







大数据Hadoop(一)
大数据引言
-
什么是大数据?
体量很大的数据,起步存储当量为TB级或者日均数据增长GB级。 在海量数据下,可以进行分析,挖掘,进而发现数据内在的规律,从而为企业或者国家创造价值。 -
大数据有什么特点?
#4v特性 1. Volume:体量大 2. Variety:样式多 数据种类多 2.1 结构化数据 2.2 半结构化数据 json xml 2.3 非结构化数据 图片 音频 视频 3. Velocity:速度快 4. Value:低价值密度的数据,挖掘出高价值。 -
大数据起源
Google是最早面临大数据问题的公司,推出了第一个大数据解决方案。 1. GFS google File System 谷歌文件处理系统 2. MapReduce 3. BigTable (NoSQL 数据库) -
大数据处理的核心数据类型
文本数据 -
大数据的数据来源
1. 公司系统运行产生的 日志 (Nginx,Log4j[埋点日志],数据库中的数据) 2. 爬虫 3. 行业大数据 电信 医疗 政府 金融 4. 大数据交易
Hadoop框架
-
起源
Doug Cutting 是Lucene(全文搜索技术 Solr ES)、Nutch的作者,后续设计开发了Hadoop体系。 Hadoop1.x HDFS(Hadoop Distributed File System) 对应 GFS MapReduce 对应 MapReduce HBase 对应 BigTabel apache组织正式开源Hadoop,并把Hadoop作为了顶级项目。 -
Hadoop生态圈
1. Hadoop Core (HDFS,MR MapReduce) 2. Hadoop生态工具 (Hive,HBase) 3. Hadoop辅助工具 (Flume,Sqoop,Oozie,Hue) -
大数据核心技术
1. HDFS 文件处理系统 (IO) 存数据 取数据 2. MapReduce 编程,数据的计算 3. Hive (HQL Hive Query Lanuage) 类似SQL 95%和SQL语法一致 4. HBase (NoSQL) 存 取数据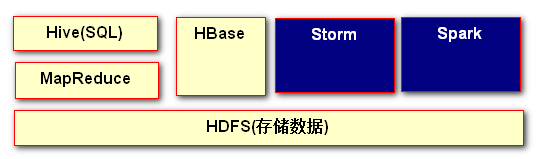
构建Hadoop的伪分布式系统【HDFS,MapReduce】
(伪分布式系统:只需要一台虚拟机,简易的模拟集群的工作,熟悉hdfs运用)
-
什么是HDFS?
HDFS 全称是Hadoop Distributed File System hadoop分布式(cluser)文件存储系统。 -
HDFS基本架构

-
Hadoop伪分布式搭建[HDFS,Yarn]
--以下安装是我的个人习惯,可根据个人需要进行调整 /opt/models 原始文件(压缩文件) /opt/install 安装文件放置的位置1. linux服务器的基本配置 设置ip,关闭防火墙,关闭selinux,配置主机名,主机与ip映射 设置ip,关闭防火墙,关闭selinux,配置主机名,主机与ip映射 设置ip: vi /etc/sysconfig/network-scripts/ifcfg-eth0 设置IPADDR 关闭防火墙: service iptables stop 关闭防火墙开机自启动: chkconfig iptables off 关闭selinux: vi /etc/selinux/config 设置 SELINUX=disabled 配置主机名: vi /etc/sysconfig/network 主机与ip映射:(建议两个都设置) linux:vi /etc/hosts windows: 在 C:\Windows\System32\drivers\etc目录下的 hosts 文件,使用记事本 或者 notepad++ 打开,进行添加: linux-ip linux主机名 2. 安装jdk1.7+(在jdk压缩包所在目录下) rpm -ivh jdk-7u71-linux.x64.rpm 默认安装位置 /usr 环境变量的配置 vi /etc/profile 环境变量 linux 所有用户生效 vi /.bash_profile 环境变量 当前用户生效 vi /.bashrc (bash_profile bashrc 都是/root目录下的隐藏文件) JAVA_HOME=/usr/java/jdk1.7.0_71 CLASSPATH=. PATH=$JAVA_HOME/bin:$PATH:$HOME/bin export JAVA_HOME export CLASSPATH export PATH source .base_profile

3. 安装hadoop
tar -zxvf hadoop-2.5.2.tar.gz -C /opt/install
4. Hadoop配置文件的配置 etc/hadoop
4.1 hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_71
4.2 core-site.xml
<!--用于设置namenode并且作为java程序的访问入口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop2:8020</value>
</property>
<!--存储namenode持久化的数据,Datenode块数据-->
<!--手工创建$HADOOP_HOME/data/tmp-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/install/hadoop-2.5.2/data/tmp</value>
</property>
4.3 hdfs-site.xml
<!--设置副本数量 默认是3 但是单节点测试,改成1-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
4.4 mapred-site.xml
<!--yarn 与 MR相关-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
4.5 yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
4.6 slaves
hadoop2
5. namenode的格式化 【第一次搭建hdfs集群时需要使用】
目的作用:格式化hdfs系统,并且生成存储数据块的目录
bin/hdfs namenode -format
6. 启动hadoop守护进程
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
sbin/hadoop-daemon.sh stop namenode
sbin/hadoop-daemon.sh stop datanode
sbin/yarn-daemon.sh stop resourcemanager
sbin/yarn-daemon.sh stop nodemanager
7. 测试验证安装成果
ps -ef | grep java
jps 查看相关4个进程
通过网络进行访问测试
http://hadoop2:8020 yarn
http://hadoop2:50070 hdfs
-
Hadoop HDFS运行过程中的错误分析
查看日志 tail -nxxx 文件名 $HADOOP_HOME/logs [hadoop-用户名-namenode-主机名.log] hadoop-root-namenode-hadoop2.log hadoop-root-datanode-hadoop2.log yarn-root-resourcemanager-hadoop2.log yarn-root-nodemanager-hadoop2.log
HDFS的client访问
-
Shell访问(HDFS 树状文件系统 类似于 linux)

1. 查看目录结构 bin/hdfs dfs -ls 路径 bin/hdfs dfs -ls / 2. 创建文件夹 bin/hdfs dfs -mkdir /suns bin/hdfs dfs -mkdir -p /liuh/xjr 3. 本地上传文件到hdfs中 bin/hdfs dfs -put /root/hdfs/data /suns bin/hdfs dfs -put local_path hdfs_path 4. 查看文件内容 bin/hdfs dfs -text /suns/data bin/hdfs dfs -cat /suns/data 5. 删除 bin/hdfs dfs -rm /suns/data 注意:可以修改垃圾桶的存活时间 core-site.xml <property> <name>fs.trash.interval</name> <value>10</value> </property> 垃圾桶的位置:/user/root/.Trash/190522010000/suns/data hdfs:有权限 hdfs-site.xml <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> 6. 删除非空文件夹 bin/hdfs dfs -rmr /suns 7. 从hdfs下载文件到本地 bin/hdfs dfs -get /suns/data /root/hdfs bin/hdfs dfs -get hdfs_path local_path 8. cp mv制定 hadoop的启停脚本 shell脚本 当前目录执行方式 ./hadoop-start.sh 绝对路径执行shell /opt/install/hadoop-2.5.2/hadoop-start.sh linux hadoop-start.sh #!bin/bash sbin/hadoop-daemon.sh start namenode sbin/hadoop-daemon.sh start datanode sbin/yarn-daemon.sh start resourcemanager sbin/yarn-daemon.sh start nodemanager hadoop-stop.sh sbin/hadoop-daemon.sh stop namenode sbin/hadoop-daemon.sh stop datanode sbin/yarn-daemon.sh stop resourcemanager sbin/yarn-daemon.sh stop nodemanager -
java代码的方式
-
准备
1. windows 系统 安装java 安装IDE(IDEA) 2. maven 安装,并且设置 阿里云镜像 加压缩,设置环境变量(MAVEN_HOME,M2_HOME),修改配置文件(本地库的位置,添加阿里云镜像) 3. IDEA 模块 HDFS java访问 -
编程
-
hdfs相关jar,maven坐标
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.5.2</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.5.2</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.5.2</version> </dependency> -
HDFS访问过程中核心的API
1. Configuration 配置 什么是hdfs的配置? 进行core-site.xml hdfs-site.xml 配置信息的读取操作 2. FileSystem 代表的就是 HDFS分布式文件系统 3. IOUtils IO操作的工具类 -
代码
public class TestHDFS { @Test public void test1() throws Exception{ Configuration conf = new Configuration(); conf.set("fs.defaultFS","hdfs://hadoop2:8020"); FileSystem fileSystem = FileSystem.get(conf); FSDataInputStream fsDataInputStream = fileSystem.open(new Path("/liuh/xiaohei/data")); IOUtils.copyBytes(fsDataInputStream, System.out, 1024, true); } @Test public void test2() throws Exception { FileSystem fileSystem = getFileSystem(); FSDataInputStream fsDataInputStream = fileSystem.open(new Path("/liuh/xiaohei/data")); IOUtils.copyBytes(fsDataInputStream,System.out,1024,true); } @Test public void test3()throws Exception { Configuration conf = new Configuration(); conf.addResource(new Path("C:\\Users\\Administrator\\IdeaProjects\\hadoop_code\\hadoop-hdfs-baizhiedu\\src\\main\\resources\\core-site.xml")); FileSystem fileSystem = FileSystem.get(conf); FSDataInputStream fsDataInputStream = fileSystem.open(new Path("/liuh/xiaohei/data")); IOUtils.copyBytes(fsDataInputStream, System.out, 1024, true); } @Test public void test4()throws Exception{ FileSystem fileSystem = getFileSystem(); FSDataInputStream fsDataInputStream = fileSystem.open(new Path("/liuh/xiaohei/data")); //System.out 换成 文件的输出流 FileOutputStream fileOutputStream = new FileOutputStream("f://suns.txt"); IOUtils.copyBytes(fsDataInputStream,fileOutputStream,1024,true); } @Test public void test5()throws Exception{ //FileInputStream 读入文件内容 FileInputStream fileInputStream = new FileInputStream("f://xiaojr.txt"); //HDFS FileSystem.create(); FileSystem fileSystem = getFileSystem(); FSDataOutputStream fsDataOutputStream = fileSystem.create(new Path("/liuh/xiaohei/data1")); //IOUtils IO处理 IOUtils.copyBytes(fileInputStream,fsDataOutputStream,1024,true); } @Test public void test6()throws Exception{ FileSystem fileSystem = getFileSystem(); boolean isOk = fileSystem.mkdirs(new Path("/xiaojr")); System.out.println("创建目录 "+isOk); //fileSystem.delete(new Path(""),true); } private FileSystem getFileSystem() throws Exception{ Configuration conf = new Configuration(); conf.set("fs.defaultFS","hdfs://hadoop2:8020"); FileSystem fileSystem = FileSystem.get(conf); return fileSystem; } }
-
-
Hadoop体系下配置文件优先级详解
1. *-default.xml share jar
core-default.xml HDFS整体设置 设置NameNode入口,namenode持久化,存储位置
hdfs-default.xml 设置与HDFS相关信息 副本数量 块大小 hdfs访问权限
yarn-default.xml 与yarn相关
mapred-default.xml 与mapred相关
2. *-site.xml etc/hadoop
# 如果site.xml 对default对应的key进行了覆盖,那么就按照site的设置,进行处理,如果没有覆盖,则按照 default处理
core-site.xml HDFS整体设置 设置namenode入口,namenode持久化,存储位置
hdfs-site.xml 设置与HDFS相关信息 副本数量 块大小 hdfs访问权限
yarn-site.xml 与yarn相关
mapred-site.xml 与mapred相关
3. 代码 *-site.xml 配置
4. 程序中
Configuration.set()
HDFS分布式集群的构建
- HDFS分布式集群面临的问题

2. ssh免密登录
1. 如何生成公私钥对
ssh-keygen -t rsa 最终放置到 ~/.ssh目录
2. 如何把client的公钥,发送给远端主机
ssh-copy-id root@ip

3. HDFS分布式集群的搭建【简单版】
-
机器的选型
1. NameNode选择 内存大 2. DataNode选择 硬盘大 # namenode节点同时充当datanode -
3个点
1. IP地址 防火墙 selinux 主机名 主机映射 jdk ssh免密登录 2. hadoop 每个节点都要安装hadoop,并且保证配置文件一致 注意:老机器化 删除 hadoop_home/data/tmp 内容 3. 按照分布式集群的要求,书写配置文件,同步集群的每一个节点 hadoop-env.sh export JAVA_HOME=/usr/java/jdk1.7.0_71 core-site.xml <!--用于设置namenode并且作为Java程序的访问入口---> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop:8020</value> </property> <!--存储NameNode持久化的数据,DataNode块数据——> <!--手工创建$HADOOP_HOME/data/tmp--> <property> <name>hadoop.tmp.dir</name> <value>/opt/install/hadoop-2.5.2/data/tmp</value> </property> hdfs-site.xml <!--可选择保留--> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> yarn-site.xml [一样] mapred-site.xml [一样] slaves hadoop2 hadoop3 hadoop4 4. 格式化【namenode】 bin/hdfs namenode -format 5. 启动集群【namenode】 sbin/start-dfs.sh sbin/stop-dfs.sh # shell 命令 执行在namenode所在节点 # java代码访问 不存在任何影响















 394
394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









