







文章目录
Spark简介
Spark的历史
Spark在2012开源,距今长达6年时间,hadoop已经有12年的历史了。Spark使用Scala语言进行实现,它是一种面向对象、函数式编程语言,能够像操作本地集合对象一样轻松地操作分布式数据集,在Spark官网上介绍,它具有运行速度快、易用性好、通用性强和随处运行等特点。
spark特点
- 运行速度快
spark在内存中对数据进行迭代计算如果数据由内存读取是hadoop MapReduce的100倍。Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小.
- 易用性好
支持Scala编程java编程 Python等语言(Scala是一种高效可扩展语言,使用简洁)
- 一次编译,随意执行
spark运行在Hadoop,cloud上,能够读取HDFS,HBase Cassandra等数据源
- 通用性强
spark生态圈(BDAS)包括spark Core、spark SQL Spark Streaming等组件,这些组件提供spark Core处理内存计算框架
spark开发者
加州大学伯克利分校的AMP实验室开发的。
spark比MR快的原因
Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小。
总结来说就是:spark是基于内存迭代的,而MR是基于磁盘迭代的。
Spark的四种运行模式
- local
- standalone
- yarn
- mesos
开发Spark的语言
- Java
- Scala
- Python
- R
1,首先Spark计算框架是由Scala来写,所以Scala作为Spark的开发语言,兼容性和效率上都是毫无疑问的。
2,Java和Scala都是基于JVM的编程语言,所以Java和Scala在开发Spark上兼容性和效率都是一样的。
3,Python是解释性语言,他要在解释中运行,那么他要开发Spark应用程序,就要运行在JVM上,也就是解释器要和JVM之间要进行通信,所以它的效率要比Java和Scala差。
4,R语言,它的应用并不是很多,这里不做详细介绍。
RDD(弹性分布式数据集)
RDD简介
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD五大特性

RDD的三种算子
- Transformation类算子
- Action类算子
- 控制类算子
Transformation类算子
- map:一对一
- flatMap:一对多
- filter:一对N(0,1)
- join:inner(内连接)
- leftouter join
- rightouter join
- fullouter join
- sortByKey
- groupByKey
- reduceByKey
- sortBy
- sample
Action类算子
1、count
2、collect:将task的计算结果拉回到Driver端
3、foreach:不会回收所有task的计算结果,原理:将用户传入的函数传递到 各个节点上去执行,只能去各个节点找计算结果。
查看结果的方式:
① web UI
② 去各个节点的Worker工作目录查看 SPARK_WORKER_DIR去各个节点的Worker工作目录查看 SPARK_WORKER_DIR
4、saveAsTextFile(path) path:本地、HDFS路径
5、reduce
控制类算子
- cache
- persist
MEMORY_ONLY
DISK_ONLY
MEMORY_AND_DISK
注意点:
① 控制类算子后不能立即紧跟action类算子
② 缓存单元是Partition
③懒执行,需要action类算子触发执行
如果你的Application中只要一个job,没有必要使用控制类算子
Spark在集群中的大体运行流程
- Driver分发task到节点运行(计算找数据)。
- task执行结果拉回到Driver(有可能发生OOM)。
Driver的作用:
1)、分发任务到计算节点运行。
2)、监控task(thread)的运行情况。
3)、如果task失败,会重新发送(有限制)。
4)、可以拉回结果到Driver进程。
结论:Driver进程会和集群频繁通信。
提交Application的两种方式
-
Client
提交方式:spark-submit --deploy-mode client --class jarPath args
特点:Driver进程在客户端节点启动
适用场景:测试环境
大概运行流程:
1)、在Client本地启动Driver进程。
2)、Driver会向Master为当前Application申请资源。
3)、Master接收到请求后,会在资源充足的节点上启动Executor进程。
4)、Driver分发task到Executor执行。 -
Cluster
提交方式:spark-submit --deploy-mode cluster --class jarPath args
特点:每次启动application,Driver进程在随机一台节点启动
适用场景:生产环境
大概运行流程:
1)、客户端执行spark-submit --deploy-mode cluster --class jarPath args命令,启动一个sparksubmit进程。
2)、为Driver向Master申请资源。Driver进程默认需要1G内存,1core。
3)、master会随机找一台Worker节点启动Driver进程。
4)、Driver进程启动成功后,spark-submit进程关闭,然后Driver会向Master为当前Application申请资源。
5)、Master接收到请求后,会在资源充足的节点上启动Executor进程。
6)、Driver分发task到Executor执行。
WordCount案例
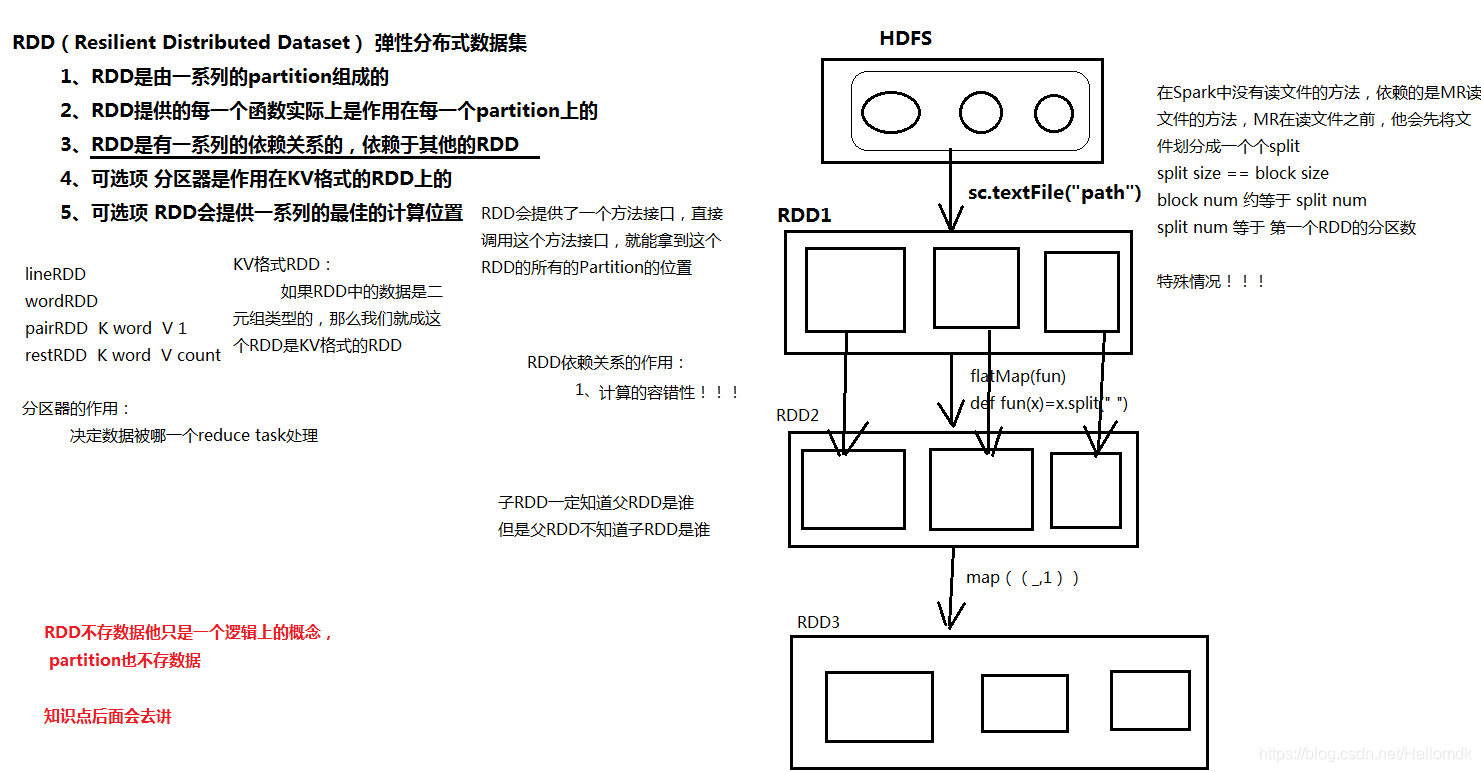
如图即是wordCount小案例的大体流程,相比较于MR应用程序简单了许多,并且执行效率上也更快。
Spark集群搭建
请参考下一篇博客Spark集群的搭建。














 2945
2945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









