







 本文详细介绍了如何在三台服务器上搭建Spark Standalone高可用(HA)模式,包括环境准备、安装配置、启动测试等步骤。通过Zookeeper实现Master的故障切换,确保集群稳定性。同时,还进行了主备切换的测试以及提交Job验证。
本文详细介绍了如何在三台服务器上搭建Spark Standalone高可用(HA)模式,包括环境准备、安装配置、启动测试等步骤。通过Zookeeper实现Master的故障切换,确保集群稳定性。同时,还进行了主备切换的测试以及提交Job验证。
基情链接
模式说明
Spark Standalone Mode - Spark 2.4.5 Documentation (apache.org)
Spark Standalone 集群是 Master-Slaves 架构的集群模式,和大部分的 Master-Slaves 结构集群一样,存在着 Master 单点故障的问题,该模式基于 Zookeeper 实现 HA
当 Active 的 Master 出现故障时,另外的一个 Standby Master 会被选举出来。由于集群的信息,包括 Worker, Driver 和 Application 的信息都已经持久化到文件系统,因此在切换的过程中只会影响新 Job 的提交,对于正在进行的 Job 没有任何的影响
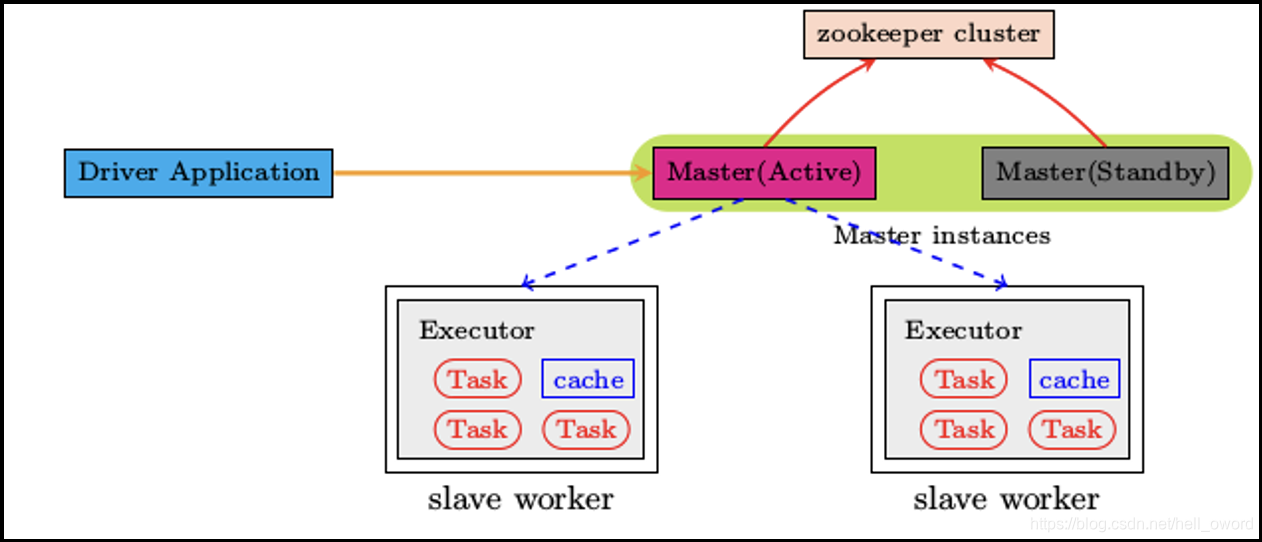
搭建准备
环境准备
云服务器 3 台
| node1/172.17.0.8 | node2/172.17.30.12 | node3/172.17.30.26 |
|---|---|---|
| 主< |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









