




 本文详细介绍了Apache Flume,一个用于收集、聚合和传输大规模日志数据的分布式系统。Flume具有分布式、高可靠性和高可用性的特点,广泛应用于日志数据的实时采集。文章讲解了Flume的体系结构,包括Source(如avro、exec、netcat、spooling directory等)、Channel(如memory和file Channel)和Sink(如logger、HDFS、HBase和Kafka)。此外,还介绍了Flume的拓扑模式(串行、复制、负载均衡和聚合),以及内部的事件处理流程。文章通过实例演示了Flume的基本应用,包括数据监听、日志传输到HDFS,并探讨了Flume的高级特性,如拦截器、选择器、Sink组逻辑处理器、事务机制和高可用性配置。
本文详细介绍了Apache Flume,一个用于收集、聚合和传输大规模日志数据的分布式系统。Flume具有分布式、高可靠性和高可用性的特点,广泛应用于日志数据的实时采集。文章讲解了Flume的体系结构,包括Source(如avro、exec、netcat、spooling directory等)、Channel(如memory和file Channel)和Sink(如logger、HDFS、HBase和Kafka)。此外,还介绍了Flume的拓扑模式(串行、复制、负载均衡和聚合),以及内部的事件处理流程。文章通过实例演示了Flume的基本应用,包括数据监听、日志传输到HDFS,并探讨了Flume的高级特性,如拦截器、选择器、Sink组逻辑处理器、事务机制和高可用性配置。
一、Flume概述
无论数据来自什么企业,或是多大量级,通过部署Flume,可以确保数据都安全、及时的送达大数据平台,我们可以集中精力在如何洞悉数据上。
1.1 Flume的定义
由Cloudera公司开发的,是一个分布式、高可靠、高可用的海量日志采集、聚合、传输的系统。
Flume支持在日志系统中定制各类数据发送方,用于采集数据。
Flume提供对数据进行简单处理,并写到各种数据接收方的能力。
简单的说,Flume就是实时采集日志的数据采集引擎。

特点:
1.分布式:flume分布式集群部署,扩展性好。
2.可靠性好:当节点出现故障时,日志能被传送到其它节点上而不会丢失。
3.易用性:flume配置使用繁琐,对使用人员专业技术要求高。
4.实时采集:flume采集流模式进行数据实时采集。
适用场景:日志文件实时采集。
其它数据采集还有:dataX、kettle、Logstash、Scribe、sqoop。
dataX:阿里开源的软件,异构数据源离线同步工具。实现包括关系型数据库(MySql、Oracle等)、HDFS、Hive、Hbase、FTP等各种异构数据源之间稳定高效的数据同步功能。
特点:
易用性:没有界面,以执行脚本的方式运行,对使用人员的技术要去较高。
性能:数据抽取性能高。
部署:可独立部署。
适用场景:在异构数据库/文件系统之间高速交换数据。
kettle:开源的ETL工具。支持数据库、FTP、文件、rest接口、hdfs、hive等平台的数据行抽取、转换、传输等操作,java编写跨平台,C/S架构,不支持浏览器模式。
特点:
易用性:有可视化设计器进行可视化操作,使用简单。
功能强大:不仅能进行数据传输,能同时进行数据清洗转换等操作。
支持多种源:支持各种数据库、FTP、文件、rest接口、hdfs、Hive等源。
部署方便:独立部署,不依赖第三方产品。
适用场景:数据量及增量不大,业务规模变化较快,要求可视化操作,对技术人员技术门槛要求低。
Logstash:应用程序日志、事件的传输、处理、管理和搜索的平台。可以用它来统一对应用程序日志进行收集管理,通过了web接口用于查询和统计。
Scribe:是facebook开源的日志收集系统,它能够在各种日之源上收集日志,存储到一个中央存储系统(可以是NFS,分布式文件系统等)上,以便进行集中统计分析处理。
sqoop:之后会讲到。
1.2 Flume体系结构

Flume架构中的组件:
Agent本质上是一个JVM进程,控制Event数据流从外部日志生产者那里传输到目的地(或下一个Agent)。一个完成的Agent包括三个组件Source、Channel、Sink,Source是指数据的来源和方式,Channel是一个数据的缓冲池,Sink定义了数据输出的方式和目的地。
Source负责接受数据到Flume Agent的组件,Source组件可以处理各种类型、各种格式的日志数据,包括avro、exec、spooldir、netcat等。
Channel是位于Source和Sink之间的缓冲区。Channel允许Source和Sink运行在不同的速率上。Channel是线程安全的,可以同时处理多个Source的写入操作和多个Sink的读取操作。常用的Channel包括:
Memory Channel是内存中的队列。在允许数据丢失的情景下使用。如果不允许数据丢失,应避免使用Memory Channel,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel将所有数据写到磁盘。因此在程序关闭、机器宕机的情况下不会丢失数据。
Sink不断地轮回Channel中的事件且批量移除它们,并将这些事件批量写入到存储或者索引系统、或者被发送到另外一个Flume Agent。
Sink是完全事务性的。从Channel批量删除数据之前,每个Sink用Channel启动一个事务。批量事件一旦成功写出到存储系统或下一个Flume Agent,Sink就利用Channel提交事务。事务一旦被提交,该Channel从自己的内部缓冲区删除事件。
Sink组件包括hdfs、logger、avro、file、null、HBase、消息队列等。
Event是Flume定义的一个数据流传输的最小单元。
1.3 Flume拓扑结构
1. 串行模式:
将多个Flume给顺序连起来,从最初的source开始到最终sink传输的目的存储系统。
此模式不建议桥接过多flume数量,flume数量过多不仅会影响传输速率,而且一旦传输过程中某个节点flume宕机,会影响整个传输系统。

2. 复制模式(单Source,多Channel、Sink模式)
将事件流向一个或多个目的地。这种模式将数据源复制到多个Channel中,每个Channel都有相同的数据,Sink可以选择传送到不同到不同的目的地。
3. 负载均衡模式(单Source、Channel,多Sink)
将多个Sink逻辑上分到一个Sink组,Flume将数据发送到不同的Sink,主要解决负载均衡和故障转移问题。

4. 聚合模式
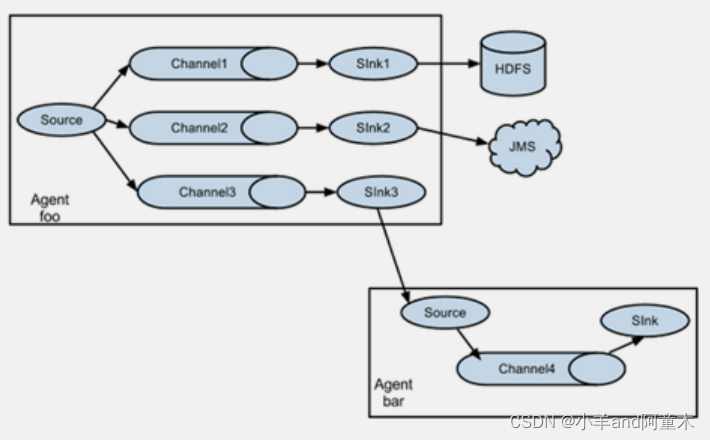
这种模式最常见,也非常实用,日常web应用通常分布在上百个服务器,大者甚至上百个、上万个服务器。产生的日志处理起来非常麻烦。用这种组合方式能很好解决这一问题,每台服务器部署一个flume采集日志,再传送到一个集中的收集日志的flume,再由此flume上传到hdfs、hbase、hive、消息队列中。

1.4 Flume内部原理
总体数据流向:Source =》Channel =》Sink
Channel:处理器、拦截器、选择器

具体过程:
1. Source接受事件,交给其Channel处理器处理事件。
2. 处理器通过拦截器Interceptor,对事件进行一些处理,比如压缩解码、正则拦截、时间戳拦截、分类等。
3. 经过拦截器处理过的事件再传给Channel选择器,将事件写入相应的Channel。
Channel选择器有两种:
Replication Channel Selector(默认),会将source过来的event发往所有的Channel(比较常用的场景是,用多个Channel实现冗余副本,保证可用性。)
Multiplexing Channel Selector,根据配置分发event。此selector会根据event中某个header对应的value来讲event发往不同的Channel。
4. 最后由Sink处理器处理各个Channel的事件。
二、安装部署
Flume官网地址:http://flume.apache.org/
文档查看地址:http://flume.apache.org/FlumeUserGuide.html
下载地址:http://archive.apache.org/dist/flume/
选择的版本 1.9.0
安装步骤:
1. 下载软件 apache-flume-1.9.0-bin.tar.gz,并上传到 linux123 上的/opt/lg/software 目录下。
2. 解压 apache-flume-1.9.0-bin.tar.gz 到 /opt/lg/servers/ 目录下;并重命名为 flume-1.9.0。
3. 在 /etc/profile 中增加环境变量,并执行 source /etc/profile,使修改生效
export FLUME_HOME=/opt/lagou/servers/flume-1.9.0
export PATH=$PATH:$FLUME_HOME/bin
4. 将 $FLUME_HOME/conf 下的 flume-env.sh.template 改名为 flume-env.sh,并添加 JAVA_HOME的配置:
cd $FLUME_HOME/conf
mv flume-env.sh.template flume-env.sh
vi flume-env.sh
export JAVA_HOME=/opt/lagou/servers/jdk1.8.0_231
三、基础应用
Flume支持的数据源种类有很多,可以来自directory、http、kafka等。
Flume提供了Source组件用来采集数据源。
常见的Source有:
(1). avro source:监听avro端口来接受外部avro客户端的事件流。avro-source接受的是经过avro序列化后的数据,然后反序列化数据继续传输。利用avro可以实现多级流动、扇出流、扇入流等效果。接收通过flume提供的avro客户端发送的日 志信息。
avro是Apache的一个数据序列化系统,由Hadoop的创始人 Doug Cutting开发,设计用于支持大批量数据交换的应用。它的主要特点有:
支持二进制序列化方式,可以便捷、快速的处理大量数据。
动态语言友好,avro提供的机制使动态语言可以方便的处理avro数据。

(2). exec source:可以将命令的输出作为source。如 ping 192.168.234.123、tail -f hive.log。
(3). netcat source:一个netcat source用来监听一个指定的端口,并接受监听到的数据。
(4). spooling directory source:将指定文件加入到“自动搜集”目录中。flume会持续监听这个目录,把文件作为source来处理。注意:一旦文件被放入到目录后,便不能修改,如果修改,flume会报错。此外,也不能有重名文件。
(5). Taildir Source(1.7):监控指定的多个文件,一旦文件内有新写入的数据,就会将其写入到指定的Sink内,本来源可靠性高,不会丢失数据。不会对跟踪的文件有任何处理,不会重命名也不会删除,不会做任何修改。目前不支持windows系统,不支持读取二进制文件,支持一行一行的读取文本文件。
采集到的日志需要进行缓存,Flume提供了Channel组件来缓存数据。
常见的Channel有:
(1). memory Channel:缓存到内存中(最常用)。
(2). file Channel:缓存到文件中。
(3). JDBC Channel:通过jdbc缓存到关系型数据库中。
(4). kafka Channel:缓存到kafka中。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2439
2439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









