






 Quartz是一款开源的Java任务调度框架,用于执行任意任务。它包括Job(任务)、Trigger(触发器)和Scheduler(调度器)三个核心组件。Job是任务实现,Trigger定义执行时间,Scheduler负责调度。在实战中,文章展示了如何导入Quartz依赖,创建并执行任务,以及使用JobDataMap传递数据。同时,讨论了无状态和有状态Job的区别,以及如何通过Trigger设置任务的开始、结束时间和执行间隔。
Quartz是一款开源的Java任务调度框架,用于执行任意任务。它包括Job(任务)、Trigger(触发器)和Scheduler(调度器)三个核心组件。Job是任务实现,Trigger定义执行时间,Scheduler负责调度。在实战中,文章展示了如何导入Quartz依赖,创建并执行任务,以及使用JobDataMap传递数据。同时,讨论了无状态和有状态Job的区别,以及如何通过Trigger设置任务的开始、结束时间和执行间隔。
一、初识Quartz
1. 概念
quartz 是一款开源且丰富特性的**“任务调度库”,能够集成与任何的java** 应用,下到独立应用,大到电子商业系统。quartz就是基于java实现的任务调度框架,用于执行你想要执行的任何任务。
什么是 任务调度 ?任务调度就是我们系统中创建了 N 个任务,每个任务都有指定的时间进行执行,而这种多任务的执行策略就是任务调度。
quartz 的作用就是让任务调度变得更加丰富,高效,安全,而且是基于 Java 实现的,这样子开发者只需要调用几个接口坐下简单的配置,即可实现上述需求。
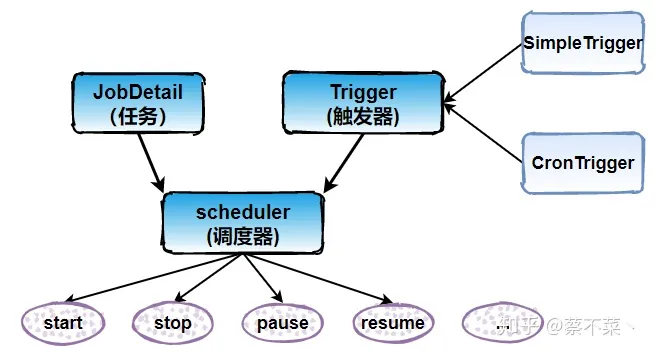
2. 核心
1)任务 Job
我们想要调度的任务都必须实现 org.quartz.job 接口,然后实现接口中定义的 execute( ) 方法即可
2)触发器 Trigger
Trigger 作为执行任务的调度器。我们如果想要凌晨1点执行备份数据的任务,那么 Trigger 就会设置凌晨1点执行该任务。其中 Trigger 又分为 SimpleTrigger 和 CronTrigger 两种
3)调度器 Scheduler
Scheduler 为任务的调度器,它会将任务 Job 及触发器 Trigger 整合起来,负责基于 Trigger 设定的时间来执行 Job
3. 体系结构
二、实战Quartz
上面我们大概介绍了 Quartz,那么该如何使用了,请往下看:
导入 Quartz 依赖
<!--quartz-->
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.3.2</version>
</dependency>自定义任务
public class TestJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) {
String data = LocalDateTime.now()
.format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
System.out.println("START DATA BACKUP, current time :" + data);
}
}创建任务调度
public class TestScheduler {
public static void main(String[] args) throws Exception {
// 获取任务调度的实例
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
// 定义任务调度实例, 并与TestJob绑定
JobDetail job = JobBuilder.newJob(TestJob.class)
.withIdentity("testJob", "testJobGroup")
.build();
// 定义触发器, 会马上执行一次, 接着5秒执行一次
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("testTrigger", "testTriggerGroup")
.startNow()
.withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(5))
.build();
// 使用触发器调度任务的执行
scheduler.scheduleJob(job, trigger);
// 开启任务
scheduler.start();
}
}
/** OUTPUT:
START DATA BACKUP, current time :2020-11-17 21:48:30
START DATA BACKUP, current time :2020-11-17 21:48:35
START DATA BACKUP, current time :2020-11-17 21:48:40
START DATA BACKUP, current time :2020-11-17 21:48:45
**/通过以上示例,我们成功执行了一个任务,我们来回顾一下程序中出现的几个重要参数:
Job 和 JobDetail
JobExecutionContext
JobDataMap
Trigger
1. Job 和 JobDetail
1)Job
Job 是工作任务调度的接口,任务类需要实现该接口。该接口中定义了 execute 方法,我们需要在里面编写任务执行的业务逻辑,类似 JDK 提供的 TimeTask 类的 run方法。每次调度器执行 Job 时,在调用 execute 方法之前都会创建一个新的 Job 实例,当调用完成后,关联的 Job 对象示例会被释放,释放的实例会被垃圾回收机制回收
2)JobDetail
JobDetail 是为 Job 实例提供了许多设置属性,以及 JobDetailMap 成员变量属性,它用来存储特定 Job 实例的状态信息,调度器需要借助 JobDetail 对象来添加 Job 实例。
其中有几个重要属性:
JobDataMap jobDataMap = jobDetail.getJobDataMap();
String name = jobDetail.getKey().getName();
String group = jobDetail.getKey().getGroup();
String jobName = jobDetail.getJobClass().getName();两者之间的关系:
JobDetail 定义的是任务数据,而真正的执行逻辑是是在 Job 中。这是因为任务是有可能并发执行,如果 Scheduler 直接使用 Job ,就会存在对同一个 Job 实例并发访问的问题。而 采用JobDetail & Job 方式, Scheduler 每次执行,都会根据 JobDetail 创建一个新的 Job 实例,这样就可以规避并发访文的问题
2. JobExecutionContext
当 Scheduler 调用一个 Job ,就会将 JobExecutionContext 传递给 Job 的 execute() 方法。这样子在Job 中就能通过 JobExecutionContext 对象来访问到 Quartz 运行时候的环境以及 Job 本身的明细数据。

3. JobDataMap
顾名思义 JobDataMap 是一个 Map ,它实现了 JDK中的 Map 接口,可以用来存取基本数据类型,也可以用来转载任何可序列化的数据对象,当 Job 实例对象被执行时这些参数对象会传递给它。示例如下:
任务调度类:
JobDetail jobDetail = JobBuilder.newJob(TestJob.class)
.usingJobData("testJobDetail", "jobDetail数据存放")
.withIdentity("testJob", "testJobGroup")
.build();
Trigger trigger = TriggerBuilder.newTrigger()
.usingJobData("testTrigger", "trigger数据存放")
.withIdentity("testTrigger", "testTriggerGroup")
.startNow()
.withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(5))
.build();Job 任务类:
public class TestJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) {
System.out.println(jobExecutionContext.getJobDetail()
.getJobDataMap().get("testJobDetail"));
System.out.println(jobExecutionContext.getTrigger()
.getJobDataMap().get("testTrigger"));
}
}
/** OUTPUT:
jobDetail数据存放
trigger数据存放
**/以上我们是通过 getJobDataMap( ) 方法来获取 JobDataMap 中的值,我们还可以使用另外一种方式来获取:
Job 任务类:
public class TestJob implements Job {
private String testJobDetail;
public void setTestJobDetail(String testJobDetail) {
this.testJobDetail = testJobDetail;
}
@Override
public void execute(JobExecutionContext jobExecutionContext) {
System.out.println(testJobDetail);
}
}
/** OUTPUT:
jobDetail数据存放
**/**以上方式便是:**只要我们在Job实现类中添加对应key的setter方法,那么Quartz框架默认的JobFactory实现类在初始化 Job 实例对象时回自动地调用这些 setter 方法
注: 如果遇到同名的 key,比如我们在JobDetail 中存放值的 key 与在 Trigger 中存放值的 key 相同,那么最终 Trigger 的值会覆盖掉 JobDetail 中的值,示例如下:
任务调度类:两者中都存放了 key 为 testInfo 的值
JobDetail jobDetail = JobBuilder.newJob(TestJob.class)
.usingJobData("testInfo", "jobDetail数据存放")
.withIdentity("testJob", "testJobGroup")
.build();
Trigger trigger = TriggerBuilder.newTrigger()
.usingJobData("testInfo", "trigger数据存放")
.withIdentity("testTrigger", "testTriggerGroup")
.startNow()
.withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(5))
.build();Job 任务类:会输出 Trigger 中存放的值
public class TestJob implements Job {
private String testInfo;
public void setTestInfo(String testInfo) {
this.testInfo = testInfo;
}
@Override
public void execute(JobExecutionContext jobExecutionContext) {
System.out.println(testInfo);
}
}
/** OUTPUT:
trigger数据存放
**/4. Job 的状态
如果我们有个需求是统计每个任务的执行次数,那么你会怎么做?

也许你会想到使用上面说到的 JobDataMap,那就让我们尝试下:
任务调度类
// 我们在 JobDataMap 中定义了一个值为 0 的初始值
JobDetail jobDetail = JobBuilder.newJob(TestJob.class)
.usingJobData("executeCount", 0)
.withIdentity("testJob", "testJobGroup")
.build();Job 任务类
@Slf4j
public class TestJob implements Job {
private Integer executeCount;
public void setExecuteCount(Integer executeCount) {
this.executeCount = executeCount;
}
@Override
public void execute(JobExecutionContext jobExecutionContext) {
String data = LocalDateTime.now()
.format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
log.info("execute count: {}, current time: {}",
++executeCount, data);
//将累加的 count 存入JobDataMap中
jobExecutionContext.getJobDetail()
.getJobDataMap().put("executeCount", executeCount);
}
}
/** OUTPUT:
execute count: 1, current time: 2020-11-17 22:38:48
execute count: 1, current time: 2020-11-17 22:38:52
execute count: 1, current time: 2020-11-17 22:38:57
**/按照上面的想法我们写出了这部分代码,但貌似打脸了,结果并没有按照我们预计的发展,是逻辑不对吗,貌似写的也没什么问题。这时你会不会回忆到上面我讲过的一句话:"在调用 execute 方法之前都会创建一个新的 Job 实例",这就牵引出了 Job 状态的概念:
无状态的 Job
每次调用时都会创建一个新的 JobDataMap
有状态的 Job
多次 Job 调用可以持有一些状态信息,这些状态信息存储在 JobDataMap 中
那么问题来了,如果让 Job 变成有状态?这个时候我们可以借助一个注解:@PersistJobDataAfterExecution ,加上这个注解后,我们再来试下:
Job 任务类:
@Slf4j
@PersistJobDataAfterExecution
public class TestJob implements Job {
private Integer executeCount;
public void setExecuteCount(Integer executeCount) {
this.executeCount = executeCount;
}
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
String data = LocalDateTime.now().
format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
log.info("execute count: {}, current time: {}",
++executeCount, data);
//将累加的 count 存入JobDataMap中
jobExecutionContext.getJobDetail().
getJobDataMap().put("executeCount", executeCount);
}
}
/** OUTPUT:
execute count: 1, current time: 2020-11-17 22:28:48
execute count: 2, current time: 2020-11-17 22:28:52
execute count: 3, current time: 2020-11-17 22:28:57
**/可以看到加了 @PersistJobDataAfterExecution ,我们已经成功达到了我们的目的。
5. Trigger
经过以上示例,我们已经大概知道了 Quartz 的组成,我们定义了任务之后,需要用触发器 Trigger 去指定 Job 的执行时间,执行间隔,运行次数等,那么 Job 与 Trigger 的结合,我们中间还需要 Scheduler 去调度,三者关系大致如下:

其中 Trigger 又有几种实现类如下:
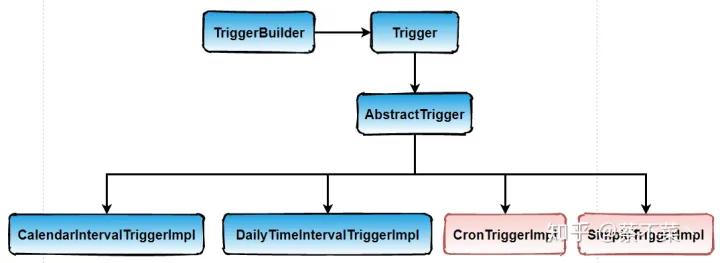
大致有四个实现类,但是我们平时用的最多的还是 CronTriggerImpl 和 SimpleTriggerImpl
我们如果想要定义任务何时执行,何时结束,我们可以这样做:
任务调度类
Date startTime = new Date();
startTime.setTime(startTime.getTime() + 5000);
Date endTime = new Date();
endTime.setTime(startTime.getTime() + 10000);
Trigger trigger = TriggerBuilder.newTrigger()
.usingJobData("testInfo", "trigger数据存放")
.withIdentity("testTrigger", "testTriggerGroup")
.startNow()
.startAt(startTime)
.endAt(endTime)
.withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(5))
.build();Job 任务类
@Slf4j
@PersistJobDataAfterExecution
public class TestJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
Trigger trigger = jobExecutionContext.getTrigger();
log.info("start time : {}, end time: {}",
trigger.getStartTime(), trigger.getEndTime());
}
}
/** OUTPUT:
start time : Thu Nov 17 22:42:51 CST 2020, end time: Thu Nov 17 22:43:01 CST 2020
start time : Thu Nov 17 22:42:51 CST 2020, end time: Thu Nov 17 22:43:01 CST 2020
**/通过控制台可以看到,任务执行了两次便已经停止了,因为已经超过了停止时间 Thu Nov 17 22:43:01 CST 2020

















 1922
1922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









