







贪心算法(Greedy Alogorithm)又叫登山算法,它的根本思想是逐步到达山顶,即逐步获得最优解,是解决最优化问题时的一种简单但是适用范围有限的策略。
贪心算法没有固定的框架,算法设计的关键是贪婪策略的选择。贪心策略要无后向性,也就是说某状态以后的过程不会影响以前的状态,至于当前状态有关。
贪心算法是对某些求解最优解问题的最简单、最迅速的技术。某些问题的最优解可以通过一系列的最优的选择即贪心选择来达到。但局部最优并不总能获得整体最优解,但通常能获得近似最优解。
在每一步贪心选择中,只考虑当前对自己最有利的选择,而不去考虑在后面看来这种选择是否合理。
贪心算法和动态规划区别:
贪心法求解的问题满足以下特征:
最优子结构性质。当一个问题的最优解包含其子问题的最优解时,称此问题具有最优子结构性质,也称此问题满足最优性原理。从局部最优能扩展到全局最优。
贪心选择性质。问题的整体最优解可以通过一系列局部最优的选择来得到。
动态规划:
重叠子问题:子问题是原大问题的小版本;计算大问题的时候,需要多次重复计算小问题。
最优子结构:大问题的最优解包含小问题的最优解;可以通过小问题的最优解推导出大问题的最优解。
常见的贪心问题
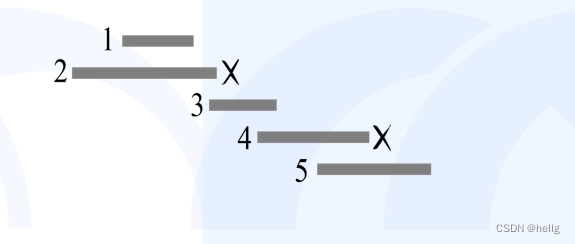
1、活动安排问题(区间调度问题) 有很多电视节目,给出它们的起止时间。有些节目时间冲突。问能完整看完的电视节目最多有多少?
解题的关键在于选择什么贪心策略,才能安排尽量多的活动。由于活动有开始时间和结束时间,考虑三种贪心策略:
(1)最早开始时间:错误,因为如果一个活动迟迟不终止,后面的活动就无法开始
(2)最早结束时间:合理,一个尽快终止的活动,可以容纳更多的后续活动。
(3)用时最少:错误。
2. 区间覆盖问题 给定一个长度为n的区间,再给出m条线段的左端点(起点)和右端点(终点)。问最少用多少条线段可以将整个区间完全覆盖。
贪心策略: 尽量找出更长的线段。
解题步骤是:
(1)把每个线段按照左端点递增排序。
(2)设已经覆盖的区间是[L, R],在剩下的线段中,找所有左端点小于等于R,且右端点最大的线段,把这个线段加入到已覆盖区间里,并更新已覆盖区间的[L, R]值。
(3)重复步骤(2),直到区间全部覆盖。
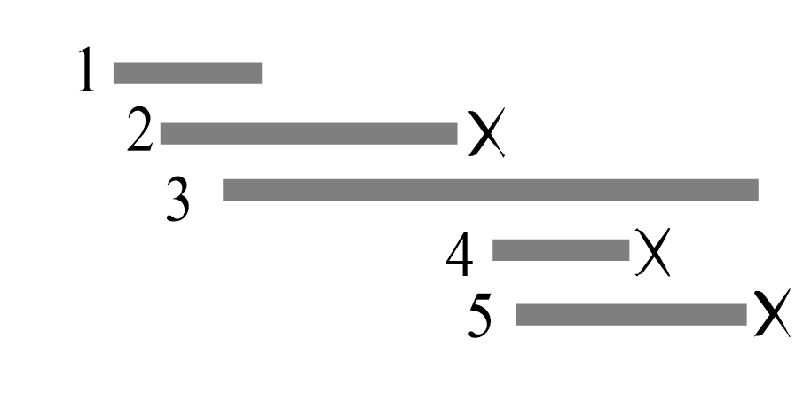
3. 最优装载问题 有n种药水,体积都是V,浓度不同。把它们混合起来,得到浓度不大于w%的药水。问怎么混合,才能得到最大体积的药水?注意一种药水要么全用,要么都不用,不能只取一部分。
贪心策略:要求配置浓度不大于w%的药水,贪心思路:尽量找浓度小的药水。 先对药水按浓度从小到大排序,药水的浓度不大于w%就加入,如果药水的浓度大于w%,计算混合后总浓度,不大于w%就加入,否则结束判断。
4. 多机调度问题 有n个独立的作业,由m台相同的机器进行加工。
作业i的处理时间为ti,每个作业可在任何一台机器上加工处理,但不能间断、拆分。
要求给出一种作业调度方案,在尽可能短的时间内,由m台机器加工处理完成这n个作业。
贪心策略:最长处理时间的作业优先,即把处理时间最长的作业分配给最先空闲的机器。让处理时间长的作业得到优先处理,从而在整体上获得尽可能短的处理时间。
题目:翻硬币
题目描述
小明正在玩一个"翻硬币"的游戏。
桌上放着排成一排的若干硬币。我们用 * 表示正面,用 o 表示反面(是小写字母,不是零)。
比如,可能情形是:**oo***oooo;
如果同时翻转左边的两个硬币,则变为:oooo***oooo。
现在小明的问题是:如果已知了初始状态和要达到的目标状态,每次只能同时翻转相邻的两个硬币,那么对特定的局面,最少要翻动多少次呢?
我们约定:把翻动相邻的两个硬币叫做一步操作。
输入描述
两行等长的字符串,分别表示初始状态和要达到的目标状态。
每行的长度<1000。
输出描述
一个整数,表示最小操作步数。
输入输出样例
示例
输入
**********
o****o****
输出
5题解:
s = list(input())
t = list(input())
ans = 0
for i in range(len(s) - 1):
if s[i] != t[i]:
if s[i+1] == 'o':
s[i+1] = '*'
else:
s[i+1] = 'o'
ans += 1
print(ans)
题目:快乐司机
话说现在当司机光有红心不行,还要多拉快跑。多拉不是超载,是要让所载货物价值最大,特别是在当前油价日新月异的时候。司机所拉货物为散货,如大米、面粉、沙石、泥土 ⋯⋯
现在知道了汽车核载重量为 w,可供选择的物品的数量 n。每个物品的重量为gi, 价值为pi。求汽车可装载的最大价值。(n<10000,w<10000,0<gi≤100,0≤pi≤100)
输入描述
输入第一行为由空格分开的两个整数 n,w
第二行到第n+1 行,每行有两个整数,由空格分开,分别表示 gi 和 pi。
输出描述
最大价值(保留一位小数)。
输入输出样例
示例
输入
5 36
99 87
68 36
79 43
75 94
7 35
输出
71.3题解:
n, w = map(int, input().split())
a = []
for i in range(n):
gp = list(map(int, input().split()))
a.append(gp)
a.sort(key=lambda x: x[1]/x[0], reverse=True) #这里定义lambda函数,使pi/gi求出每单位货物重量的价值
val = 0 #初始化最大价值
for k in a: #k[1]表示价值,k[0]表示重量
if k[0] < w: #能装进卡车的
val += k[1]
w -= k[0] #计算卡车余量
else:
val += w * k[1]/k[0]
break
print('%.1f' % val)这里的lambda x:x[1]/x[0]表示的是一个函数。这个函数叫做lambda函数。
三个特性
lambda函数是匿名的:所谓匿名函数,通俗地说就是没有名字的函数。lambda函数没有名字。名字可以自己随便造。
lambda函数有输入和输出:输入是传入到参数列表argument_list的值,输出是根据表达式expression计算得到的值。
lambda函数一般功能简单:单行expression决定了lambda函数不可能完成复杂的逻辑,只能完成非常简单的功能。由于其实现的功能一目了然,甚至不需要专门的名字来说明。
下面是一些lambda函数示例:
lambda x, y: x*y;函数输入是x和y,输出是它们的积x*y
lambda:None;函数没有输入参数,输出是None
lambda *args: sum(args); 输入是任意个数的参数,输出是它们的和(隐性要求是输入参数必须能够进行加法运算)
lambda **kwargs: 1;输入是任意键值对参数,输出是1
题目:防御力
题目描述
小明最近在玩一款游戏。对游戏中的防御力很感兴趣。
我们认为直接影响防御的参数为"防御性能",记作 d ,而面板上有两个防御值 A 和 B ,与 d 成对数关系,A=2d,B=3d(注意任何时候上式都成立)。
在游戏过程中,可能有一些道具把防御值 A 增加一个值,有另一些道具把防御值 B 增加一个值。
现在小明身上有 n1 个道具增加 A 的值和 n2 个道具增加 B 的值,增加量已知。
现在已知第 i 次使用的道具是增加 A 还是增加 B 的值,但具体使用那个道具是不确定的,请找到一个字典序最小的使用道具的方式,使得最终的防御性能最大。
初始时防御性能为 0,即d=0,所以 A=B=1。
输入描述
输入的第一行包含两个数 n1,n2,空格分隔。
第二行 n1 个数,表示增加 A 值的那些道具的增加量。
第三行 n2 个数,表示增加 B 值的那些道具的增加量。
第四行一个长度为 n1+n2 的字符串,由 0 和 1 组成,表示道具的使用顺序。0 表示使用增加 A 值的道具,1 表示使用增加 B 值的道具。输入数据保证恰好有 n1 个 0,n2 个 1 。
其中,字符串长度 ≤2×10^6,输入的每个增加值不超过 230。
输出描述
对于每组数据,输出 n1+n2+1 行。
前 n1+n2 行按顺序输出道具的使用情况,若使用增加A 值的道具,输出 Ax,x 为道具在该类道具中的编号(从 1 开始)。若使用增加 B 值的道具则输出Bx。
最后一行输出一个大写字母 E 。
输入输出样例
示例
输入
1 2
4
2 8
101
输出
B2
A1
B1
E 
题解:
对Ai进行结构体排序,先对Ai按增加量的从小到大排序,再按下标(字典序)排序。 对Bi进行结构体排序,先对Bi按增加量的从大到小排序,再按下标(字典序)排序。 然后按题目要求的顺序,输出Ai和Bi。
def cmp(x):
return x[1]
n1, n2 = map(int, input().split())
a = list(map(int,input().split()))
b = list(map(int,input().split()))
for i in range(n1):
a[i] = (i+1, a[i])
for i in range(n2):
b[i] = (i+1,b[i])
a.sort(key = cmp)
b.sort(key = cmp, reverse = True)
s = input()
idx1, idx2 = 0, 0
for i in range(n1 + n2):
if s[i] == '1':
print("B%d"%b[idx1][0])
idx1 += 1
else:
print("A%d"%a[idx2][0])
idx2 += 1
print('E')














 2932
2932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









