







最优化问题—非线性规划(一)
1. 非规划模型的引入和形式描述
1.1 一个非规划的例子
在之前的文章中,我们主要介绍了线性规划模型。其实,在我们建模的过程中,更多的是非规划的问题。我们下面从一个问题进入:
设第
i
i
i个仓库的位置为
(
x
i
,
y
i
)
,
(
i
=
1
,
2
,
,
.
.
.
,
m
)
(x_i,y_i),(i=1,2,,...,m)
(xi,yi),(i=1,2,,...,m),第i个仓库向第j个市场的货物供应量为
z
i
j
z_{ij}
zij(i=1,2,3,…,m,j=1,2,…,n),第i个仓库到第j个市场的距离为:
d
i
j
=
(
x
i
−
p
j
)
2
+
(
y
i
−
q
j
)
2
d_{ij}=\sqrt{(x_i-p_j)^2+(y_i-q_j)^2}
dij=(xi−pj)2+(yi−qj)2
这里,我们的目标是最小化距离和货物供应量的乘积的结果,这里我们用公式来描述就是:
∑
i
=
1
m
∑
j
=
1
m
z
i
j
d
i
j
=
∑
i
=
1
m
∑
j
=
1
m
z
i
j
(
x
i
−
p
j
)
2
+
(
y
i
−
q
j
)
2
∑_{i=1}^m∑_{j=1}^mz_{ij}d_{ij}=∑_{i=1}^m∑_{j=1}^mz_{ij}\sqrt{(x_i-p_j)^2+(y_i-q_j)^2}
i=1∑mj=1∑mzijdij=i=1∑mj=1∑mzij(xi−pj)2+(yi−qj)2
同时,在有了目标函数之后,我们需要进一步的去观察其约束条件:
- 每一个仓库向各个市场的货物供应量之和不能超过该仓库的存储容量。
- 每个市场从各个仓库得到的货物量之后需要等于其基本的需要量。
- 供应的数量不能为负数。
最后,我们对上面的的问题进行建模,得到的数学模型为:

根据上面的例子,相信各位读者能够看出非规划和线性规划在形式上的不同,其最大的不同的就是目标函数的形式不同。
1.2 非规划问题的一般形式
通常而言,一般的非线性规划的数学表达如下形式所示:

这里的 x = ( x 1 , x 2 , , . . . x n ) T ∈ R n x=(x_1,x_2,,...x_n)^T∈R^n x=(x1,x2,,...xn)T∈Rn, f , g i , h j f,g_i,h_j f,gi,hj都是 R n − > R 1 R^n->R^1 Rn−>R1的映射函数,也就是说在非线性规划中,我们的输入是一个向量的形式,通过目标函数和约束函数的形式,我们最终是要将输入的向量映射成一个最终的标量。
1.3 几个常见的概念
- 可行域: 与线性规划类似的是,我们将满足约束条件的解称为可行解。对于可行解锁组成的集合,我们用 N = { x ∣ g i ( x ) ≥ 0 , i = 1 , 2 , . . . , m , h j ( x ) = 0 , j = 1 , 2 , 3 , . . . , n } N=\{x|g_i(x)≥0,i=1,2,...,m,h_j(x)=0,j=1,2,3,...,n\} N={x∣gi(x)≥0,i=1,2,...,m,hj(x)=0,j=1,2,3,...,n}来进行表示,将这个集合称为可行域。
- 如果 N = R n N=R^n N=Rn,我将这个整个问题称为无约束优化问题,此时对于原始问题的建模可以描述为 m i n f ( x ) , x ∈ R n minf(x),x∈R^n minf(x),x∈Rn。
- 局部最优解:与线性规划不同的是,在非线性规划问题中,我们通常获得的最优解是“局部的”,这种局部性指的是在一段区域内是最小的,但是对于整个可行域而言,其不一定是整个可行域的“最优解”。用数学具体的定义就是: x ∗ x^* x∗是局部最优解,是指存在可行域中以 x ∗ x^* x∗为中心的邻域 P ( x ∗ , δ ) P(x^*,δ) P(x∗,δ),使得 任 意 属 于 邻 域 P 和 可 行 域 N 交 集 的 点 x , 都 有 f ( x ∗ ) ≤ f ( x ) , δ > 0 任意属于邻域P和可行域N交集的点x,都有f(x^*)≤f(x),δ>0 任意属于邻域P和可行域N交集的点x,都有f(x∗)≤f(x),δ>0。如果 f ( x ∗ ) < f ( x ) f(x^*)<f(x) f(x∗)<f(x),则称为严格局部最优解,如果 任 意 的 x ∈ N , 都 有 f ( x ∗ ) ≤ f ( x ) 任意的x∈N,都有f(x^*)≤f(x) 任意的x∈N,都有f(x∗)≤f(x),则称为全局最优解。
1.4 几种非线性规划的形式
对于一般的线性规划问题,有以下几种常见的描述形式:

1.5. 非线性规划的直观理解
为了能够进一步的去了解非线性规划的形式,我们从一个问题开始:
m i n f ( x 1 , x 2 ) = ( x 1 − x 2 ) 2 + ( x 2 − 2 ) 2 , s . t . x 1 + x 2 − 2 ≤ 0 minf(x_1,x_2)=(x_1-x_2)^2+(x_2-2)^2,s.t.x_1+x_2-2≤0 minf(x1,x2)=(x1−x2)2+(x2−2)2,s.t.x1+x2−2≤0
首先,对于目标函数而言,其可以在空间中形成一个二维的曲面,对于约束条件而言,其能够在空间中形成一个平面,根据目标函数和约束条件可知,我们的目标就是获取到平面和曲面节点的中使得目标函数最小的值。下面使用图来表示:

上图中表示空间目标函数和约束条件的两个平面,右侧的图是将两个平面进行抽象成一个二维的形式,将平面抽象成等值线的形式,我们可以看到,我们要求的就是两个等值线的相交处的小结果。
2 无约束问题的最优性条件
在了解的非线性规划的基本形式之后,我们下一个需要进行探索的问题就是如何保证我们的非线性规划问题是具有最优解的?如何保证我们获得解释最优的?,针对这两个问题,我们给出一些相关的最优性条件。
2.1 梯度角度
2.1.1 梯度知识回顾
在非线性规划问题,最为常见的求解思想和最优解的证明就是从梯度的角度来看待整个问题。对于一个常见的多元函数 f ( x ) f(x) f(x)而言,存在以下一个基本关系:
- 函数 f ( x ) f(x) f(x)在点 x 0 x_0 x0出可微,那么在该点的梯度也就存在,并且存在等式 d f ( x 0 ) = ▽ f ( x 0 ) T △ x df(x_0)=▽f(x_0)^T△x df(x0)=▽f(x0)T△x,这个等式的含义就不细说了,有兴趣的读者可以参考高等数学中对于梯度的描述。
- 如果
u
=
f
(
x
)
u=f(x)
u=f(x)是二元的函数,则f在
x
0
x_0
x0处的梯度的几何意义是:
▽
f
(
x
0
)
▽f(x_0)
▽f(x0)是过
x
0
x_0
x0点的
f
(
x
)
f(x)
f(x)等值线在
x
0
x_0
x0出的法向量。具体如下图所示:

- 如果 u = f ( x ) u=f(x) u=f(x)是三元的函数,则f在点 x 0 x_0 x0处的梯度的几何意义是: ▽ f ( x 0 ) ▽f(x_0) ▽f(x0)是过 x 0 x_0 x0点的 f ( x ) f(x) f(x)等值面在 x 0 x_0 x0出的法向量。具体如下图所示:

- 梯度方向描述的是函数沿着点x最快的上升方向,则负梯度方向描述的是最快的下降方向。
同样,以上的这些关系在高等数学中都有具体的介绍和讲解,这里我们只是进行简单陈述。
2.1.2 、多元函数的泰勒展开和结果逼近
对于一个常见的函数
f
(
x
)
f(x)
f(x),我们可以给出其二次的泰勒展开式:
f
(
x
0
+
△
x
)
=
f
(
x
0
)
+
d
f
(
x
0
)
+
d
f
′
′
(
x
0
)
2
O
(
∣
∣
△
x
∣
∣
2
)
=
f
(
x
0
)
+
▽
f
(
x
0
)
T
△
x
+
1
2
△
x
T
▽
2
f
(
x
)
)
+
O
(
∣
∣
△
x
∣
∣
2
)
f(x_0+△x)=f(x_0)+df(x_0)+\frac{df''(x_0)}{2}O(||△x||^2)=f(x_0)+▽f(x_0)^T△x+\frac{1}{2}△x^T▽^2f(x_))+O(||△x||^2)
f(x0+△x)=f(x0)+df(x0)+2df′′(x0)O(∣∣△x∣∣2)=f(x0)+▽f(x0)T△x+21△xT▽2f(x))+O(∣∣△x∣∣2)
根据泰勒展开式,我们可以进行函数的在 x 0 x_0 x0点的结果逼近,其逼近方式如下公式所示:
f
(
x
0
+
△
x
)
≈
f
(
x
0
)
+
▽
f
(
x
0
)
T
△
x
f(x_0+△x)≈f(x_0)+▽f(x_0)^T△x
f(x0+△x)≈f(x0)+▽f(x0)T△x
f
(
x
0
+
△
x
)
≈
f
(
x
0
)
+
▽
f
(
x
0
)
T
△
x
+
1
2
△
x
T
▽
2
f
(
x
)
)
+
O
(
∣
∣
△
x
∣
∣
2
)
f(x_0+△x)≈f(x_0)+▽f(x_0)^T△x+\frac{1}{2}△x^T▽^2f(x_))+O(||△x||^2)
f(x0+△x)≈f(x0)+▽f(x0)T△x+21△xT▽2f(x))+O(∣∣△x∣∣2)
看到这里,读者可能会有一些疑惑,这两个逼近公式的作用在哪里?这里我们稍微的理解一下这两个公式,举一个实际的例子,如果你对机器学习尤其是深度学习有一定的了解,你一定可以知道,我们在对于深度学习获取最优的参数过程中,往往不是一次就可以直接获取到结果,我们需要经过不断的进行迭代,这个迭代的过程就是不断的更新参数w,我们通过最小化误差函数还调节参数w,这个调节的过程就是从当前的w点转移到能够使损失函数进一步减少的点w’。一般来讲,我们在利用梯度求解的过程中,这个转移的过程就是利用上面的逼近公式来实现的。由于很多问题可能不存在二阶导数,所以更多的我们使用的是一阶的逼近。
2.1.3 一阶和二阶条件,定理
在回顾了梯度的基本形式和作用,以及能够理解一阶和二阶逼近之后,我们下面要给出一阶导数和二阶导数最优性的两个必要条件:
-
多元函数 f ( x ) f(x) f(x)在 x ∗ x^* x∗点处可微,在 x ∗ x^* x∗是f(x)的局部极小值点的必要条件是 ▽ f ( x ∗ ) = 0 ▽f(x^*)=0 ▽f(x∗)=0
-
多元函数 f ( x ) f(x) f(x)在 x ∗ x^* x∗点二次可微,在 x ∗ x^* x∗是f(x)的局部极小值点的必要条件是 ▽ f ( x ∗ ) = 0 ▽f(x^*)=0 ▽f(x∗)=0,并且 ▽ 2 f ( x ∗ ) ▽^2f(x^*) ▽2f(x∗)是半正定的。
同时,我们给出关于最优性的两个充分条件:
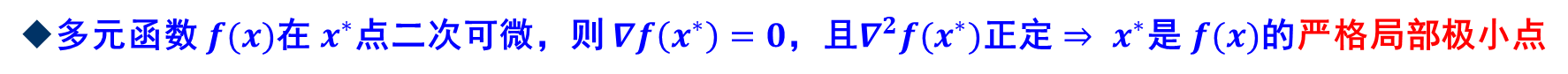

在本节的最后,我们给出一个关于最优性的定理:
定理: 在实值函数 f ( x ) ∈ R 1 , x ∈ R n f(x)∈R^1,x∈R^n f(x)∈R1,x∈Rn,在点 x ∗ x^* x∗处可微,若存在向量 p = x − x ∗ ∈ R n p=x-x^*∈R^n p=x−x∗∈Rn,使得 ▽ f ( x ∗ ) T p < 0 ▽f(x^*)^Tp<0 ▽f(x∗)Tp<0,则存在数δ>0,使得对于每一个 λ ∈ ( 0 , δ ) λ∈(0,δ) λ∈(0,δ),有 f ( x ∗ + λ p ) < f ( x ∗ ) f(x^*+λp)<f(x^*) f(x∗+λp)<f(x∗)
对于这个定理,我们先说其作用,我们还是举上面深度学习的例子,在深度学习中,我们使用的基于梯度的更新公式的基本形式为为 w ′ = w − α ∗ g r a d ( w ) w'=w-α*grad(w) w′=w−α∗grad(w),其中grad表示的是梯度值,我们很容易就可以联想到,我们在对于参数点w转移到 w ′ w' w′的时候,我们要保证的就是损失函数在不断的进行降低,也就是 f ( w ) > f ( w + ( − α ∗ g r a d ( w ) ) ) f(w)>f(w+(-α*grad(w))) f(w)>f(w+(−α∗grad(w))),显然,这种转移的成立性可以通过上面的公式来进行说明。
2.1.4 非线性规划的最优性条件
在对上面的描述有了一些了解之后,下面我们来看在非线性规划中的最优性条件。首先,非线性规划问题也需要满足上面的一般性的条件,同时,在非线性规划中还有一个常见的结论:
对 于 正 定 的 二 次 函 数 f ( x ) = 1 2 x T A x + b T x + C , 其 中 A 为 n 阶 的 对 称 矩 阵 对于正定的二次函数f(x)=\frac{1}{2}x^TAx+b^Tx+C,其中A为n阶的对称矩阵 对于正定的二次函数f(x)=21xTAx+bTx+C,其中A为n阶的对称矩阵,有唯一的极小点: x ∗ = − A − 1 b x^*=-A^{-1}b x∗=−A−1b,并且其等值面是通信椭球面组,并且中心为其极小点 x ∗ x^* x∗。
3. 凸约束问题的最优性条件
在上面的两个大的部分中,我们主要介绍的是一般情况下的非线性规划问题和其最优性条件,在上面描述的最优性条件中,我们给出的要么是充分条件,要么是必要条件,也就是说,对于一般的非线性规划问题,其最优性的充要条件是很难找找到的,但是有一类的非线性规划问题的最优性的充要条件是比较好确定的。那就是——凸函数的最优性条件。
3.1 凸函数的最优性充要条件
- 多元函数f定义在非空的开凸集 S ∈ R n S∈R^n S∈Rn上的可微函数,则f为凸函数的充要条件的是 f ( y ) ≥ f ( x ) + ▽ f ( x ) T ( y − x ) , 任 意 x , y ∈ S f(y)≥f(x)+▽f(x)^T(y-x),任意x,y∈S f(y)≥f(x)+▽f(x)T(y−x),任意x,y∈S,如果是>,则为严格凸函数。
- 多元函数f定义在非空的开凸集 S ∈ R n S∈R^n S∈Rn上的可微函数,则f为凸函数的充要条件的是f在S中的每一个点的Hessian矩阵为半正定的矩阵。如果每一个点的Hessian矩阵正定,则为严格凸函数。反之,严格凸函数,只能说明Hessian矩阵的半正定。
- 多元函数f定义在非空的开凸集 S ∈ R n S∈R^n S∈Rn上的凸函数,则 f ( x ) f(x) f(x)的任意一个极小点就是它在S上的全局极小点,而且所有的极小点形成一个凸集。
- 多元函数f定义在非空的凸集 S ∈ R n S∈R^n S∈Rn上的可微凸函数,如果存在点 x ∗ ∈ S x^*∈S x∗∈S,使得对于所有的点x∈S,都有 ▽ f ( x ∗ ) T ( x − x ∗ ) ≥ 0 ▽f(x^*)^T(x-x^*)≥0 ▽f(x∗)T(x−x∗)≥0,则 x ∗ x^* x∗是 f ( x ) f(x) f(x)在凸集S上的全局极小点。
这里我们给出了关于凸函数的判别和最优点结果的充要条件,以及相关点在凸函数中的全局最优性的判别。根据这些条件和结论可知,定义在凸集上的凸函数的极值点对于我们求解最小化的问题有着很好的帮助,其根本原因在于一个目标函数和约束都是凸函数,这种可行域是凸集的规划问题,我们称之为凸规划问题。那么下一步不难想象,我们需要做的就是去判定一个非线性规划问题的可行域是否是凸集。
对于这个问题,我们需要回顾一下凸集的基本形式:
凸集的交集仍然是一个凸集。所以如果所有约束函数的的可行域都是凸集,那么目标函数的可行域也是凸集,那么整问题就变成了凸规划的问题。
4 总结
在上文中,我们重点介绍了关于非线性规划的一般形式,非线性规划的一般最优条件,由于一般的非线性规划的问题都不是充要条件,进一步,我们描述了定义在凸集上的凸函数的最优性条件。
5 参考
- 哈工大—组合优化与凸优化

















 1637
1637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









