







 本文介绍了Hadoop的Namenode HA解决方案,包括使用QJM解决单点故障和通过Zookeeper实现自动故障切换。讨论了强一致性和弱一致性的问题,并详细阐述了Namenode主备切换的机制,以及Federation联邦的特点和配置。同时,提到了配置过程中涉及的参数及其作用,如JournalNodes、Zookeeper Fencing等。
本文介绍了Hadoop的Namenode HA解决方案,包括使用QJM解决单点故障和通过Zookeeper实现自动故障切换。讨论了强一致性和弱一致性的问题,并详细阐述了Namenode主备切换的机制,以及Federation联邦的特点和配置。同时,提到了配置过程中涉及的参数及其作用,如JournalNodes、Zookeeper Fencing等。
完全分布式
可以看到之前配置的完全分布式中只有一个nn节点,不能高可用。
在1x版本中存在这些问题:
hdfs:nn单点故障,压力过大,内存受限,扩展受阻。
MapReduce(MR):jboTracker访问压力大,扩展受阻;难以支持MR以外的计算框架,如spark,storm等。
##1.HA 高可用
hdfs ha :主备切换方式解决单点故障
hdfs Federation联邦:解决鸭梨过大。支持水平扩展,每个nn分管一部分目录,所有nn共享dn资源。
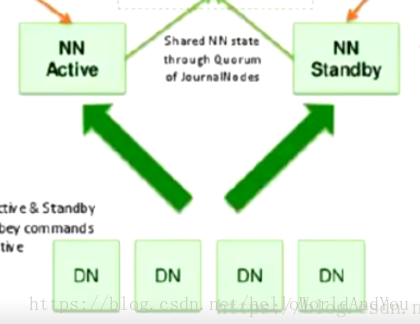
上图,NN实现高可用,nn副本数据得和nn主节点保持一致。
dn可以同时向两个NN汇报数据存储情况。而客户端则只能访问nn主节点,数据的一致性就需要nn主节点向nn副本同步数据了。存在常见的问题:强一致性,若一致性。
强一致性:nn主节点必须等到nn副本返回成功后,才能向客户端返回成功。主和副本之间可能会有如网络延迟、阻塞等问题,就造成了nn的不可用,违背了HA初衷。
弱一致性:采用异步方式,nn主无需等待nn副本返回成功,则会有nn副本数据同步失败,造成两个nn数据不一致。
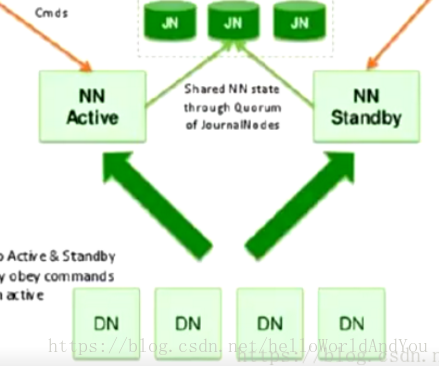
上图,加入nfs系统,如图中的jn集群。当Active节点执行任何名称空间修改时,它会将修改记录持久地记录到大多数这些JN中。待机节点能够从JN读取编辑,并且不断观察它们对编辑日志的更改。当备用节点看到编辑时,它会将它们应用到自己的命名空间。这可确保在发生故障转移之前完全同步命名空间状态,保证两个nn数据最终的一致性。
这里nn主节点挂掉后,nn副本不能自动升级为主节点,还需人为干涉。
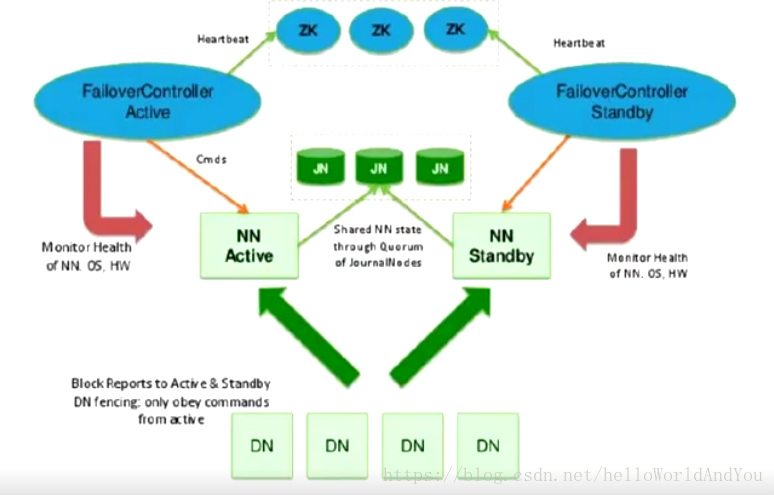
上图,加入zookeper集群,当nn主节点挂掉,通过zk自动将nn副本升级为主节点。
为了提供快速故障转移,备用节点还必须具有关于群集中块的位置的最新信息。为了实现这一点,DataNode配置了所有NameNode的位置,并向NN发送块位置信息和心跳
1)如何确定哪个nn是主节点
图中还新增了一个zkfc角色,是一个jvm进程,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1266
1266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









