







Hadoop集群的完整搭建
准备工作
网络环境的配置
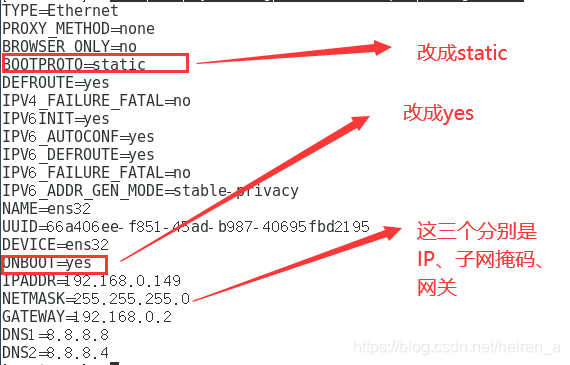
修改网关、IP
- 打开要修改的文件(最后一个文件名可能每个人的不一样):
vi /etc/sysconfig/network-scripts/ifcfg-ens32
配置映射、主机名
- 配置映射:
vi /etc/hosts

- 配置主机名:
vi /etc/sysconfig/network

重启网络服务,测试
- 命令:
service network restart

- 其他俩台也是如此
ssh的配置
-
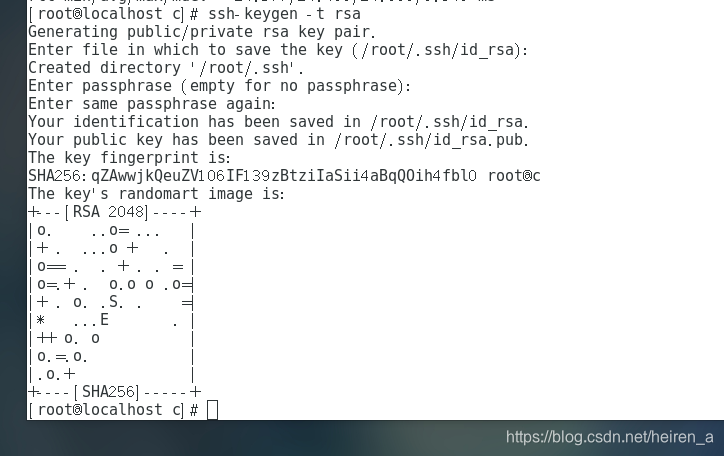
命令:
ssh-keygen -t rsa,连续回车四次 -
-
使用命令将公钥分发到其他的节点上:
ssh-copy-id b -
其他的节点如此
jdk的安装
- 解压压缩文件:
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /home/ - 重命名:
mv jdk1.8.0_161/ jdk - 配置环境变量:
vi /etc/profile
export JAVA_HOME=/home/jdk
export JRE_HOME=${
JAVA_HOME}/jre
export CLASSPATH=.:${
JAVA_HOME}/lib/dt.jar:${
JAVA_HOME}/lib/tools.jar
export PATH=${
JAVA_HOME}/bin:$PATH
- 使环境变量生效:
source /etc/profile - 检测jdk是否安装成功:
java -version

Hadoop完全分布式的安装
准备工作
- 解压缩:
tar -zxvf hadoop-2.7.1_64bit.tar.gz -C /home/ - 重命名:
mv hadoop-2.7.1/ hadoop - 在解压好的hadoop目录下创建几个文件夹
mkdir tmp
mkdir -p hdfs/name
mkdir hdfs/data
修改配置文件
slaves
b
c
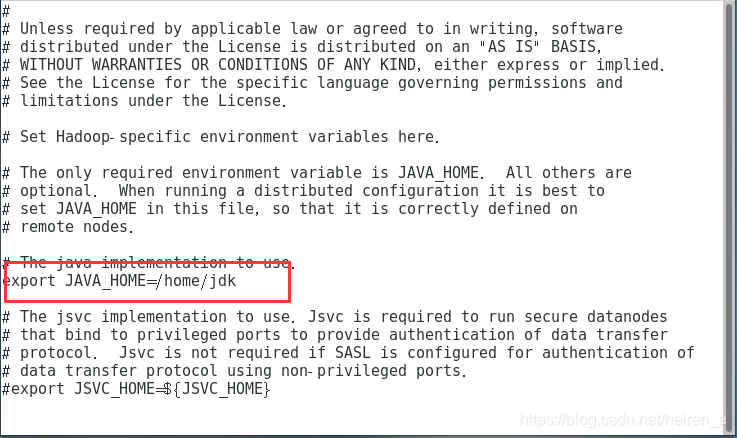
hadoop-env.sh
- jdk的路径
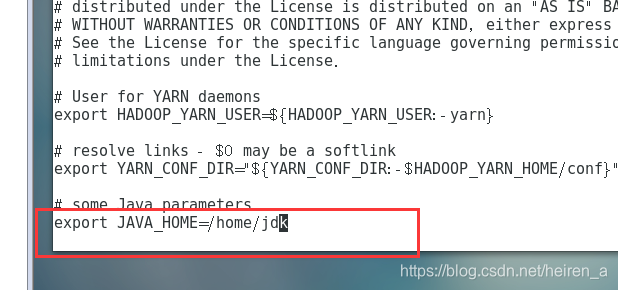
yarn-env.sh
- jdk的路径
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://a:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.name.dir</name>
<value>/home/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>a:50090</value>
</property>
mapred-site.xml
- 如果没有
mapred-site.xml可以将mapred-site.xml.template复制为,mapred-site.xml,命令是:mv mapred-site.xml.template mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>a:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>a:19888 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









