架构技术。
2.数据处理平台多样化
3.数据计算实时化:作为批量计算的补充,旨在将PB级数据的处理时间缩短到秒级的实时计算收到更多关注。















 1722
1722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









