







一、什么是json格式
JSON(JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式。它基于 ECMAScript 规范的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
举例:
{
"infoBox": {
"籍贯:": "台湾",
"性别:": "男",
"经纪公司:": "杰威尔音乐有限公司",
"出生年月:": "1979年1月18日",
"主要成就:": "两届台湾金曲奖最佳国语男歌手获得十五座金曲奖(获奖最多)连续7年获得IFPI香港唱片销量大奖十大销量国语唱片",
"出生地:": "台湾新北",
"毕业院校:": "淡江中学",
"英文名:": "Jay Chou",
"民族:": "汉族",
"血型:": "O",
"职业:": "歌手、音乐人、制作人、导演、商人",
"星座:": "魔羯座",
"国籍:": "中国",
"代表作品:": "龙卷风、简单爱、七里香、夜曲、青花瓷、稻香、头文字D、不能说的秘密、逆战、青蜂侠、天台",
"中文名:": "周杰伦",
"别名:": "周董"
},
"openType:": ["艺人"],
"infoName:": "周杰伦"
}二、什么是RDF格式
资源描述框架 (RDF) 是描述网络中资源的 W3C 标准。
RDF 是一个框架,用来描述网络资源,诸如网页的标题、作者、修改日期、内容以及版权信息等。
具体可参考W3Cschool RDF 教程
举例:
<?xml version="1.0" encoding="UTF-8"?>
<rdf:RDF
xmlns:ns1="http://baike.com/resource/"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
>
<rdf:Description rdf:about="http://baike.com/resource/周杰伦">
<ns1:代表作品 rdf:resource="http://baike.com/resource/不能说的秘密"/>
</rdf:Description>
</rdf:RDF>三、读json文件
# -*- coding: utf-8 -*-
import json
f = open('data.json', 'r')
for line in f:
print line结果:
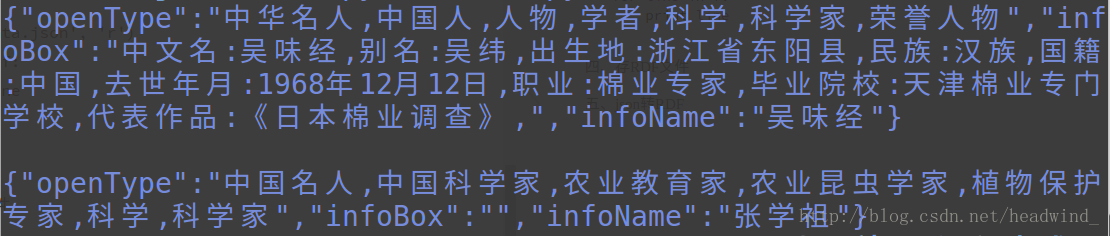
四、存RDF文件
这里使用的是Python的一个库:RDFlib
安装使用参考:RDFLib/rdflib · GitHub
# -*- coding: utf-8 -*-
import rdflib
g = rdflib.Graph()
s = rdflib.URIRef('http://baike.com/resource/周杰伦')
p = rdflib.URIRef('http://baike.com/resource/代表作品')
o = rdflib.URIRef('http://baike.com/resource/不能说的秘密')
g.add((s, p, o))
g.serialize('hello.rdf') # 默认以'xml'格式存储结果:
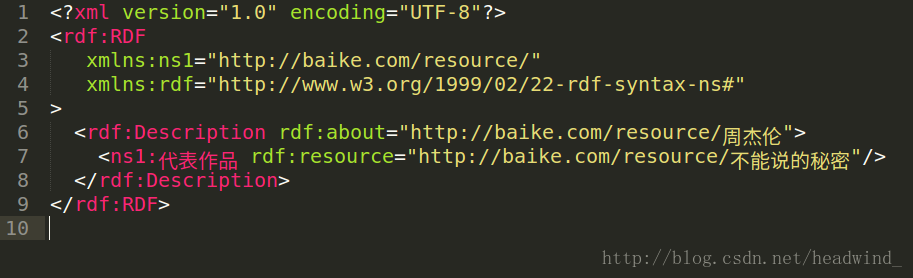
五、json转RDF
最后这里是将上一篇《利用scrapy框架爬取互动百科的词条–存成json》存的json文件保存为RDF文件作为知识库保存起来
# -*- coding: utf-8 -*-
import json
import re
import rdflib
f = open('data.json', 'r')
g1 = rdflib.Graph()
cnt = 0
for line in f:
#txt = eval("{" + line + "}")
txt = eval(line)
cnt = cnt + 1
print cnt
try:
s = rdflib.URIRef('http://baike.com/resource/' + txt['infoName'])
p = rdflib.URIRef('http://baike.com/resource/开放分类')
opentype = re.split(r',', txt['openType'])
for i in range(len(opentype) - 1):
o = rdflib.URIRef('http://baike.com/resource/' + opentype[i])
g1.add((s, p, o))
o = rdflib.URIRef('http://baike.com/resource/' +
opentype[len(opentype) - 1])
g1.add((s, p, o))
# g1.serialize('da.rdf')
if len(txt['infoBox']) != 0:
box = re.split(r',', txt['infoBox'])
for num in range(len(box) - 1):
lastbox = re.split(r':', box[num])
print len(lastbox)
if len(lastbox) == 2:
print lastbox[0]
print lastbox[1]
try:
rtxt = re.compile(
r'"| | | |:|:|、|。|\(|\)|(|)|℃|}|{')
lastKey = rtxt.sub('', lastbox[0])
p = rdflib.URIRef(
'http://baike.com/resource/' + lastKey)
rtxt = re.compile(r'"| |\>|}|{')
lastTest = rtxt.sub('', lastbox[1])
lastTestChild = re.split(
r'、|,|;|;|,|\|', lastTest)
for i in range(len(lastTestChild) - 1):
o = rdflib.URIRef(
'http://baike.com/resource/' + lastTestChild[i])
g1.add((s, p, o))
o = rdflib.URIRef(
'http://baike.com/resource/' + lastTestChild[len(lastTestChild) - 1])
g1.add((s, p, o))
# g1.serialize('da.rdf')
except:
pass
except Exception as e:
pass
g1.serialize('data.rdf')
# print box[num]
f.close()
测试数据与程序:点击下载















 1671
1671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









