







Set集合是无序的,元素不可重复的。
Set接口中的方法和Collection一致。
Set集合有三个重要子类HashSet,LinkedHashSet和TreeSet
1.HashSet
HashSet类实现 Set 接口,由哈希表(实际上是一个 HashMap 实例)支持。它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变(Set底层的存储方式是由算法来完成的,所以说一定哪一天升级后算法就变化了,元素的存储位置也就改变了)。此类允许使用 null 元素。 是不同步的。
什么是哈希表?
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
简单讲,哈希函数是一种算法,通过这种算法算出来很多元素的地址值,把这些值存储起来就叫做哈希表。
其实,哈希表里面存储的还是数组,如果一个数组想要查找元素,就要遍历数组,一个一个去比较。而哈希这种算法对数组进行了优化。它将要存储的元素代入到哈希函数中去,计算出一个位置,然后就把这个元素存储到这个位置上,如果想要查找元素,就再算一遍位置,然后直接到这个位置上去获取。
例如要存储字符串“ab”到数组中去,一般情况下就直接把“ab”放到0角标上就行了。但是这种方法在查询的时候需要遍历数组逐个比较,速度慢。所以就根据元素自身的特点,定义一个函数,把“ab”代入到这个函数中去,对元素进行计算,获取计算结果,这个结果就是“ab”在数组中的位置。这种方式的好处就是在查找“ab”在数组中的位置时,就不需要遍历了,直接用“ab”再算一遍位置,然后去找这个位置就行了。这个算法就是哈希算法。
每个对象都有自己的哈希值,因为每个对象都是Object类的子类,Object类中有方法int hashCode()返回该对象的哈希码值,这个方法就是用来算对象哈希值的方法。这个方法是由Windows实现的,我们不用管,但是我们自己的对象可以覆盖这个方法,建立对象自身的哈希值。
常用的哈希算法:
1. 直接寻址法:取关键字或关键字的某个线性函数值为散列地址。即H(key)=key或H(key) = a•key + b,其中a和b为常数(这种散列函数叫做自身函数)
2. 数字分析法
3. 平方取中法
4. 折叠法
5. 随机数法
6. 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即 H(key) = key % p, p<=m。不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。对p的选择很重要,一般取素数或m,若p选的不好,容易产生同义词。
如果哈希算法是字符Unicode码求和再取余
function(element){
//自定义哈希算法
97+98=195
returen 195%10;//结果是5
}
那么“ab”的地址就是5,把“ab”放在数组角标为5的位置上,查找的时候直接用“ab”再进行运算,算出结果是5,直接去角标5的位置上查找元素,然后判断该元素是不是“ab”,如果不是,那么这个数组中就没有“ab”;如果已经把“ab”放在角标为5的位置上,还要再存一个“ab”这个时候会先计算ab的位置,然后判断是否相同,如果相同话就不再保存。所以这个算法提高了查询效率,但是缺点就是不能保存重复数据。
怎么判断两个元素的方式是否相同?判断哈希值是否相同是使用hashCode方法,判断内容是否相同是使用equals方法。
注意:如果hashCode不同,就不再判断equals了,因为肯定是两个不同的元素。
如果想要存储“ba”,首先计算哈希值,结果相同,然后判断内容,结果不相同,这种情况叫做哈希冲突。
散列冲突的解决方案:
1. 开方定址法
这种方法也称再散列法,其基本思想是:当关键字key的哈希地址p=H(key)出现冲突是,以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p1为基础,产生另一个哈希地址p2……直到找出一个不冲突的哈希地址pi,将相应元素存入其中。
2. 再哈希法
这种方法是同时构造多个不同的哈希函数,当哈希地址冲突时,在用别的哈希函数进行计算,如果冲突再换哈希函数,直到算出一个不冲突的哈希地址。
3. 链地址法
这种方法的基本思想是将所有哈希地址为i的元素构成一个成为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。
4.建立公共溢出区
将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
存储字符串对象
HashSet hs = new HashSet();
hs.add("ABC1");
hs.add("ABC2");
hs.add("ABC3");
hs.add("ABC4");
hs.add("ABC2");
hs.add("ABC3");
Iterator it = hs.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}输出结果:
ABC1
ABC4
ABC2
ABC3
Set集合中存储对象是无序的,并且相同的元素不会进行保存。
Set集合只有一种取出元素的方式,就是Iterator迭代器。
存储自定义对象
在开发中,我们使用更多的是自定义对象而不是字符串对象
public class Person {
private String name;
private int age;
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
public class HashSetTest{
public static void main(String[] args){
HashSet hs = new HashSet();
hs.add(new Person("lisi4",24));
hs.add(new Person("lisi7",27));
hs.add(new Person("lisi1",21));
hs.add(new Person("lisi9",29));
hs.add(new Person("lisi7",27));
Iterator it = hs.iterator();
while(it.hasNext()){
Person p = (Person)it.next();//自定义对象要做强转动作,add接受后Person提升为Object
System.out.println(p.getName()+"...."+p.getAge());
}
}
}输出结果:
lisi1….21
lisi7….27
lisi4….24
lisi7….27
lisi9….29
HashSet集合数据结构是哈希表,所以存储元素的时候,使用元素的hashCode方法来确定位置,如果位置相同,再通过元素的equlas方法来判断元素是否相同。
在该示例中,Person对象的哈希值是通过调用Object中的hashCode方法,并且判断内容是否相同也是用的Object中的equals方法。这5个Person对象的hashCode不相同,所以HashSet集合认为他们是5个不同的元素。所以我们需要建立自己的hashCode方法来计算元素的位置和equals方法来判断元素是否相同,所以需要在Person类中复写Object的hashCode和equals方法。
public class Person{
//定义变量,构造函数,get、set方法
public int hashCode(){
return name.hashCode+age();//人类的特点就是姓名和年龄,所以根据姓名和年龄计算地址值
}
public boolean equals(Object obj){
Person p = (Person)obj;
return this.name.equals(p.name) && this.age==p.age;//这里调用的equals方法是字符串name中的equals方法,比较姓名是否相同
}
}输出结果:
lisi1….21
lisi9….29
lisi4….24
lisi7….27
在实际开发过程中一般要复写hashCode、equals、toString方法,Eclipse中提供了快捷书写hashCode和equals方法,toString方法的选项。
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());//为了防止name.hashCode+age出现重复结果,就把age随便乘以一个数
return result;
}
public boolean equals(Object obj) {
if (this == obj)
return true;
/*
if (!obj instanceof Person){
throw new ClassCastException("类型错误");如果传入的类型不对,直接抛出类型错误
}
*/
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
public String toString(){//如果直接使用从Object中继承的toString方法,返回结果就是哈希值,没有意义,一般情况下我们需要根据对象的实际情况,返回对对象的描述,所以需要重写toString方法。
return name+":"+age;
}2.TreeSet
TreeSet是按照元素的字典顺序排序,这个顺序我们不称之为有序,有序是指的存入和取出的顺序。这里的顺序我们可以叫做指定的顺序。
TreeSet是不同步的。
存储字符串对象
比较简单,略过。
存储自定义对象
1. 自然排序(实现Comparable接口)
继续使用Person类,创建TreeSet集合如下:
public class TreeSetDemo{
public static void main(String[] args){
TreeSet ts = new TreeSet();
ts.add(new Person("wangwu",21));
ts.add(new Person("zhaoliu",26));
ts.add(new Person("zhangsan",23));
ts.add(new Person("sunqi",27));
ts.add(new Person("lisi",21));
Iterator it = ts.iterator();
while (it.hasNext()) {
Person p = (Person)it.next();
System.out.println(System.out.println(p.getName()+"......"+p.getAge()););
}
}
}运行发现报错Person cannot be cast to java.lang.Comparable
因为TreeSet是给元素排序用的,既然排序就要进行大小的比较,但是两个Person对象不能进行比较。
Comparable接口
此接口强行对实现它的每个类的对象进行整体排序。这种排序被称为类的自然排序,类的 compareTo 方法被称为它的自然比较方法。
Person类用来描述人这类事务,如果想要把人放在TreeSet中进行排序,那么Person应该在已经具备的基本功能外还要具备一个扩展功能,就是比较的功能。这个比较的功能已经被定义在了Comparable接口中,所以如果想要Person对象具备比较性,只要让Person类实现Comparable接口就行了。
修改Person类
public class Person implements Comparable{
//hashCode,equals,toString,set,get,构造函数
public int compareTo(Object obj){
Person p = (Person)obj;
int temp = this.age - p.age;
return temp==0?this.name.compareTo(p.name):temp;//先按年龄排序,年龄相同再按姓名排序
//int temp = this.name.compareTo(p.name);先按姓名排序,姓名相同再按年龄排序
//return temp==0?this.age-p.age:temp;
}
}输出结果:
lisi……21
wangwu……21
zhangsan……23
zhaoliu……26
sunqi……27
在上面的例子中比较name时调用的compareTo方法是字符串中的compareTo方法,其实String类也实现了接口Comparable,字符串中的compareTo方法重写了Comparable接口中的compareTo方法,所以字符串本身具备自然排序。只要对象想要进行比较,就要实现Comparable接口,并重写compareTo方法。
这个Person类中默认的比较排序方式就是自然排序。
2. 比较器排序(实现Comarator接口)
但是如果我们不想要按照类中默认的方式排序,或者这个类没有排序的功能怎么办?
首先不可以修改Person类,因为这个类有可能不是我们写的,我们只是拿过来用。所以我们可以使用TreeSet第二种排序方法,就是让集合自身具备比较功能。
在第一种方法中,TreeSet集合自身并不能直接对元素进行比较,是元素自身具有比较的功能,TreeSet只是按照元素比较的结果来确定元素在集合中的位置。所以如果元素自身不具备比较的功能,可以让集合对元素进行比较。
TreeSet构造方法:
TreeSet(Comparator< ? super E> comparator) :构造一个新的空 TreeSet,它根据指定比较器进行排序。插入到该 set 的所有元素都必须能够由指定比较器进行相互比较:对于 set 中的任意两个元素 e1 和 e2,执行 comparator.compare(e1, e2)
Comparator接口就是比较器。创建比较器就是实现Comparator接口,然后覆盖其中的compare方法,把比较器作为参数传给TreeSet构造函数,TreeSet集合就具备了比较功能。如果自然排序和比较器同时存在的时候,以比较器为主。
public class ComparatorByAge implements Comparator{
public int compare(Object o1,Object o2){
Person p1 = (Person)o1;
Person p2 = (Person)o2;
int temp = p1.getAge() - p2.getAge();
return temp==0?p1.getName().compareTo(p2.getName()):temp;
}
}
public class TreeSetDemo{
public static void main(String[] args){
TreeSet ts = new TreeSet(new ComparatorByAge);
//.....
}
}输出结果:
lisi……21
wangwu……21
zhangsan……23
zhaoliu……26
sunqi……27
在实际开发过程中常用的是比较器。但是一般情况下只要Person要存到集合中,除了覆盖equals,hashCode,toString方法之外也还会实现Comparable接口。Java中的很多类都实现了Comparable接口,比如String类,Integer类,所以这些类都有比较的属性,也就是说String类,Integer类本身具备自然排序。
TreeSet排序的底层原理(二叉树)
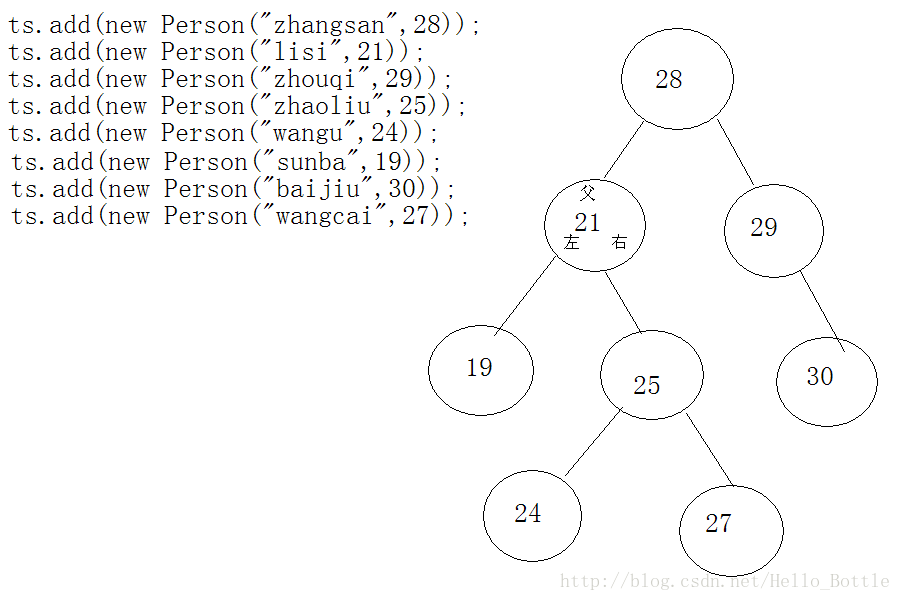
如果TreeSet中的Person对象按照年龄来排序,首先第一个元素28放在树的最顶层,然后第二个元素如果比28小就放在左边,如果比28大就放在右边…以此类推。当放25的时候,因为25比28小,所以就放在28的左边,不需要和29再进行比较,这样就提高了效率。
但即使如此,当元素数量很多的时候速度也会变慢。因为前面所有确定位置的元素都是按照元素从小到大的顺序排列的,是有序的,为了加快效率,就可以使用二分查找,在每一次放元素之前都会对已有的有序元素进行折半,再确定新元素的位置。
二叉树判断元素大小是看返回值的,如果返回1,就说明该元素比被比较的元素要大。如果返回-1,就说明该元素要小。
依据这原理,如果想要有序,按从小到大排列,就可以固定的返回1。
public class ComparatorByName implements Comparator {
public int compare(Object o1, Object o2) {
Person p1 = (Person)o1;
Person p2 = (Person)o2;
return 1;//有序。,返回-1就是倒叙
}
}3.LinkedHashSet
具有可预知迭代顺序的 Set 接口的哈希表和链接列表实现。此链接列表定义了迭代顺序,即按照将元素插入到 set 中的顺序(插入顺序)进行迭代。
是链表结构的,存第一个元素,通过hashCode计算出地址,存第二个元素的时候,第一个元素记住第二个元素的地址…以此类推。
LinkedHashSet也是不同步的。
有了LinkedHashSet类,Set集合和List集合最大的不同点就是元素是否唯一了。














 973
973











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









