







使用MapReduce实现TF-IDF算法
TF-IDF的介绍
- TFIDF全程叫做term frequency–inverse document frequency,翻译过来可以叫做文本频率与逆文档频率指数, TFIDF就是为了表征一个token(可以是一个字或者一个词)的重要程度
- 应用场景:
1. 权重计算方法经常会和余弦相似度(cosine similarity)一同使用于向量空间模型中,用以判断两份文件之间的相似性。
2. 广告投放,收集用户的朋友圈,或者博客,你会发现,朋友圈给你投放的广告,往往你跟发布的东西有关,例如一个人很喜欢旅游,那我们应该给他投放旅行社,或者风景秀丽的旅游景点。
3. 利用TF-IDF,对数据库的文本进行分词,建立索引后入库,提高用户全文检索的速率。
- TF的概念
TF表示分词在文档中出现的频率,算法是:(该分词在该文档出现的次数)/(该文档分词的总数),这个值越大表示这个词越重要,即权重就越大,TF (例如:一篇文档分词后,总共有500个分词,而分词”Hello”出现的次数是20次,则TF值是: TF =20/500=0.04)。
- IDF的概念
IDF是是一个词语普遍重要性的度量。一个文档库中,一个分词出现在的文档数越少越能和其它文档区别开来。算法是: log(总文档数/(出现该分词的文档数+1)) 。如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词),IDF (例如:一个文档库中总共有10000篇文档, 99篇文档中出现过“Hello”分词,则idf是: IDF = log(10000/(99+1)) =2)
- TF-IDF是什么
TF-IDF就是TF*IDF,TF-IDF与一个词在文档中的出现次数成正比,与整个语料库中包含该词的文档数成反比
- 用途
自动提取关键词,计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。信息检索时,对于每个文档,都可以分别计算一组搜索词(“TF-IDF”、“MapReduce”)的TF-IDF,将它们相加,就可以得到整个文档的TF-IDF。这个值最高的文档就是与搜索词最相关的文档。
- 优缺点
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不 多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的(一种解决方法是,对全文的第一段和 每一段的第一句话,给予较大的权重。)
需求及实现步骤
需求
我们在MySQL中存储了一些豆瓣电影数据(如下图),我们要求对每个电影的评论求TF-IDF,并且将最后的结果存储在MySQL里面

实现步骤
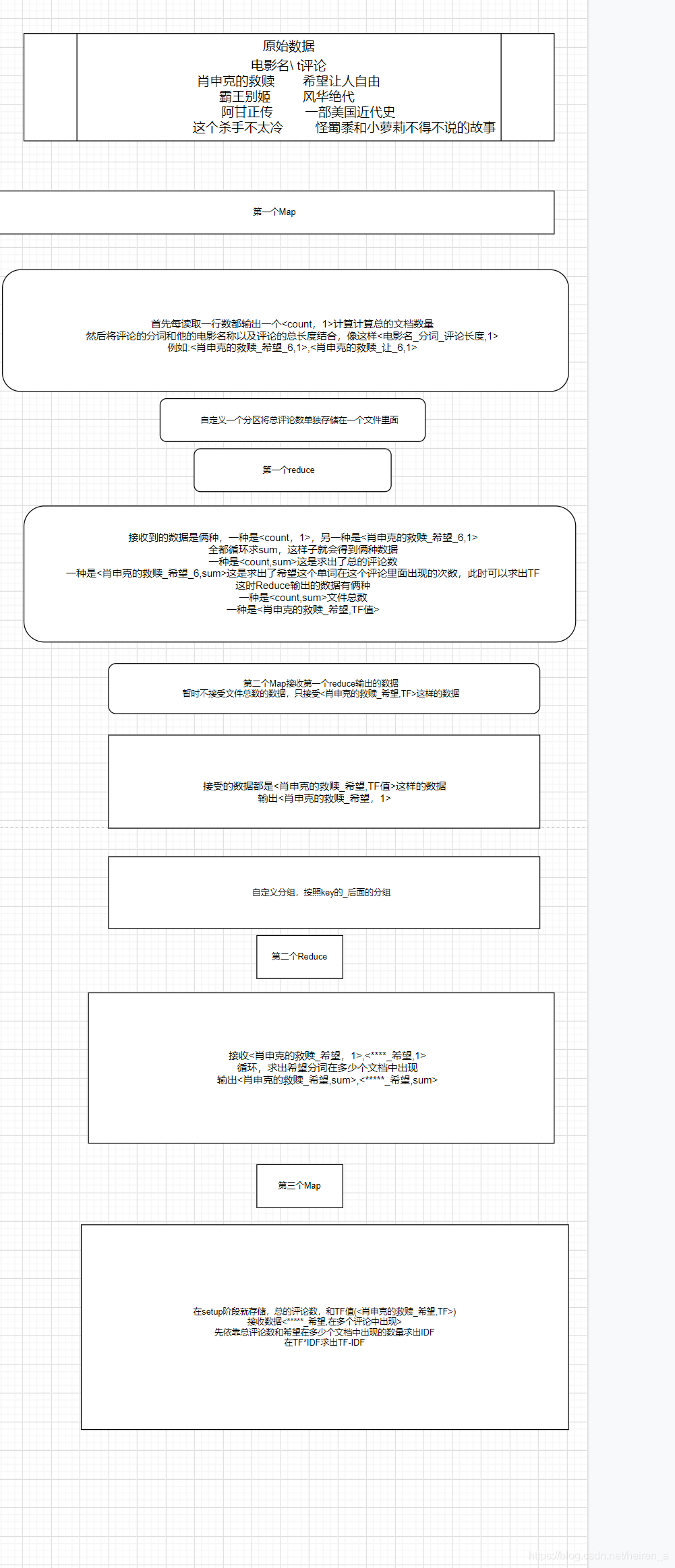
代码实现
设置IK分词及其扩展停止词字典
因为有些词对于我们来说是没有必要的,比如:的、了、吗…,因此我们可以设置不读取这些词
- pom文件
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>
配置暂停词和字典,暂停词也就是忽略词,字典也就是自定义组合词
以下三个文件都在src目录下配置
- IKAnalyzer.cfg.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">test.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典 -->
<entry key="ext_stopwords">teststop.dic;</entry>
</properties>
在ext_stopwords目录下设置忽略的词即可,每个词以回车隔开
自定义类接收MySQL里的数据
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.lib.db.DBWritable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class receiveData implements DBWritable, Writable {
private String FilmName;
private String common;
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(FilmName);
dataOutput.writeUTF(common);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
FilmName = dataInput.readUTF();
common = dataInput.readUTF();
}
@Override
public void write(PreparedStatement statement) throws SQLException {
statement.setString(2, FilmName);
statement.setString(6, common);
}
@Override
public void readFields(ResultSet resultSet) throws SQLException {
FilmName = resultSet.getString(2);
common = resultSet.getString(6);
}
@Override
public String toString() {
return FilmName + "\t" + common;
}
public void set(String filmName, String common) {
FilmName = filmName;
this.common = common;
}
public String getFilmName() {
return FilmName;
}
public void setFilmName(String filmName) {
FilmName = filmName;
}
public String getCommon() {
return common;
}
public void setCommon(String common) {
this.common = common;
}
}
第一个Mapper
IKSegmenter ik = new IKSegmenter(sr, true);将sr读取的进行分词,true是使用扩展的字典
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
import java.io.IOException;
import java.io.StringReader;
/**
* 接收到的数据
* 肖申克的救赎 希望让人自由
* 输出 <count,1> <希望_肖申克的救赎,1>
*/
public class MapTest01 extends Mapper<LongWritable, receiveData, Text, DoubleWritable> {
DoubleWritable v = new DoubleWritable(1);
@Override
protected void map(LongWritable key, receiveData value, Context context) throws IOException, InterruptedException {
String datas[] = value.toString().split("\t");
if ("none".equalsIgnoreCase(datas[1]))return;
StringReader sr = new StringReader(datas[1]);
StringReader sr1 = new StringReader(datas[1]);
//统计每个分词的数量
int count = 0;
IKSegmenter ik1 = new IKSegmenter(sr1, true);
Lexeme l = null;
while ((l = ik1.next()) != null) {
count++;
}
//将评论进行分词
IKSegmenter ik = new IKSegmenter(sr, true);
Lexeme lex = null;
while ((lex = ik.next()) != null) {
//输出k是分词加上电影名,v是1
context.write(new Text(lex.getLexemeText() + "_" + datas[0] + "_" + count), v);
}
context.write(new Text("count"), v);
}
}
自定义分区
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class MyPartition extends Partitioner<Text, DoubleWritable> {
@Override
public int getPartition(Text text, DoubleWritable intWritable, int numPartitions) {
if ("count".equals(text.toString())) {
return 0;
}
return 1;
}
}
第一个Reduce
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* 接受的数据 <count,1> <希望_肖申克的救赎,1>
* 输出 <count,sum> <希望_肖申克的救赎,TF>
*/
public class RedTest01 extends Reducer<Text, DoubleWritable, Text, DoubleWritable> {
Text k = new Text();
DoubleWritable v = new DoubleWritable();
@Override
protected void reduce(Text key, Iterable<DoubleWritable> values, Context context) throws IOException, InterruptedException {
double sum = 0;
//求出总评论数,或者求出一个词在一个评论里的次数
for (DoubleWritable value : values) {
sum += value.get();
}
if ("count".equals(key.toString())) {
v.set(sum);
//输出总评论数
context.write(key, v);
} else {
String[] datas = key.toString().split("_");
double commonLen = Double.parseDouble(datas[2]);
v.set(sum / commonLen);
k.set(datas[1] + "_" + datas[0]);
context.write(k, v);
}
}
}
第二个Mapper
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 接收<肖申克的救赎_希望,TF>
* 输出<肖申克的救赎_希望,1>
*/
public class MapTest02 extends Mapper<LongWritable, Text, Text, IntWritable> {
IntWritable v = new IntWritable(1);
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] datas = value.toString().split("\t");
k.set(datas[0]);
context.write(k, v);
}
}
自定义分组
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class MyGroup extends WritableComparator {
@Override
public int compare(WritableComparable a, WritableComparable b) {
Text t1 = (Text) a;
Text t2 = (Text) b;
return t1.toString().split("_")[1].compareTo(t2.toString().split("_")[1]);
}
public MyGroup(){
super(Text.class,true);
}
}
第二个Reduce
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class RedTest02 extends Reducer<Text, IntWritable, Text, IntWritable> {
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
v.set(sum);
context.write(key, v);
}
}
自定义类接收存储到MySQL的数据
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.lib.db.DBWritable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class ResultData implements DBWritable, Writable {
private String FilmName;
private String word;
private double TF;
private double IDF;
private double TF_IDF;
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(FilmName);
dataOutput.writeUTF(word);
dataOutput.writeDouble(TF);
dataOutput.writeDouble(IDF);
dataOutput.writeDouble(TF_IDF);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
FilmName = dataInput.readUTF();
word = dataInput.readUTF();
TF = dataInput.readDouble();
IDF = dataInput.readDouble();
TF_IDF = dataInput.readDouble();
}
@Override
public void write(PreparedStatement statement) throws SQLException {
statement.setString(1, FilmName);
statement.setString(2, word);
statement.setDouble(3, TF);
statement.setDouble(4, IDF);
statement.setDouble(5, TF_IDF);
}
@Override
public void readFields(ResultSet resultSet) throws SQLException {
FilmName = resultSet.getString(1);
word = resultSet.getString(2);
TF = resultSet.getDouble(3);
IDF = resultSet.getDouble(4);
TF_IDF = resultSet.getDouble(5);
}
public void set(String filmName, String word, double TF, double IDF, double TF_IDF) {
FilmName = filmName;
this.word = word;
this.TF = TF;
this.IDF = IDF;
this.TF_IDF = TF_IDF;
}
public String getFilmName() {
return FilmName;
}
public void setFilmName(String filmName) {
FilmName = filmName;
}
public String getWord() {
return word;
}
public void setWord(String word) {
this.word = word;
}
public double getTF() {
return TF;
}
public void setTF(double TF) {
this.TF = TF;
}
public double getIDF() {
return IDF;
}
public void setIDF(double IDF) {
this.IDF = IDF;
}
public double getTF_IDF() {
return TF_IDF;
}
public void setTF_IDF(double TF_IDF) {
this.TF_IDF = TF_IDF;
}
@Override
public String toString() {
return
FilmName + '\t' + word + '\t' + + TF +'\t' + IDF +'\t' + TF_IDF ;
}
}
第三个Mapper
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.*;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
public class MapTest03 extends Mapper<LongWritable, Text, NullWritable,ResultData> {
ResultData k = new ResultData();
//存储总的评论数
Map<String, Double> countMap = new HashMap<String, Double>();
//存储TF
Map<String, Double> tfcount = new HashMap<String, Double>();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
URI[] uris = context.getCacheFiles();
//总评论数
BufferedReader br1 = new BufferedReader(new InputStreamReader(new FileInputStream(new File(uris[0]))));
String line1 = null;
while ((line1 = br1.readLine()) != null) {
String datas[] = line1.split("\t");
countMap.put(datas[0], Double.parseDouble(datas[1]));
}
BufferedReader br2 = new BufferedReader(new InputStreamReader(new FileInputStream(new File(uris[1]))));
String line2 = null;
while ((line2 = br2.readLine()) != null) {
String datas[] = line2.split("\t");
tfcount.put(datas[0], Double.parseDouble(datas[1]));
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
double idf;
double tf;
String[] datas = value.toString().split("\t");
idf = Math.log10(countMap.get("count") / (Double.parseDouble(datas[1]) + 1));
tf = tfcount.get(datas[0]);
k.set(datas[0].split("_")[0], datas[0].split("_")[1], tf, idf, tf * idf);
context.write( NullWritable.get(),k);
}
}
第三个Reduce
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class RedTest03 extends Reducer< NullWritable,ResultData, ResultData, NullWritable> {
@Override
protected void reduce(NullWritable key, Iterable<ResultData> values, Context context) throws IOException, InterruptedException {
for (ResultData v : values) {
context.write(v, NullWritable.get());
}
}
}
Driver阶段
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBInputFormat;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.log4j.BasicConfigurator;
import java.net.URI;
public class DriTest {
public static void main(String[] args) throws Exception {
BasicConfigurator.configure();
Configuration conf = new Configuration();
DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver", "jdbc:mysql://localhost:3306/data?useUnicode=true&characterEncoding=UTF-8", "root", "123456");
Job job = Job.getInstance(conf);
job.setJarByClass(DriTest.class);
job.setMapperClass(MapTest01.class);
job.setReducerClass(RedTest01.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DoubleWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
job.setPartitionerClass(MyPartition.class);
job.setNumReduceTasks(2);
String[] f1 = {"rank", "name", "actor", "grade", "num", "common"};
DBInputFormat.setInput(job, receiveData.class, "douban", null, null, f1);
FileOutputFormat.setOutputPath(job, new Path("D:\\MP\\TFIDF\\output1"));
boolean b1 = job.waitForCompletion(true);
if (b1) {
Configuration conf2 = new Configuration();
Job job2 = Job.getInstance(conf2);
job2.setJarByClass(DriTest.class);
job2.setMapperClass(MapTest02.class);
job2.setReducerClass(RedTest02.class);
job2.setMapOutputKeyClass(Text.class);
job2.setMapOutputValueClass(IntWritable.class);
job2.setOutputKeyClass(Text.class);
job2.setOutputValueClass(IntWritable.class);
job2.setGroupingComparatorClass(MyGroup.class);
FileInputFormat.setInputPaths(job2, "D:\\MP\\TFIDF\\output1\\part-r-00001");
FileOutputFormat.setOutputPath(job2, new Path("D:\\MP\\TFIDF\\output2"));
boolean b2 = job2.waitForCompletion(true);
if (b2) {
Configuration conf3 = new Configuration();
DBConfiguration.configureDB(conf3, "com.mysql.jdbc.Driver", "jdbc:mysql://localhost:3306/data?useUnicode=true&characterEncoding=UTF-8", "root", "123456");
Job job3 = Job.getInstance(conf3);
job3.setJarByClass(DriTest.class);
job3.setMapperClass(MapTest03.class);
job3.setReducerClass(RedTest03.class);
job3.setMapOutputKeyClass(NullWritable.class);
job3.setMapOutputValueClass(ResultData.class);
job3.setOutputKeyClass(ResultData.class);
job3.setOutputValueClass(NullWritable.class);
URI uri[] = new URI[2];
uri[0] = new URI("file:///D:/MP/TFIDF/output1/part-r-00000");
uri[1] = new URI("file:///D:/MP/TFIDF/output1/part-r-00001");
job3.setCacheFiles(uri);
FileInputFormat.setInputPaths(job3, "D:\\MP\\TFIDF\\output2\\part-r-00000");
String[] f2 = {"FilmName", "word", "TF", "IDF", "TF_IDF"};
DBOutputFormat.setOutput(job3, "resultData", f2);
// FileOutputFormat.setOutputPath(job3, new Path("D:\\MP\\TFIDF\\output3"));
System.exit(job3.waitForCompletion(true) ? 0 : 1);
}
}
}
}
结果
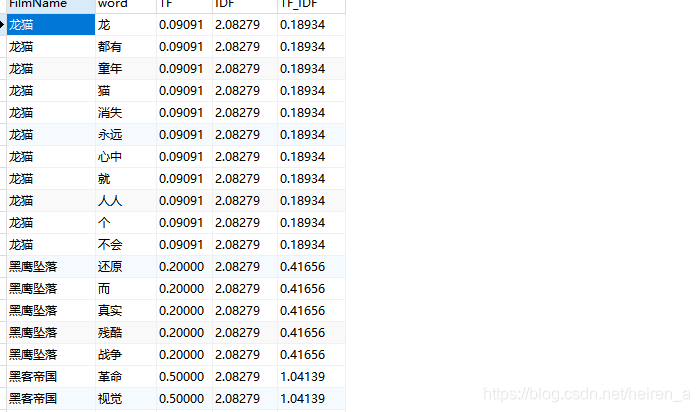














 355
355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









