






MYSQL 数据库索引底层的数据结构与算法
索引数据结构 二叉树,红黑树,B-Trees,hash,B+Trees
数据结构演示平台:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
我们的mysql 索引的数据结构是B+Trees 和Hash ,为啥使用没有使用二叉树或者其他结构呢? 接下来看
假设现在有如下表数据

二叉树
当我们在id1,id2数据使用的是二叉树数据结构放置的话就如下:

根据箭头方向从做向右,每次添加数据生成一个数,直到最后生成;如果我们现在要查询40这个值那么我们大概需要判断执行三次;
而且这个树的高度会随着数据的增加而增加;而当是数据达到一定数据量的时候二叉树查询就非常的慢,切如果数据是单一增加的例如上数据id1的那么存储的方式就是个链路;而且查询速度跟全表扫描能有啥区别;那红黑树那我们看一下红黑树;
红黑树
而红黑树只是解决了像id1,单一增加的数据,但是还是没有解决根本的树的高度问题,也就没有解决大数据下的查询速度那我们也看一下红黑树是如何遍历的;如下图
第一个树是怎么衍生的;第一次输入个1没问题,第二次输入个二判断一下大于1放在右边也没有问题;当放入3的时候就会出现问题了,这也是红黑树和二叉树的区别,他不会出现两次向右子树插入的情况,这个时候红黑树会通过一个左旋的算法把树变成根为2的树列,以此类推当出现连续像右子树插入就会进行左旋;当我们数据继续增加的时候我们的根还会变化;左旋你就完全的掌握了;
我们再看第二个树的演变是不是跟二叉树几乎一样;那我们就可以得值红黑树是解决了二叉树的连续增长问题,也就是红黑树不可能出现链表的情况;但是当数据量大的时候他还是没有解决树的高度问题,那随着数据增加我们查询速度还是会变慢;能不能有种树是可以控制高度呢?这时候就有B树,B+树和hash继续往下看
B-Trees
我们在看一下B-Trees的演变;


上面的图片的B-Trees 是以3为分裂点,什么意思呢就是我们输入1,2,3到3时上浮2为根,接着输入5则上浮4,在输入6时就为上图,以此类推当我们输入7则上浮6,然后根节点达到分裂则上浮4;此时树的高变成了3;假如我门现在查询5,他会通过二分查找找到我们的5位于根的4的后面然后在向下找到5,6这个集合直接找到5;
而我们的红黑树是要通过节点2判断找到下一个右子树4再找到右子树5在得到;在这样的案例中可能不明显;但是如果现在我的数据有100个那是不是就明显了;看到这仿佛我们的数据库索引可以使用我们的B-Trees来实现;但是现实却给了我们一巴掌他并没有使用B-Trees 树;那为啥也不使用B-Trees 呢?我想思考一下假如我们现在不加条件搜索所有的数据那我们怎么使用B-Trees 他的每个叶子都是单独没有指向的;那我是不是还要全表扫描?
B+Trees
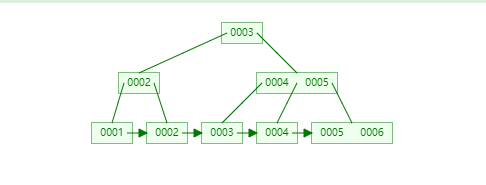
从B+Trees 和B-Trees 看出来什么区别?B+Trees 的叶子节点有了所有的数据;而想要便利B-Trees 的所有数据需要向上去扫描根,那还不如全表,但是B+Trees 不仅已经有了这样的数据而且是排好序的;而MYSQL的索引是什么?就是排好序的数据结构 在存储中我们除了要存储id外还要存储数据或者数据的地址,那B-Trees 的数据下面都要加上data,而B+Trees 存储的非叶子节点我不要存储data;那么在我们mysql的确使用就是B+Trees的改良版;
Hash 场景使用较少;

存储引擎
在我们Mysql建立数据库建立表中我们使用MyISAM 还是Innodb;其实开发中我们百分之90都是用的Innodb ,但是很多的人应该都不知道为啥使用?下面我来告诉你;当然还有很多的引擎但是几乎再用的就是这两种
MyISAM(非聚集)
使用MyISAM引擎创建的表我们去看一下他的文件,如下图
sdi不管它,有一个MYD和MYI 文件;一个是数据文件一个是索引文件那他的索引结构是啥样的如下图:

它的查询是这样的从上面的到他是通过查找到下面的值,再通过索引下指定data 回表查询出我们所要的值
Innodb 实现的是一个聚集
我们来看一下啊Innodb产生的数据库文件

上面的就是使用Innodb我们发现它的索引与数据都是一起的那也就是意味它不需要回表,那么也就是意味他的性能比Myisam 要好;
Innodb的数据存储方式如下图:

注意:在使用Innodb引擎推荐创建主键,且主键使用整型自增,这是为啥呢?
因为我们数据需要维护在我们树的数据结构中而且会通过从小到大的有序排列,如果我们没有创建主键他就会通过表中字段进行对比,如果对比不出来,他就会生成rootid来代替我们的主键,那当我们创建了一个主键且自增的整型那也是优化了性能
创建一个非主键索引数据结构如下:

我们查询加入通过这个非主键来查询走到这个索引找到ID在通过ID走主键索引查询到我们这条ID的所有数据;这个非主键索引是通过A,B,C 这种的字符演变成数字排列;当然中文也有中文的排法
其实讲到这里是不是就可以大概的知道对于开发人员的Mysql 优化就是索引优化,sql优化呢?尽可能走索引呢?思考一下
联合索引
上面讲到的非主键索引其实在我们实际使用当中又叫二级索引,在实际业务当中也很少给单列使用索引,而是使用联合索引。
联合索引就是几个字段创建的索引;

比如上图就是个联合索引;那他的排序遵循最左前缀原则,就是上面先排名子,名字小的在前面大的在右面然后排年纪一直往下,当数据重复就会在当前叶子节点向下指向一个;
索引到底可以存储多少个数据?
在我们的mysql中索引的每个节点都是16KB,那么如果我们的主键索引打算高度为3大概是2000万左右;随着数据的继续增加我们高度也会增加但是那个数据量就非常的庞大,我们已不能出现超过两千的数据还没有维护的表,阿里的开发规范是大于500万或者表数据达到2G就要考虑分表的问题;
















 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









