







前言:心血来潮看了一个自然语言处理公开课,大牛柯林斯讲授的。觉得很好,就自己动手把它的讲稿翻译成中文。一方面,希望通过这个翻译过程,让自己更加理解大牛的讲授内容,锻炼自己翻译能力。另一方面,造福人类,hah。括号内容是我自己的辅助理解内容。
翻译的不准的地方,欢迎大家指正。
课程地址:https://www.coursera.org/course/nlangp
哥伦比亚大学 自然语言处理 公开课 授课讲稿 翻译(二):自然语言处理介绍-2
导读:接着上一节课,本节课柯老师继续回答他提出的余下问题。就语音级别、句法级别、语义级别、篇章级别中的歧义问题来说明自然语言处理的困难之处,最后柯老师就课程安排和课程要求做了简单的介绍。
So next I want to talk about some key challenges in NLP answering the question why is NLP hard. And we're actually going to focus on one particular problem, namely the problem of ambiguity which is seen time and time again in natural language problems in applications.
接下来我想讲讲一些自然语言处理的挑战,通过这来回答第二个问题:为什么自然语言处理如此困难?我们将会关注一个特殊的问题,即歧义问题。这个问题在自然语言处理技术上遍地都是。

为了更好说明问题,我们用一个句子来举例。这是一个来自Livian Lee的真实例子,句子是这么样的:At last, a computer that understandsyou like your mother. 我记得这个例子出处,大概是在二十世纪八十年代为自然语言理解所做的一个营销博客。当然这个句子的确存在歧义。它至少有三种理解方式。我们大家一起来看看,这句话的原意可能是It's sayingthat the computer understands you as well as your mother understands。但是如果你仔细看看,你会发现其他两种可能的解读,一种是the computer understands the fact that you like your mother,另一种理解是the computer understands you as well as it understands your mother。现在,即使我们单独看第一种和第三种解读,我们自己也无法明白这句话上下文是computer understand you well还是your mother understand you well。如果不能知道上下文,我们就无法回答这个问题,这样歧义就在此出现了。

So again, if we come back to this example sentence, then from a purely acoustic point of view this sequence like your, can be confused with other things. So, for example like cured is a valid sequence of two words in English. And acoustically, these two things might be quite confusable. Of course, this is much more plausible as a sentence in English than this. But nevertheless, if a speech recognizer was to rely on acoustic information alone, it's going to have to deal with all kinds of ambiguities like this where two words or two sequences of words are confusable.
这是语音识别的一个关键问题。额,我们回到前面的例子,从纯粹的声学角来看,序列‘like your’会被其他序列所混淆。额,比如序列‘like cured’就是一个英语中有意义的序列。在听觉上,这两个序列很容易被混淆。当然,对比下一句(a computer that understands you like cured mother.),上面一个句子(a computer that understands you like your mother.)在英语中更加合理。但是如果一个从事语音识别的人仅仅依靠声学信息(进行语音识别),他将会遇到很多类似容易混淆的歧义序列。
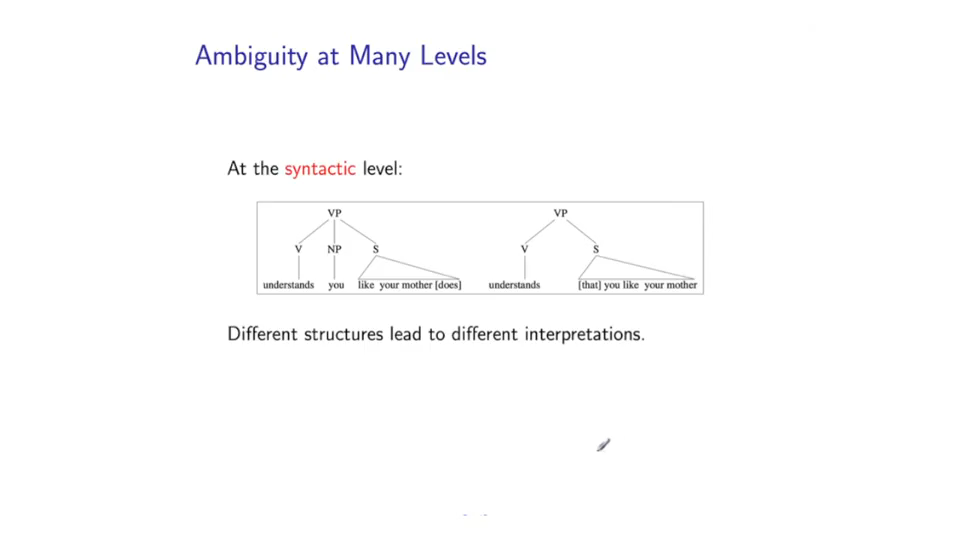
This is it understands the fact that you like your mother Actually, correspond to two quite different syntactic structures. So one of the key problems in natural language parsing, is essentially disambiguation. Choosing between different syntactic structures corresponding to different interpretations.
有意思的是,这些歧义也会出现在句法层面上。我的意思是他们(歧义)会在之前展示的句法问题中出现。额,(歧义会导致)句法层面上(出现)不同的结构。(右边)这棵句法树导致(句子)不同的含义。额,这两种不同的解读分别是the computer understands you, as well as it understands your mother.(左边句法树的含义)和it understands the fact that you like your mother.(右边句法树的含义),他们各自对应着不同的句法结构。自然语言处理句法分析的一个关键问题就是消除歧义。从对应不同含义的不同句法结构选择(合适的句法结构)。

Here's yet another level of ambiguity in language. This is roughly speaking, what we might call the semantic level. And this is an instance of what is often referred to as word sense ambiguity. So, if you look at it in a dictionary, you, if you look at many words in English or other languages, they have multiple different meanings, depending on the context. So again mother was a word in that sentence I showed you previously if look in a dictionary you'll find the conventional or rather the, the, the frequent usage of this word. But you also find a much less much less frequent usage which is given here. And a natural language processing system will have to disambiguate between these two meanings. Here's a bit more on word sense ambiguity, so if I take the sentence, "They put money in the bank", it's pretty clear here what we mean by bank. But there is an interpretation where the money is buried in mud, so we're going to have disambiguate this word to work out which of these interpretations is intended. Here's another example, I saw her duck with a telescope. So this sentence is actually ambiguous in multiple ways. I could be looking at her duck using a
telescope. I could be looking at her duck who has a telescope. You can go through many other examples. But there's a key word sense ambiguity
here which is the word duck. Duck can refer either to the animal or it can refer to the process of ducking, the verb to duck and that leads to two quite different interpretations here.
这个是语言中另外一个层次的歧义。大致的讲,我们称这一个层次为语义层。这个例子就是我们通常所说的词义歧义。额,如果你去查查字典,你会发现英语或者其他语言中,有一些词语在不同的上下文中会有着不同的语义。看这里,比如mother这个词,如果你查字典你会查到它的常规用法或者高频用法。但是你也会发现它的一个很少很少出现的(语义),这里我们给出这个语义。一个自然语言处理系统必须从这两种语义中进行歧义消除。再讲词义歧义另外一个例子,看这句话They put money in the bank. 很明显这里‘bank’是什么意思。但这里有另外一种解读: the money is buried in mud。(bank有银行,岸边之意)。所以我们要对这个bank单词进行歧义消除,去找出它想表达的含义。再来一个例子I saw her duck with a telescope. 这句话有多种歧义。这句话解读为I could be looking at her duck using a telescope. 或者I could be looking at her duck who has a telescope. 你可以这么解读其他的一些歧义例子。但是这里单词duck有很重要的词义歧义。Duck可以理解为动物或者理解为回避这个动作--duck的动词含义,这就在这句话里产生两种不同的解读。

So yet another level of ambiguity is at the discourse level and what I am going to show you here is an instance of an anaphora. This is a problem of a pronoun for example, she and revolving it resolving it to the entity that it refers to in a word. So, let's again assume that we have our sentence, except here I have Alice says, as the, the start of the sentence. And let's say the continuation is, but she doesn't know any details. Actually, I have two possible continuations here. But she doesn't know any details, or but she doesn't understand me at all. So she could refer to two different things. It could refer to your mother. Or it could refer, at refer to Alice. And so there's an ambiguity here that we need to resolve. We need to figure out which one of these two entities in the past she is referring to. And actually it's going to differ for these two cases. If I say, but she doesn't know any details, by far the most plausible interpretation is that she is referring to Alice. But if I say, but she doesn't understand me at all, in this case by far the most likely interpretation is that she refers to your mother. So this is again a very challenging proposition, taking pronouns and figuring out what entity they refer to in the past discourse.
额,另一个层次的歧义就是篇章歧义。接下来我会给大家举一个指代方面歧义的例子。这是一个名词(指代歧义)例子。单词she消解到它所指代的实体。句子这里Alice says是句子的开始,让but she doesn't know any details.成为句子的成分。实际上这里我们有两种可能成分:But she doesn't knowany details, 或 but she doesn't understand me at all.所以单词she可能指代两个不同的事物,它可能指代your mother也可能指代Alice。这就是我们必须解决的歧义问题。我们必须明白she指代前面句子中哪个实体,这里有两种不同的情况,如果(句子的成分是)but she doesn't knowany details,这种情况下最可能的潜在含义是she指代Alice。但是(句子的成分是)but shedoesn't understand me at all,这种情况下最可能的潜在含义是she指代your mother。额,所以呢,弄清楚名词指向前文的哪个实体是一个非常具有挑战性的命题。

So the final thing I want to talk about in this lecture is the contents of the course. What will this course actually be about? And so we're going to cover several topics in this course. One thing we'll look at is the basic, and [inaudible] sub problems that I mentioned earlier. Problems such as part of speech tagging, parsing, models for word sense disambiguation, and so on. A second major focus of this talk will be on machine learning or statistical methods for natural language processing. So machine learning techniques have become extremely prevalent for all of the natural
language applications and problems that I described earlier. As one example, modern machine translation systems are trained automatically from vast numbers of example translations. Statistical methods are used to induce dictionaries and other kind of models for that translation problem. So we'll talk about many basic mathematical or computational models based on machine learning techniques applied to language. These include probabilistic context free grammars hidden markov models. We'll talk about estivmation and smoothing techniques right at the start of the calss. We'll talk about a famous algorithm called the EM algorithm which is widely applied in speech recognition and also machine translation.
最后我们就讲下这个课程的主要内容。这是课程到底什么样子呢?后面课程我们将会涉及下面几个主题。第一大块呢,我们看下是我之前提及一些基础问题,像词性标注问题,句法分析,词义歧义消除模型等。课程的第二大块是自然语言处理(涉及的)机器学习,或者称为统计方法。额,在我之前讲到的自然语言处理应用和问题汇总,机器学习技术已经非常普及。比如,现在的机器翻译系统可以从大量的翻译示例中自动训练,使用统计方法产生字典和其他的翻译问题模型。我们会讲讲一些使用在语言上的基于机器学习技术基本数学或者基本计算方法。他们包括:probabilisticcontext free grammars(概率上下文无关文法) hiddenmarkov models(隐马尔科夫模型). 课程之初我们会讲到estimation and smoothing techniques (估计和平法方法)。我们也会讲到非常著名的算法:EM算法,这个算法广泛的使用于语音识别和机器翻译上。
We'll talk about a very important class of model, called log-linear models later in the class, and so on. And finally we will talk about various applications including information extraction, machine translation, and possibly natural language interfaces. So here is a syllabus for the class, we're going to start off with a problem called the language-modeling problem, which will be in some sense a warm-up. Introducing many important ideas, particularly an idea called smooth destination. We'll then talk about tagging problems, such as part of speech tagging and identity recognition. And we'll talk about hidden Markov models, which are a key model for these tagging problems. We'll talk about the parsing problem that I described earlier, and we'll talk about models for that problem. We'll then have a few lectures on machine translation where you'll see more or less from the ground up how we can build a modern machine translation system.
我们会讲到一类非常重要的模型,我们课堂上称之为log-linearmodels(对数线性模型)等。最后我们会聊聊一些诸如信息抽取、机器翻译、自然语言接口等应用。看看我们的教学大纲,我们从一个叫做语言模型的问题开讲,这可以说是我们一个热身吧。这里会介绍一些重要的思想,特别是一种叫做平滑的思想。然后,我们会讲到标注问题,比如词性标注、实体识别等。这里这些标注问题隐的关键模型—隐马尔科夫模型会被介绍。接下来呢,之前提及的句法分析问题会被讲到,这快的一些模型也会被介绍。我们会花几节课时间学习机器翻译,大家可以多多少少的知道如何从底层搭建起一个现代的机器翻译系统。

Next we'll talk about log-linear models and discriminative methods. These are a key model in statistical natural language nowadays. And they're applied to several problems which we'll go over in these lectures. And then finally, to finish up, we'll talk about semi-supervised and unsupervised
learning for NLP, which is a, a very important topic and a huge area of con research. So in terms of prerequisites for the class, coming into the class you should know some basic linear algebra. Some basic probability will be key, so you should know what discreet distribution is, what a random variable is. And finally, some basic knowledge of algorithms in computer science. And secondly, there are going to be some programming assignments on the course, so you should have some basic programming skills. For example, if you can program in Python or Java, that should be plenty for this course. One of these two program languages will be plenty for this course. Finally, in terms of background reading for the course, there are a couple of resources. So over the years I have developed some fairly comprehensive notes for many of the topics. Actually for all of the topic's you'll see in the course, so if you go to my webpage you'll find a link to those notes, and thou, they should be very useful in, asbackground for reading lectures. And in addition, as additional context I'd recommend you Jurafsky and Martin speech and language processing text book, this is by no means essential, but if you want to, want to read more on the subject, this could be very useful.
我们会继续讲到对数线性模型和判别式方法。这些是当今统计自然语言的关键模型。他们会被应用于一些我们课上提及的问题。最后,我们会谈一些自然语言处理上半监督和无监督学习,这是一个非常重要的话题和一个很广阔的研究领域。当然上这门课需要一些准备知识,你需要一些基本的线性代数知识,一些基本的统计知识也是必须的。你要了解什么是离散分布啊,什么是变量啊。一些基本的计算机算法知识也是需要的。其次,课上会布置一些编程任务,所以你需要具备基础编程技术,会个Python或Java足以对付这个课程。最后说下课程背景阅读,这里有一些资料,过去几年我对几个话题准备一些比较全面的笔记,课程上所有的话题都包含在内。如果你去我的个人主页,你会发现这些笔记的连接,这些笔记对课程是一个很有用的背景补充。另外,还有一些我推荐的内容:Jurafskyand Martin speech and language processing text book。这个不是必须的,但你想多了解这个课程,看看这些是非常有益的。
<第二节完>
哥伦比亚大学 自然语言处理 公开课 授课讲稿 翻译(一):自然语言处理介绍-1
哥伦比亚大学 自然语言处理 公开课 授课讲稿 翻译(三):语言模型介绍-1
哥伦比亚大学 自然语言处理 公开课 授课讲稿 翻译(四):语言模型介绍-2















 7677
7677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









