






 阿里云的Qwen-VL模型升级版Qwen-VL-Max在中文理解和生成上超越GPT-4V和Gemini,特别是在图像识别和推理方面有显著提升,支持高像素图像处理,且已被集成到ComfyUI中。
阿里云的Qwen-VL模型升级版Qwen-VL-Max在中文理解和生成上超越GPT-4V和Gemini,特别是在图像识别和推理方面有显著提升,支持高像素图像处理,且已被集成到ComfyUI中。

Qwen-VL-Plus显著提升了细节和文本识别能力,支持超高像素分辨率图像,性能卓越。而Qwen-VL-Max更进一步,拥有高级视觉感知和认知理解,在复杂任务中表现最优。厉害的是,这两款技术还能识别Gif图。这在业界尚属首例,突显其实用性。
其实就是通义千问,Qwen-VL是一种大规模视觉语言模型,由阿里云于2024年1月26日推出。该模型的升级版Qwen-VL-Max拥有更强的视觉推理能力和中文理解能力,能够在多个权威测评中获得佳绩,整体性能堪比GPT-4V和Gemini Ultra。
通义千问国内官网链接:通义官网
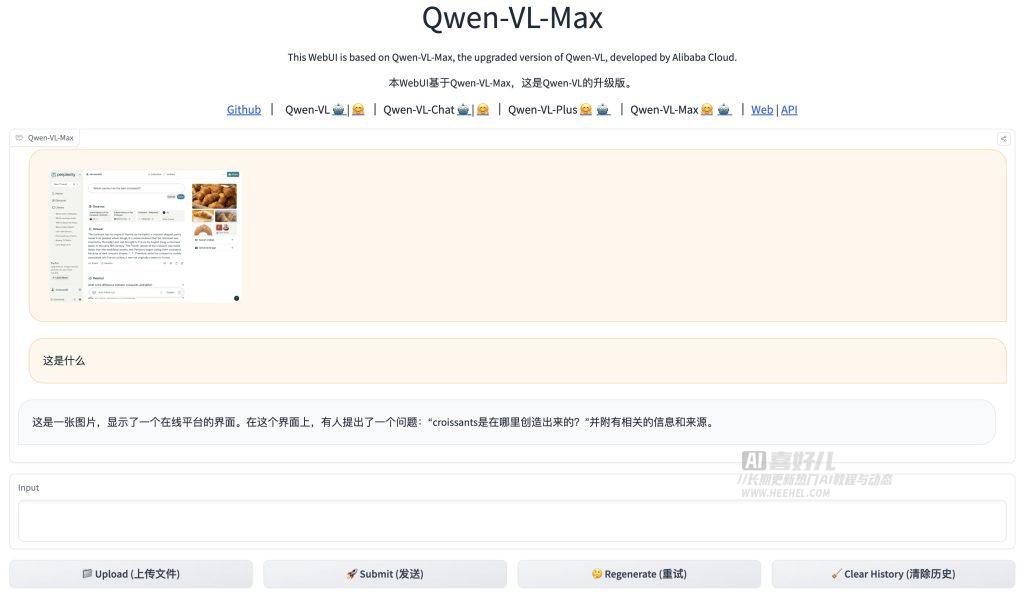
Qwen-VL-Max在中文问答和中文文本理解任务上超越了GPT-4V和Gemini。除此之外,Qwen-VL-Plus在图像相关推理能力上实现了大幅提升,能够在更短的时间内提供更准确的推理结果。同时,Qwen-VL-Plus/Max在识别、提取和分析图像及其中文本细节上的能力显著增强,能够更好地理解和处理复杂的视觉信息。该模型还支持超过一百万像素的高清图像和各种宽高比的图像的处理,满足了不同应用场景的需求。
详细介绍:Introducing Qwen-VL | Qwen
在线体验:https://huggingface.co/spaces/Qwen/Qwen-VL-Max
项目地址:https://github.com/ZHO-ZHO-ZHO/ComfyUI-Qwen-VL-API
AIGC专区:aigc

阿里巴巴Qwen-VL的特殊能力:
- 在多个文本-图像多模态任务上,Qwen-VL-Plus与Gemini Ultra和GPT-4V性能相当,均表现出色。
- Qwen-VL-Max在中文问答和中文文本理解任务上超越了GPT-4V和Gemini,展现了更强大的语言理解和生成能力。
- Qwen-VL-Plus/Max在图像相关推理能力上实现了大幅提升,能够在更短的时间内提供更准确的推理结果。
- Qwen-VL-Plus/Max在识别、提取和分析图像及其中文本细节上的能力显著增强,能够更好地理解和处理复杂的视觉信息。
- Qwen-VL-Plus/Max支持超过一百万像素的高清图像和各种宽高比的图像的处理,满足了不同应用场景的需求。
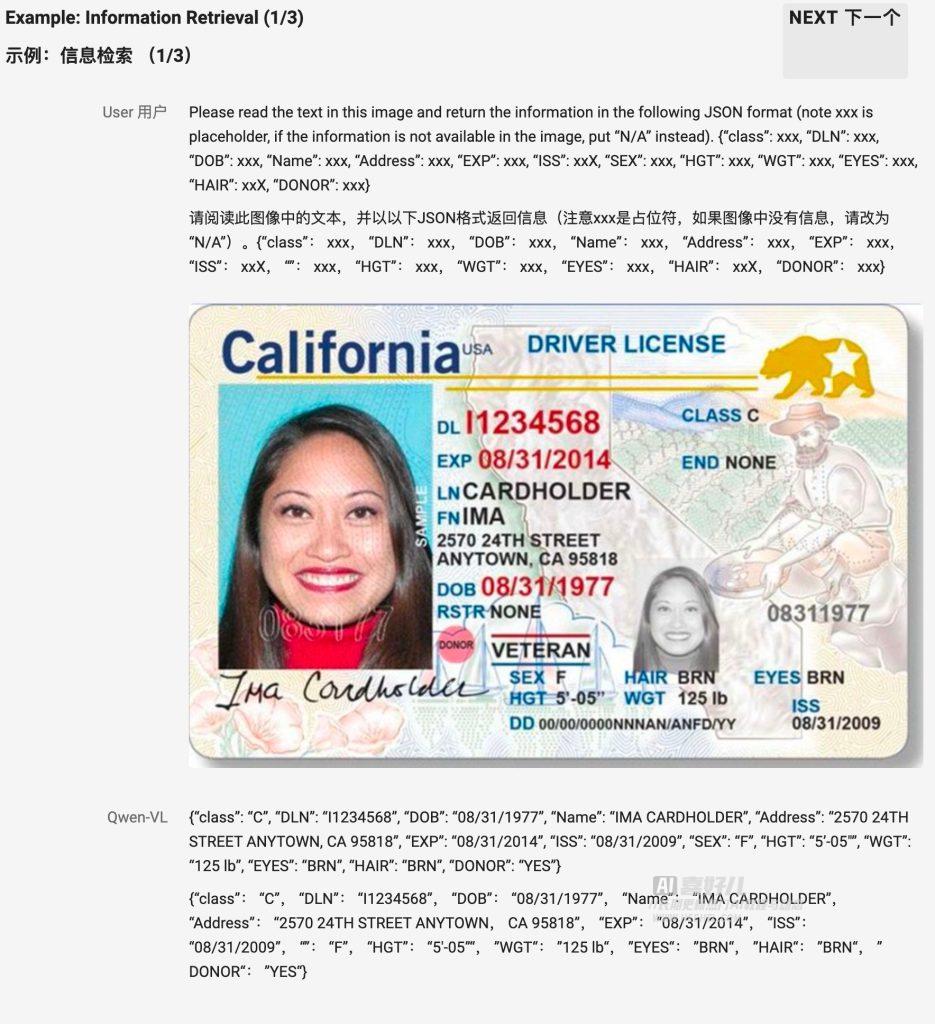
然鹅,这个Qwen-VL已经被网友-Zho-集成到了ComfyUI里面去了,想要的小伙伴点下面的链接下载吧。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









