









大数据笔记之MapReduce的底层原理
Map段工作逻辑:
两个线程:
第一个线程:
使用RecordReader读取文件。
使用用户自定义的map对数据进行处理,然后写入环形缓冲区。
第二个线程: 检查环形缓冲区的是否填满(80%)
(1)如果填满,先上锁阻塞线程一,再开始执行溢出逻辑 ->
溢出逻辑为:
1.先对缓冲区中的数据(数组)按照 分区号和key(分区号对应的key的逻辑可以自定义) 进行排序。
2.依次将缓冲区中的kv写出到一个本地磁盘文件中。
3.溢出完成后,清空本次的数据。
4.释放环形缓冲区的锁,将线程一改为就绪状态。
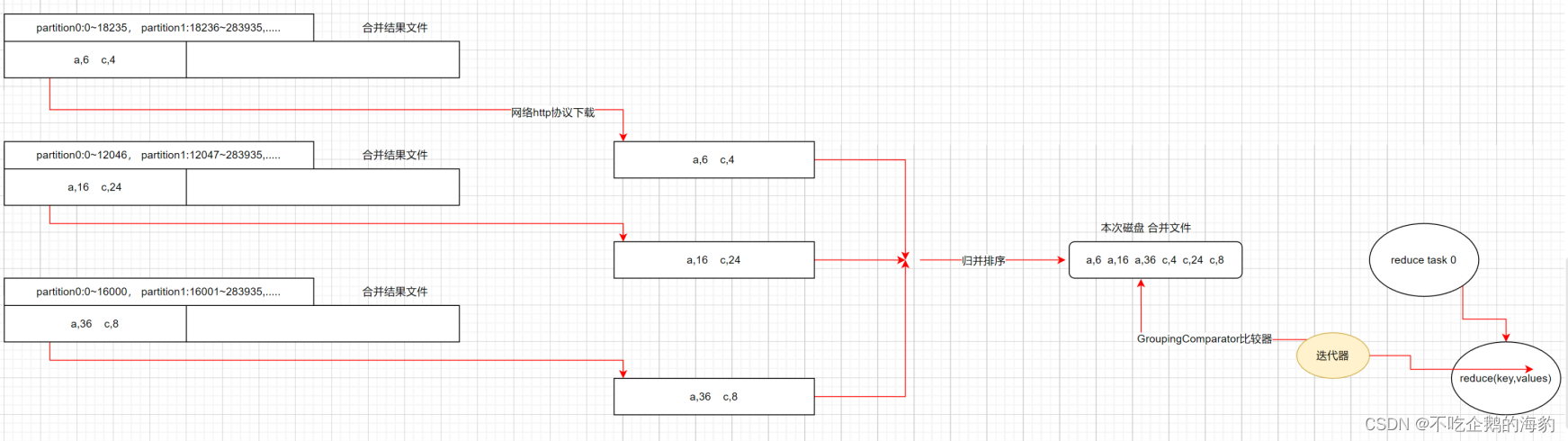
(2)当reader再也读不到数据时,将历次溢出的文件进行合并(合并规则:先读取各个文件的partition0数据,使用归并排序,写入合并文件的最前面,再读取partition0--------略)

补充知识 :
***每个写入硬盘的文件都会带一个索引文件。这个索引文件里面保存着每个分区在partition(n)中的位置.
***环形缓冲区在溢写数据的时候,其中可手动添加combine的逻辑。
***当全部文件处理完毕后,最后阶段对所有溢写文件进行结合的时候。也会调用这个combine的逻辑,对相应的分区所对应的数据进行结合。
Reduce工作逻辑:
Reduce端的机器会去各个不同map端的机器上去下载map端处理好的临时文件。所有文件下载好后,会有一个小聚合,将所有文件进行合并。这个时候,如果有自定义的combine的逻辑,会按照自定义的逻辑对局部数据进行一个小聚合。然后使用归并排序生成一个文件(存于本地磁盘的文件)。
这个文件之后的操作:
注意,这个文件的key都是有序的。
ReduceTask会先生成一个迭代器,这个迭代器的hasnext()方法判断逻辑是:
GroupingComparator比较器(可以先理解为:当前行的key和下一行的key是否相同)。
备注:这个比较器的作用是拆分不同迭代器的,可以自己定义区分逻辑。。。
这个迭代器的next()会将当前行的数据返回。
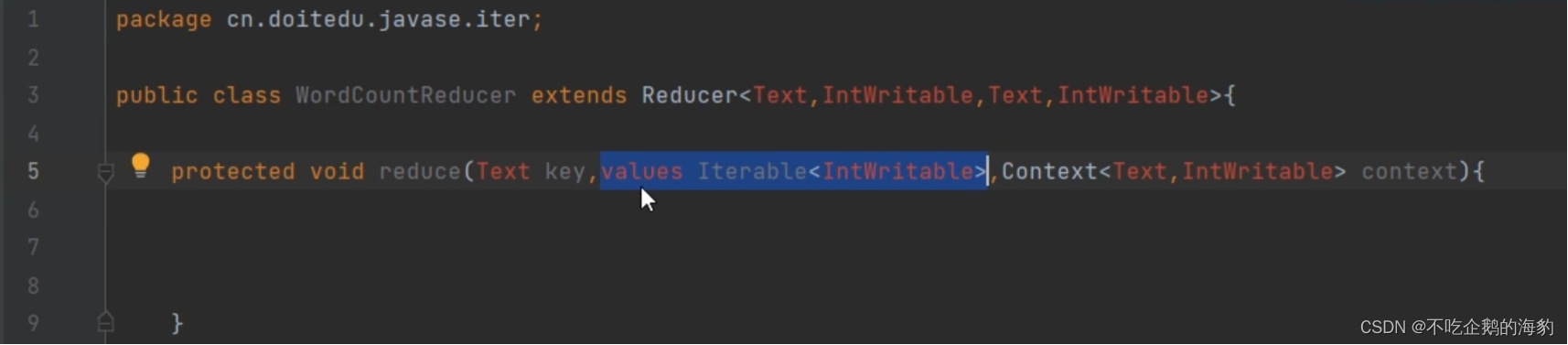
ReduceTask会先调用自定义的reduce()方法。方法中自动传递一个迭代器。同一个key的数据生成一个迭代器。ReduceTask每次调用一个迭代器,直到所有的key对应的迭代器全部被调用完毕。
Reduce()方法里当同一个key的迭代器调用结束后,随之reduce()方法就会结束。
迭代器总结:也就是说,在一个reduceTask上,不同key的数据生成不同的迭代器,然后按照顺序依次调用reduce()方法,每个reduce方法对应一个key的迭代器,直到所有key的迭代器全部被调用完。














 439
439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









