







modelarts是华为云推出的AI服务,目前支持的场景还挺多,图片、人脸、文本等很多场景,详细的大家可以去学习华为云的文档。
本文以文本分类场景为例,以此说明如何创建属于自己的AI服务。由于华为云的文档写的还不错,如果是初学者,建议按照华为云文档的步骤去做。
不过,由于华为云的文档更新往往跟不上架构更新,所有有些时候,看似简单的部署,反而会碰到坑。所以本文的重点是告诉大家可能碰到的坑,以及如何去踩。
区域选择
区域必须是北京4,否则到后面的步骤是要收费的。之前区域北京1也有免费的,但隔了一周,就没有免费的了。因为这个原因,搞得发了工单,还重复了两遍劳动,好在华为云的客服还不错。这一点也是华为云最大的毛病,常常是免费用着用着,突然就收费了,也不打个招呼。
创建OBS
由于需要的数据集是存放在OBS中的,所以一定要先在北京4创建OBS,否则后面的步骤都无法执行。
准备数据
由于是文本分类的场景,所以一开始要创建数据集,要把数据集的输入和输出路径确定好,点击浏览,就会跳出刚才创建的OBS,如图:
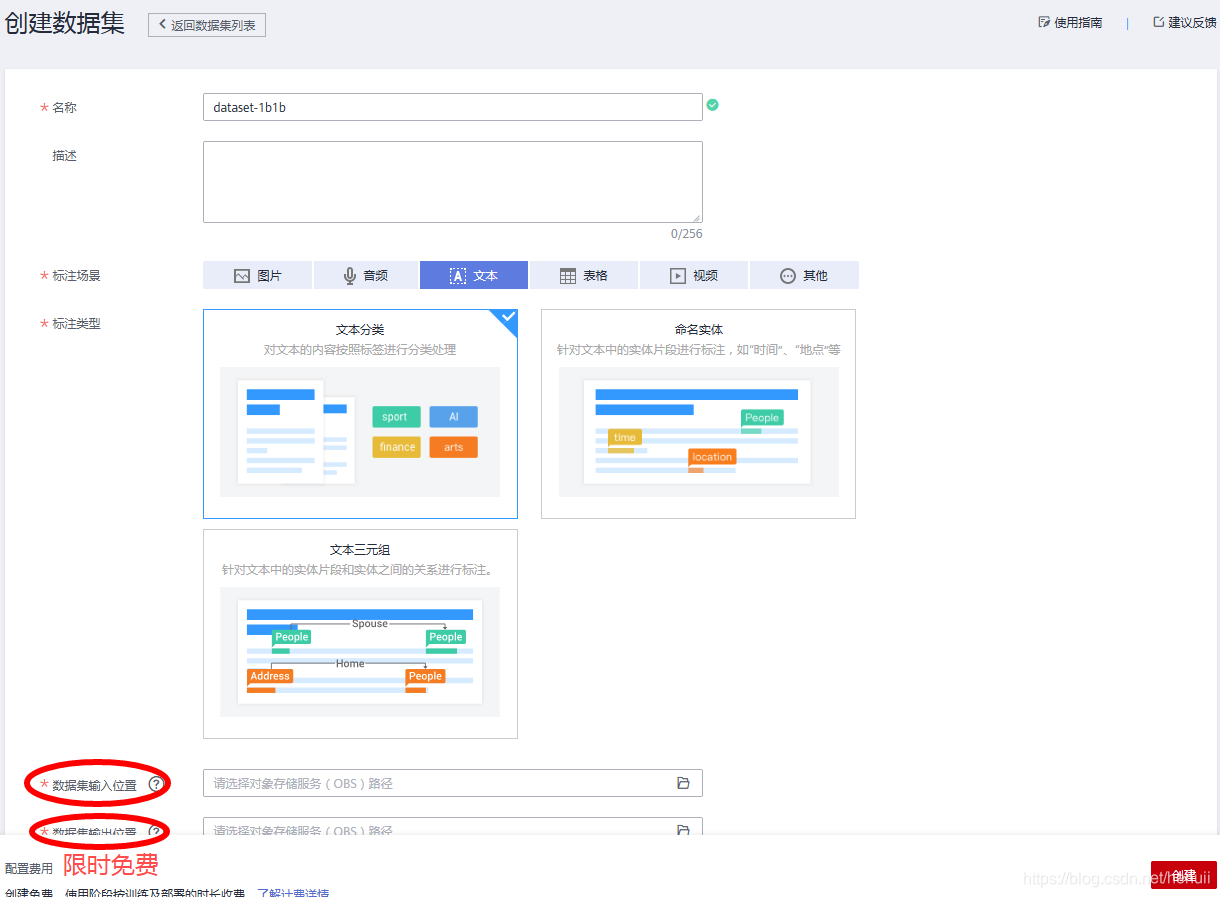
准备两个文件即可,都使用txt格式保存。一个文件放需要分类的文本,没有特别的讲究,只要一行一行的即可,文件名如***_20201026.txt。
另外一个文件,需要放分类标签,是有很多讲究的。
- 每行不能超过32个字符;
- 不能包含空格、标点等符号,只能是数字、字母、汉字等;
- 行数一定要与前面的文件一一对应,否则无法自动标注;
- 文件名要命名为***_20201026_result.txt
- 每个标签在第一个文件中,至少要有20个以上的行对应,也就是说,每个标签的样本数要超过20个,否则后面的自动学习步骤无法执行。这一点,华为云也是修改过的,之前是样本数要超过8个,结果不吭不哈的就改成了20个,耽误了很长时间修改原有的数据。
数据标注
如果前面这个步骤做的好,那么数据标注就会很轻松,如下图:
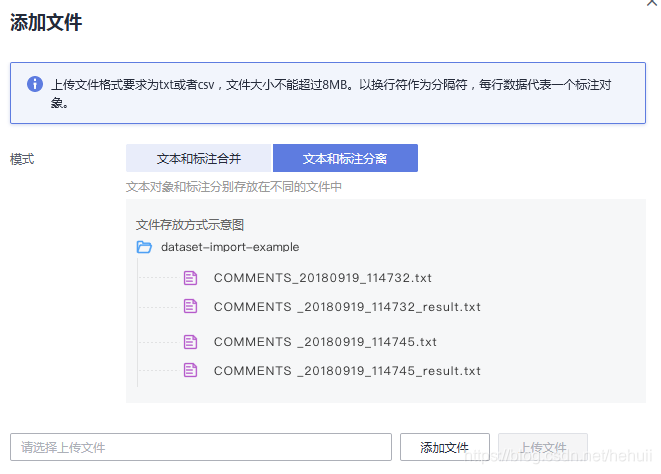
但是如果前面这个步骤没有做好,那么就悲剧了,手工标准很麻烦,而且删除未标注的数据和已标准的数据都很麻烦,搞到最后只能用键盘精灵来帮忙了。
创建项目
当前面的数据全部能够自动标注,到这一步,就要大功告成了。如下图:
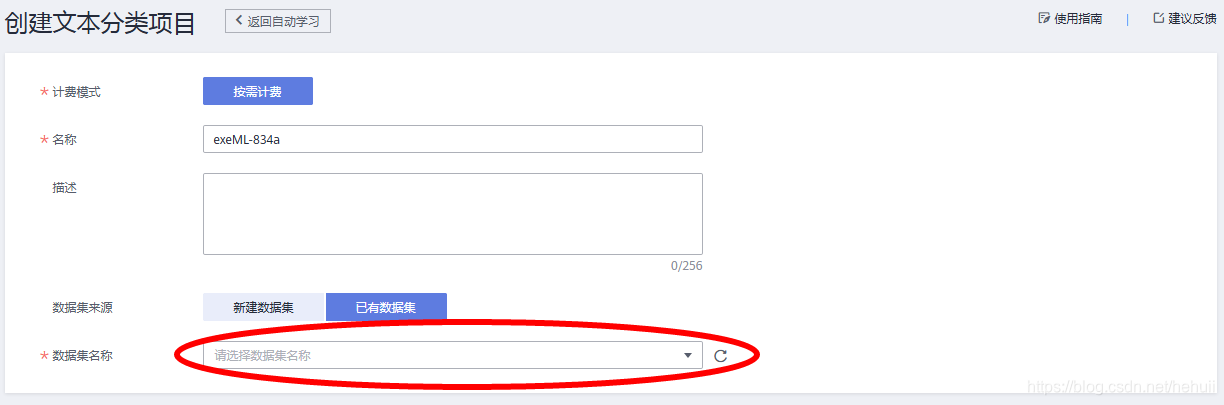
创建一个文本分类的项目,数据集就选择刚才创建的那个数据集即可。这里其实也可以新建数据集,由于我是先创建了数据集,所以直接选择就可以了。
自动学习
到了这一步,基本就是交给华为云处理了。在这个界面里,你可以看到之前创建的项目,只要点击以后,开始训练即可,这里的坑之前已经说过了,首先,必须要在北京4,其他区不能免费训练。其次,每个标签20个以上的样本,否则训练的按钮是灰色的。
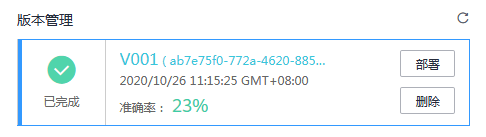
部署
这是最后一步了,当你的训练完成以后,会在版本管理出现下图,然后点击以后就可以部署了,目前只有北京4提供免费一个小时的部署,部署完毕以后,就可以进行测试了。建议就在自动学习的界面里测试,比较方便。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











