






写在前面
视觉语言预训练提高了许多下游视觉语言任务的性能,例如:图文检索、基于图片的问答或推理。有朋友要问了,除了在公开的学术任务上使用更大的模型/更多的数据/技巧把指标刷得很高,多模态预训练模型有什么实际应用呢?

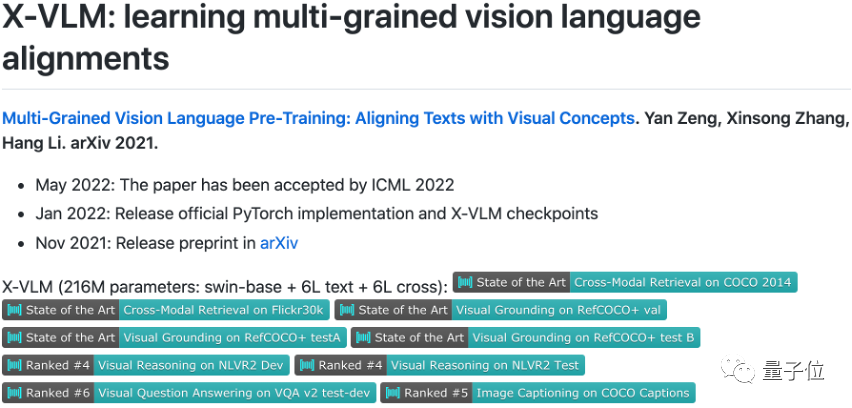
为此,字节跳动 AI Lab Research 团队提出了X-VLM,首次提出学习多粒度的视觉和语言对齐。实验证明,这种预训练方法十分高效,模型规模无需很大,预训练数据无需很多, 仅216M参数量的X-VLM就能在广泛的多模态任务上获得了十分优秀的表现,例如:图像文本检索、基于图片的问答或推理、视觉定位、图片描述生成。目前,X-VLM 在字节跳动的真实应用场景上超过了业界常用的多个模型,完成了上线,服务于如今日头条等业务。相关论文已被ICML 2022接收。
论文:https://arxiv.org/abs/2111.08276 代码:https://github.com/zengyan-97/X-VLM
比如,X-VLM 学到了多粒度的视觉和语言对齐,能为图片生成更正确的描述物体和物体间关系的句子,这项能力被应用到了字节跳动的公益项目上。有视觉障碍的赵先生常用今日头条了解时事新闻,他一直有个期待:“希望和普通人一样‘看’到全部资讯内容。” 今日头条上超过三分之二的资讯内容带有图片,为了解决视障人士的读图难题,今日头条App最近应用了 X-VLM 的生成能力,可以自动识别图片并为它们配上描述。

此外,X-VLM的理解和生成能力还被使用在大力智能学习灯的自动批改功能上。下图展示了补全短语题型以及模型预测的结果:

搭配了自动解题功能的大力智能学习灯广受家长好评,这项能力还在持续优化中。

研究背景
现有的多模态预训练模型大致分为两类:
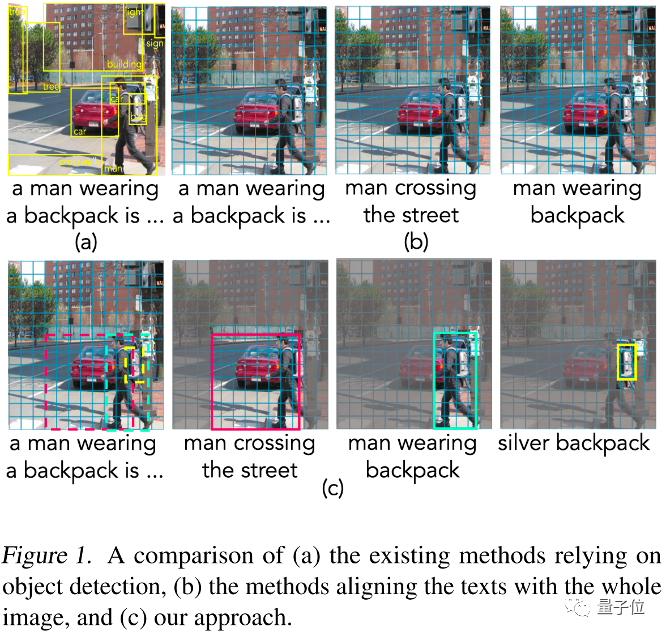
1)依赖目标检测器提取基于物体(例如:车、人、树、背包)的特征来表示图片,这种方法可以学习到物体级别的视觉和语言对齐,如图1中(a)所示。这些方法要么直接利用预先训练的目标检测器,要么将目标检测过程合并到多模态预训练中;
2)用 ResNet 或者 Vision Transformer 编码整张图片,只学习图片和文本之间的对齐,如图1(b)所示。
这两种方法都存在一定的问题。首先,基于目标检测的方法会识别图片中所有可能的物体,其中不乏一些与配对文本无关的。此外,这种方法所提取的基于物体的视觉特征可能会丢失物体之间的信息(可以认为是一种上下文信息)。而且,这种方法只能识别有限种类的物体,我们很难预先定义合适的物体类别。而第二种方法则比较简单直接,但是较难学习到细粒度的视觉和语言对齐,例如:物体级别的对齐。这种细粒度的对齐关系被之前的工作证实对于视觉推理 (visual reasoning) 和视觉定位 (visual grounding) 任务很有帮助。
实际上,对于多模态预训练,有以下公开数据以供模型使用:1)图片和图片标题;2)区域标注,例如:图1中的文本 “man crossing the street” 关联到了图片中的某个具体区域。然而,之前的工作却粗略地将区域标注与整张图片对齐;3)物体标签,例如 “backpack”,这些标注被之前的工作用来训练目标检测器。
与之前的做法不同,本文中作者提出X-VLM,以统一的方式利用上述数据高效地学习多粒度的视觉和语言对齐,能够避免高开销的目标检测过程,也不局限于学习图像级别或物体级别的对齐。具体来说,作者提出可以使用基于 Vision Transformer 的 patch embeddings 来灵活表示各种粒度大小的视觉概念,如图1©所示:例如,视觉概念 “backpack” 由2个patch组成,而视觉概念 “man crossing the street” 由更多的patch组成。
因此,X-VLM学习多粒度视觉和语言对齐的秘诀在于:
1)使用 patch embeddings 来灵活表示各种粒度的视觉概念,然后直接拉齐不同粒度的视觉概念和对应文本,这一过程使用常用的对比学习损失、匹配损失、和MLM损失优化;
2)更进一步,在同一张图片中,给出不同的文本,要求模型能预测出对应粒度的视觉概念的坐标,以边界框坐标的回归损失和交并比损失优化。实验证明,这种预训练方法十分高效,模型规模无需很大,预训练数据无需很多,X-VLM 就能在下游多种多模态理解/生成任务上获得非常优秀的表现。
方法
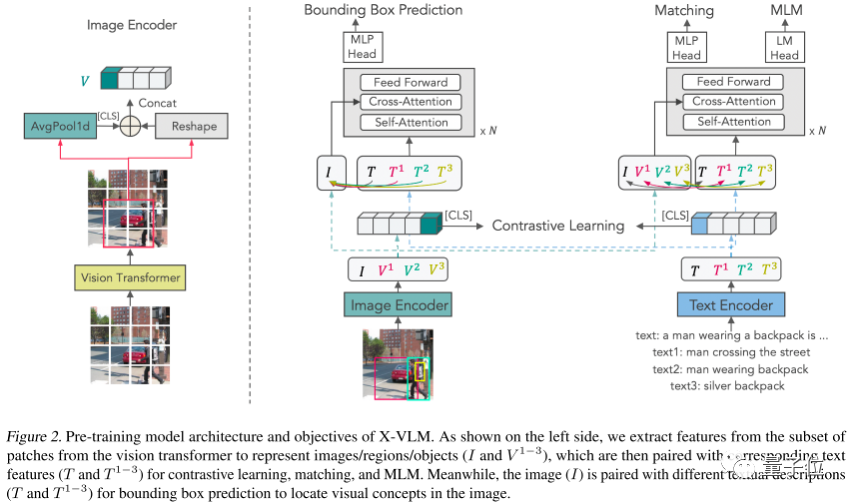
X-VLM 由一个图像编码器,一个文本编码器,一个跨模态编码器组成。
图2左侧给出了视觉概念 (可以是物体/区域/图片)的编码过程:该图像编码器基于Vision Transformer,将输入图片分成patch编码。然后,给出任意一个边界框,灵活地通过取框中所有patch表示的平均值获得区域的全局表示。再将该全局表示和原本框中所有的patch表示按照原本顺序整理成序列,作为该边界框所对应的视觉概念的表示。通过这样的方式获得图片本身(I)和图片中视觉概念(_V_1,_V_2,_V_3)的编码。与视觉概念对应的文本,则通过文本编码器一一编码获得,例如图片标题、区域描述、或物体标签。
X-VLM采用常见的模型结构,其不同之处在于预训练的方法。作者通过以下两类损失进行优化:
第一,在同一张图片中,给出不同的文本,例如:T(text)、_T_1(text1)、_T_2(text2)、_T_3(text3),要求模型预测图片中对应视觉概念的边界框:
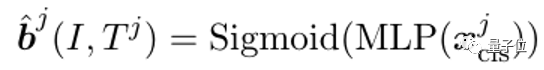

_x_jcls是跨模态编码器在 [CLS] 位置的输出向量。Sigmoid 函数是为了标准化预测的边界框。Ground-truth _b_j对应了 ,依次是标准化后的的中心横坐标、中心纵坐标、宽、高。最后,该损失是边界框坐标的回归损失(L1)和交并比损失(GIoU)之和。作者认为在同一张图片中,给不同文字,要求模型预测出对应的视觉概念,能使模型更有效地学习到多粒度的视觉语言对齐。该损失也是首次被使用在多模态预训练中。
第二,使用patch embeddings来灵活表示各种粒度的视觉概念,然后直接优化模型去拉齐不同粒度的文本和视觉概念,包括了物体/区域/图片与文本的对齐。作者使用多模态预训练中常见的三个损失优化,依次是:
1)对比学习损失:
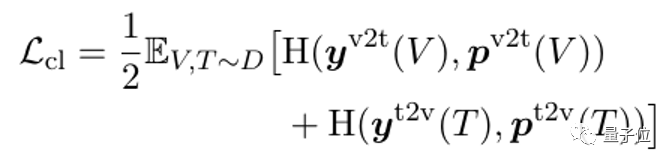
_y_v2t,_y_t2v ∈ Rbsz x _bsz_是ground-truth相似度, 对角线为1,其余为0。
_p_v2t, _p_t2v ∈ Rbsz x _bsz_是模型基于文字编码器输出和图像编码器输出所计算的相似度。
2)匹配损失:
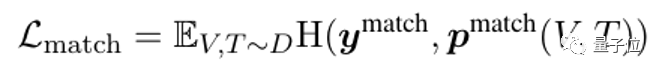
_p_match是基于跨模态编码器计算,预测所给 对是否匹配(换句话说,0/1分类)。对于每对正例,作者采样一对负例。
3)Masked Language Modeling损失:
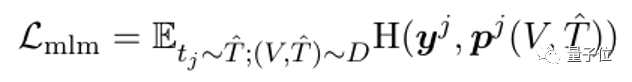
T(估计值)中的一些词已经被随机替换成了 [MASK],_p_j(V, T(估计值))是跨模态编码器在词_t_j位置的输出向量所计算的词表概率分布。
实验
作者使用多模态预训练中常见的中等规模的4M和16M图片数据集进行实验,如下表所示:
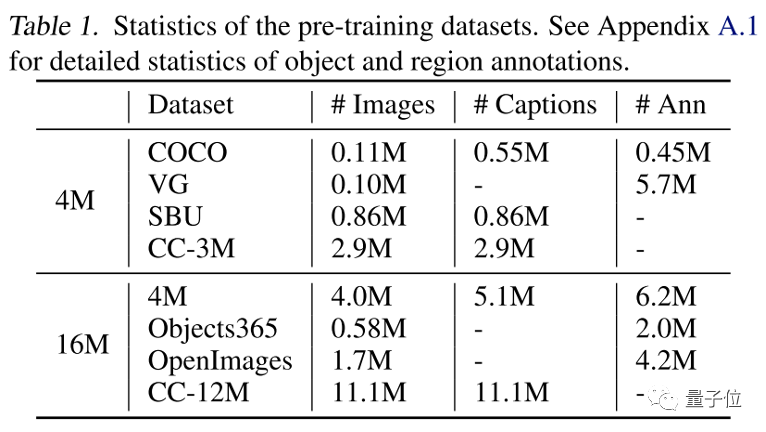
其中,标注(# Ann)是区域标注和物体标签的总和。可以看出,有些数据集没有图片标题,例如Visual Genome(VG),有些数据集没有图片标注,例如CC-3M/12M。
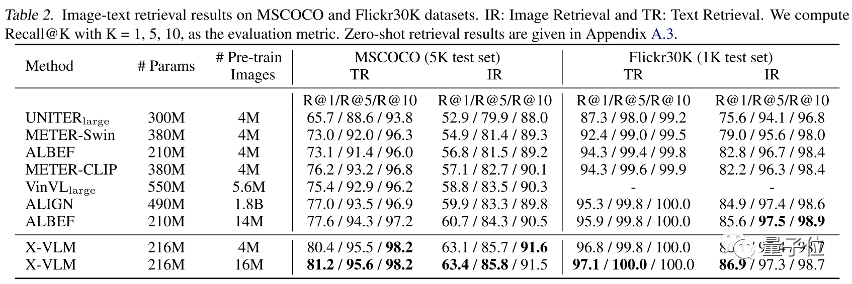
表2展示了在图像文本检索任务 (MSCOCO和Flickr30K) 上的表现。即使,之前的方法在更大量的内部数据上预训练或者模型规模更大,在4M图片数据集下训练的X-VLM就已经可以超过之前的方法。
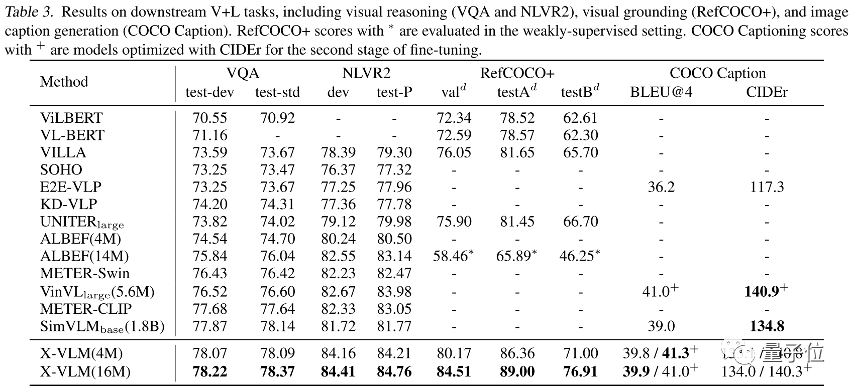
表3展示了在视觉推理 (VQA2.0和NLVR2)、视觉定位 (RefCOCO+) 、图片描述生成 (COCO Caption) 上的模型表现。为了公平的对比,X-VLM 沿用了之前工作的 fine-tune 方法,没有进行额外的调整。结合表2和表3,可以看出,相比之前的方法,X-VLM支持更多种类的下游任务,并且在这些常见的视觉语言任务上都取得了十分优秀的表现。
如何学习AI大模型? 零基础入门到精通,收藏这一篇就够了
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









