




 本文介绍如何使用Python的BeautifulSoup库解析HTML文件。通过实例演示了如何读取HTML文档、获取文档标题及其内容,以及查找特定元素等基本操作。
本文介绍如何使用Python的BeautifulSoup库解析HTML文件。通过实例演示了如何读取HTML文档、获取文档标题及其内容,以及查找特定元素等基本操作。
Beautiful Soup是python的一个解析HTML或XML格式文件的包,Beautiful Soup 3已经不在开发,现在一般使用Beautiful Soup 4。学习BS4最好的方法是找一段网页例子来进行解析,我们先来写一段HTML代码。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>父亲</title>
<link rel="stylesheet" type="text/css" href="father.css">
<link rel="stylesheet" type="text/css" href="./css/bootsrap.min.css">
</head>
<body background="./image/bg.jpg">
<div id='head1'><h1>亲爱的父亲,我想对你说:</h1></div>
<div>
<ui>
<li class="item1">感谢一路上有你!!!</li>
<li class="item2">感谢一路上有你!!!</li>
<li class="item3">感谢一路上有你!!!</li>
<li class="item4">感谢一路上有你!!!</li>
<li class="item5">感谢一路上有你!!!</li>
<li class="item6">感谢一路上有你!!!</li>
<li class="item7">感谢一路上有你!!!</li>
<li class="item8">感谢一路上有你!!!</li>
<li class="item9">感谢一路上有你!!!</li>
<li class="item10">感谢一路上有你!!!</li>
</ui>
</div>
</body>
</html>我们将上边的代码保存成’father.html’, 然后用BS4来解析它。
>>> from bs4 import BeautifulSoup
>>> html_doc = open('father.html').read()
>>> soup = BeautifulSoup(html_doc)
# 直接传入文件句柄也是可以的
# soup = BeautifulSoup(open('father.html')) 跟上边效果一样现在通过BeautifulSoup的解析就可以得到一个BeautifulSoup对象,使用该对象的prettify方法,可以将代码按照标准缩进打印出来。
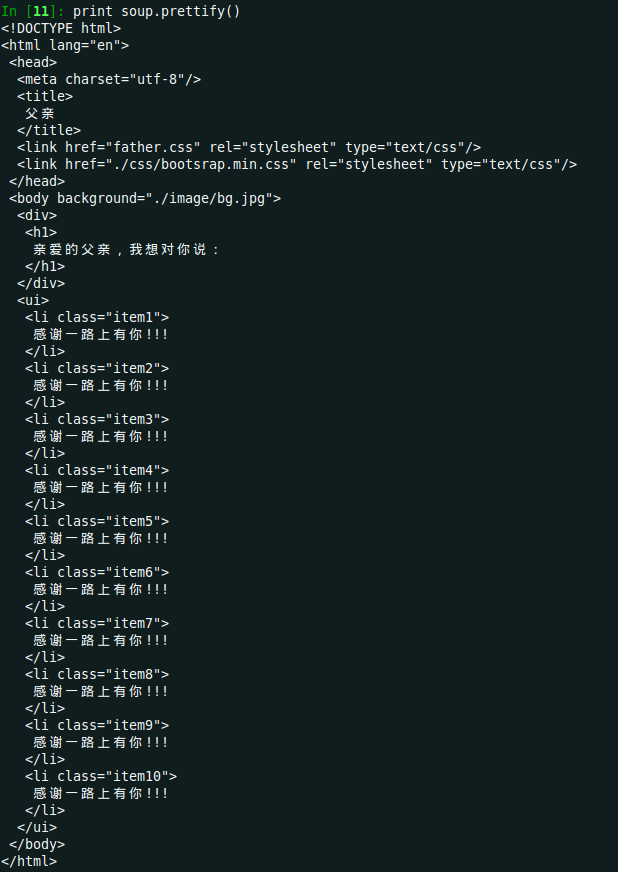
是不是很漂亮-_-
有了包含网页信息的BeautifulSoup对象,我们就可以愉快的解析网页了,先来几个小栗子尝尝-_-
>>> soup.title #输出文档title,含标签
<title>父亲</title>
>>> print soup.title.string #输出title内容
父亲
>>> soup.find_all('li')
[<li class="item1">感谢一路上有你!!!</li>,
<li class="item2">感谢一路上有你!!!</li>,
<li class="item3">感谢一路上有你!!!</li>,
<li class="item4">感谢一路上有你!!!</li>,
<li class="item5">感谢一路上有你!!!</li>,
<li class="item6">感谢一路上有你!!!</li>,
<li class="item7">感谢一路上有你!!!</li>,
<li class="item8">感谢一路上有你!!!</li>,
<li class="item9">感谢一路上有你!!!</li>,
<li class="item10">感谢一路上有你!!!</li>]有了BS4, 就不用我们自己去编写正则表达式来解析网页了,是不是很方便呢。

















 56万+
56万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









