







🌟 一句话定义
孤立森林是一位"异常猎人",通过构建随机分割的森林,让异常值如同雪地中的黑点般快速暴露——正常数据需要复杂的迷宫才能困住,而异常点只需几步就会被隔离到孤岛。
🌲 核心思想图解
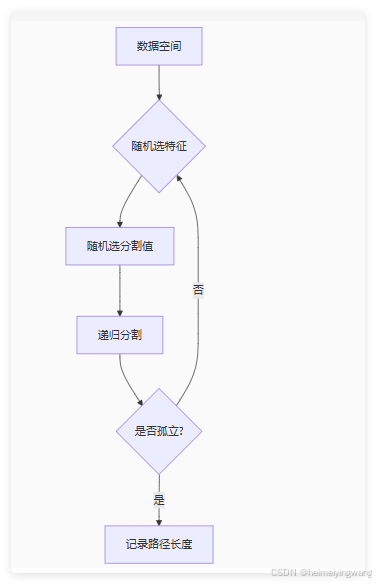
异常值因特征值极端,往往在树结构的浅层就被隔离
⚡ Java示例(简化版实现)
import java.util.*;
class IsolationTree {
static class Node {
int splitFeature;
double splitValue;
Node left, right;
}
// 递归构建孤立树
Node buildTree(double[][] data, int depth, int maxDepth) {
if (data.length == 0 || depth >= maxDepth)
return null;
Node node = new Node();
int feature = new Random().nextInt(data[0].length);
double min = Arrays.stream(data).mapToDouble(d -> d[feature]).min().getAsDouble();
double max = Arrays.stream(data).mapToDouble(d -> d[feature]).max().getAsDouble();
node.splitFeature = feature;
node.splitValue = min + (max - min) * new Random().nextDouble();
// 分割数据集
List<double[]> left = new ArrayList<>();
List<double[]> right = new ArrayList<>();
for (double[] d : data) {
if (d[feature] < node.splitValue) left.add(d);
else right.add(d);
}
node.left = buildTree(left.toArray(new double[0][]), depth+1, maxDepth);
node.right = buildTree(right.toArray(new double[0][]), depth+1, maxDepth);
return node;
}
// 计算路径长度
int pathLength(double[] sample, Node node, int depth) {
if (node == null || node.left == null) return depth;
if (sample[node.splitFeature] < node.splitValue)
return pathLength(sample, node.left, depth+1);
else
return pathLength(sample, node.right, depth+1);
}
}
public class IsolationForest {
List<IsolationTree> trees = new ArrayList<>();
public void fit(double[][] data, int numTrees, int maxDepth) {
for (int i=0; i<numTrees; i++) {
IsolationTree tree = new IsolationTree();
tree.buildTree(data, 0, maxDepth);
trees.add(tree);
}
}
public double anomalyScore(double[] sample) {
double avgPath = trees.stream()
.mapToInt(t -> t.pathLength(sample, t.root, 0))
.average().orElse(0);
return Math.pow(2, -avgPath / c(data.length)); // c(n)为标准化函数
}
public static void main(String[] args) {
double[][] data = loadSensorData(); // 加载工业传感器数据
IsolationForest forest = new IsolationForest();
forest.fit(data, 100, 15); // 100棵树,最大深度15
double[] testSample = {23.5, 150.0, 0.98};
System.out.println("异常得分:" + forest.anomalyScore(testSample));
}
}⏱️ 复杂度分析
| 维度 | 训练阶段 | 预测阶段 |
|---|---|---|
| 时间复杂度 | O(t·ψ·n) | O(t·logψ) |
| 空间复杂度 | O(t·n) | O(t·logψ) |
*ψ=单棵树样本数(默认256),t=树数量,n=总样本数*
🎯 典型应用场景
-
金融风控:信用卡异常交易实时检测
-
工业质检:生产线传感器异常模式捕捉
-
网络安全:识别DDoS攻击流量模式
-
医疗诊断:病理检测指标异常值发现
🧑🏫 学习路线指南
新手成长路径:
高手突破方向:
-
增量学习:实现流式数据实时更新
-
混合检测:与LOF等局部检测算法融合
-
联邦检测:分布式环境下的隐私保护异常检测
-
可解释性:开发特征贡献度可视化工具
💡 创新应用思路
-
卫星遥测分析:空间设备异常状态监测
-
自动驾驶:实时识别传感器异常读数
-
量子计算:量子比特异常行为检测
-
元宇宙安全:虚拟世界中的异常行为识别
🚀 性能调优技巧
// 并行化训练
ExecutorService pool = Executors.newFixedThreadPool(8);
trees.parallelStream().forEach(tree ->
tree.buildTree(subSample(data), 0, maxDepth)
);
// 内存优化:稀疏采样
double[][] subSample = Arrays.copyOfRange(data, 0, Math.min(256, data.length));最佳实践:当处理千万级数据时,采用"子采样+并行建树"策略,如同用多组侦察兵分队探查地形。异常分数阈值建议通过历史数据模拟确定,警惕在数据分布剧烈变化时重新校准模型!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









