









https://my.oschina.net/u/4631230/blog/4562781
1
Mysql数据准备
第一天 9月10号数据
1,待支付,2020-09-10 12:20:11,2020-09-10 12:20:112,待支付,2020-09-10 14:20:11,2020-09-10 14:20:113,待支付,2020-09-10 16:20:11,2020-09-10 16:20:11
第二天 9月11号数据
1,待支付,2020-09-10 12:20:11,2020-09-10 12:20:112,已支付,2020-09-10 14:20:11,2020-09-11 14:21:113,已支付,2020-09-10 16:20:11,2020-09-11 16:21:114,待支付,2020-09-11 12:20:11,2020-09-11 12:20:115,待支付,2020-09-11 14:20:11,2020-09-11 14:20:11
对比mysql第一天和第二天的数据发现,第二天新增了订单id为4和5这两条数据,并且订单id为2和3的状态更新为了已支付
2
全量表
每天的所有的最新状态的数据。
1、全量表,有无变化,都要报
2、每次上报的数据都是所有的数据(变化的 + 没有变化的)
9月10号全量抽取到ods层
create table wedw_ods.order_info_20200910(order_id string COMMENT '订单id',order_status string COMMENT '订单状态',create_time timestamp COMMENT '创建时间',update_time timestamp COMMENT '更新时间') COMMENT '订单表'row format delimited fields terminated by ',';

create table wedw_dwd.order_info_df(order_id string COMMENT '订单id',order_status string COMMENT '订单状态',create_time timestamp COMMENT '创建时间',update_time timestamp COMMENT '更新时间') COMMENT '订单表'partitioned by (date_id string)row format delimited fields terminated by ',';
# 把wedw_ods.order_info_20200910数据全量插到dwd层2020-09-10分区insert overwrite table wedw_dwd.order_info_df partition(date_id = '2020-09-10')selectorder_id,order_status,create_time,update_timefrom wedw_ods.order_info_20200910;

9月11号全量抽取到ods层
create table wedw_ods.order_info_20200911(order_id string COMMENT '订单id',order_status string COMMENT '订单状态',create_time timestamp COMMENT '创建时间',update_time timestamp COMMENT '更新时间') COMMENT '订单表'row format delimited fields terminated by ',';
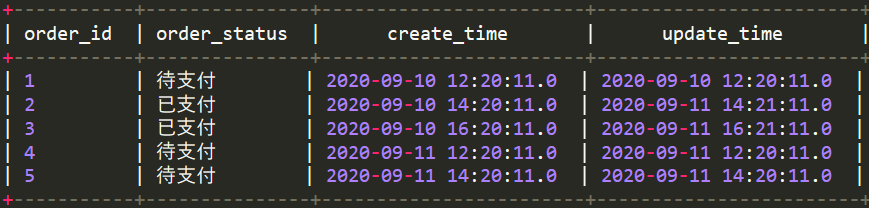
# 把wedw_ods.order_info_20200911数据全量插到dwd层2020-09-11分区insert overwrite table wedw_dwd.order_info_df partition(date_id = '2020-09-11')selectorder_id,order_status,create_time,update_timefrom wedw_ods.order_info_20200911;

全量抽取,每个分区保留历史全量快照。
3
增量表
增量表:新增数据,增量数据是上次导出之后的新数据。
1、记录每次增加的量,而不是总量;
2、增量表,只报变化量,无变化不用报
3、业务库表中需有主键及创建时间,修改时间
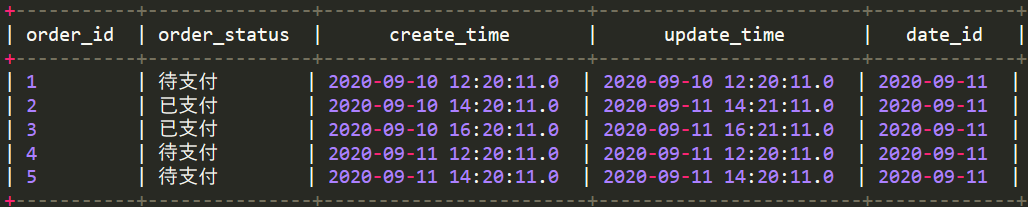
9月10号全量抽取到ods层(全量初始化)
# 把wedw_ods.order_info_20200910数据全量插到dwd层2020-09-10分区insert overwrite table wedw_dwd.order_info_di partition(date_id = '2020-09-10')selectorder_id,order_status,create_time,update_timefrom wedw_ods.order_info_20200910;
9月11号抽取更新的数据及当天新增的数据,即订单id为2,3,4,5的数据
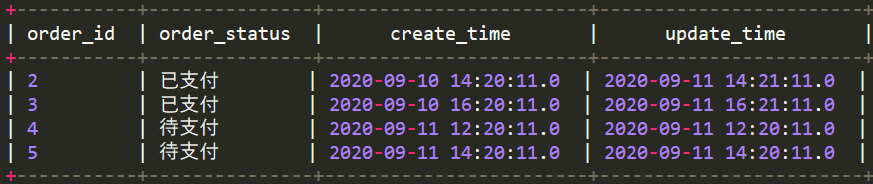
wedw_dwd.order_info_di表9月10号的分区数据与wedw_ods.order_info_20200911增量抽取的数据合并,有2种方案
a.两个表通过主键关联,dwd表存在并且ods表不存在的数据
union all 一下wedw_ods.order_info_20200911表所有的数据,即全量数据插入到dwd表的9月11号的分区
insert overwrite table wedw_dwd.order_info_di partition(date_id = '2020-09-11')selectt1.order_id,t1.order_status,t1.create_time,t1.update_timefromwedw_dwd.order_info_di t1left joinwedw_ods.order_info_20200911 t2on t1.order_id = t2.order_idwhere t1.date_id = '2020-09-10'and t2.order_id is nullunion allselectorder_id,order_status,create_time,update_timefromwedw_ods.order_info_20200911;

b.两个表数据union all一下,再根据order_id去重(根据order分组,更新时间降序,取第一条)
insert overwrite table wedw_dwd.order_info_di partition(date_id = '2020-09-11')selectt2.order_id,t2.order_status,t2.create_time,t2.update_timefrom(selectt1.order_id,t1.order_status,t1.create_time,t1.update_time,row_number() over(partition by order_id order by update_time desc) as rnfrom(selectorder_id,order_status,create_time,update_timefromwedw_dwd.order_info_diwhere date_id = '2020-09-10'union allselectorder_id,order_status,create_time,update_timefromwedw_ods.order_info_20200911) t1) t2where t2.rn = 1;
特殊增量表:da表,每天的分区就是当天的数据,其数据特点就是数据产生后就不会发生变化,如日志表。
4
拉链表
维护历史状态,以及最新状态数据
适用情况:
1.数据量比较大
2.表中的部分字段会被更新
3.需要查看某一个时间点或者时间段的历史快照信息
查看某一个订单在历史某一个时间点的状态
某一个用户在过去某一段时间,下单次数
4.更新的比例和频率不是很大
如果表中信息变化不是很大,每天都保留一份全量,那么每次全量中会保存很多不变的信息,对存储是极大的浪费
优点
1、满足反应数据的历史状态
2、最大程度节省存储
9月10号全量抽取到ods层
create table wedw_ods.order_info_20200910(order_id string COMMENT '订单id',order_status string COMMENT '订单状态',create_time timestamp COMMENT '创建时间',update_time timestamp COMMENT '更新时间') COMMENT '订单表'row format delimited fields terminated by ',';

建立dwd层拉链表
增加两个字段:
start_dt(表示该条记录的生命周期开始时间——周期快照时的状态)
end_dt(该条记录的生命周期结束时间)
end_dt= ‘9999-12-31’ 表示该条记录目前处于有效状态
create table wedw_dwd.order_info_dz(order_id string COMMENT '订单id',order_status string COMMENT '订单状态',create_time timestamp COMMENT '创建时间',update_time timestamp COMMENT '更新时间',start_dt date COMMENT '开始生效日期',end_dt date COMMENT '结束生效日期') COMMENT '订单表'partitioned by (date_id string)row format delimited fields terminated by ',';
注:第一次加工的时候需要初始化所有数据,start_time设置为数据日期2020-09-10 ,end_time设置为9999-12-31
insert overwrite table wedw_dwd.order_info_dz partition(date_id = '2020-09-10')selectorder_id,order_status,create_time,update_time,to_date(update_time) as start_dt,'9999-12-31' as end_dtfromwedw_ods.order_info_20200910;

9月11号抽取更新的数据及当天新增的数据到ods层,即订单id为2,3,4,5的数据
insert overwrite table wedw_dwd.order_info_dz partition(date_id = '2020-09-11')selectt1.order_id,t1.order_status,t1.create_time,t1.update_time,t1.start_dt,case when t1.end_dt = '9999-12-31' and t2.order_id is not null then t1.date_id else t1.end_dt end as end_dtfromwedw_dwd.order_info_dz t1left join wedw_ods.order_info_20200911 t2on t1.order_id = t2.order_idwhere t1.date_id = '2020-09-10'union allSELECTt1.order_id,t1.order_status,t1.create_time,t1.update_time,to_date(update_time) as start_dt,'9999-12-31' as end_dtFROM wedw_ods.order_info_20200911 t1;

查询当前的所有有效记录:
select*fromwedw_dwd.order_info_dzwheredate_id = '2020-09-11'and end_dt ='9999-12-31';

查询9月10号历史快照:
select*fromwedw_dwd.order_info_dzwheredate_id = '2020-09-10'and start_dt <= '2020-09-10'and end_dt >='2020-09-10';

查询9月11号历史快照:
select*fromwedw_dwd.order_info_dzwheredate_id = '2020-09-11'and start_dt <= '2020-09-11'and end_dt >='2020-09-11';

5
总结
不知道以上的一些例子大家有没有看明白呢?
在工作中,其实上述3种表都是很有可能会用到的,那么我们应该怎么选择呢?
-
如果数据量不是很大(不超过20W)且预估后续增长的非常慢,可以考虑全量表抽取,这是最简便的方法
-
如果数据量目前来说不是很大,但是业务发展很快,数据量一段时间后就会上来,建议增量抽取哦
-
目前数据量本身就非常大,肯定是需要增量抽取的,比如现在有10亿数据,如果你每天全量抽取一遍,相信我,你会抽哭的
-
对于历史状态需要保存的,这个时候就需要使用拉链表了,实际工作中,使用拉链表的场景并不会太多,比如订单表,保存订单历史状态,维表(缓慢变化维的处理)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









