






一个户外论坛的特点:
列出一些活动,有翻页功能,点向一个活动显示当前活动信息,在二楼一般显示报名名单!
需要的数据:
就是活动的信息,报名的名单,价钱,主题,url
数据库:
旅游表与报名表
选择Spider:
我选择了CrawlSpider,这个特点:提供一个跟随链接的一个规则!
rules = (
Rule(LinkExtractor(allow=('forum\.php\?mod=forumdisplay\&fid=2\&page=\d+', ))),
Rule(LinkExtractor(restrict_xpaths='//tr/th[@class="common"]/a[starts-with(@href,"http")]'), callback='parse_item'),
)
提取数据的xpath:
'//div[@id="postlist"]/div[2]//div[@align="left"]/text()','//div[@id="postlist"]/div[2]//strong/text()']实例地址:
https://github.com/heavyzero/example/tree/master/uutravel
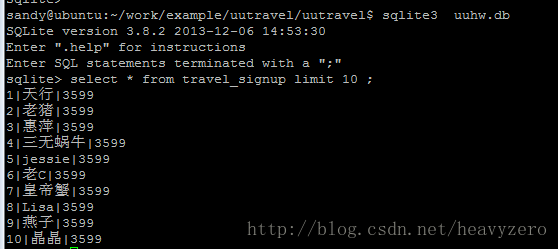
结果:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









