







比如我们有如下的一句SQL
select * from A where id = 1;
我们可能只知道它的执行结果,却不知道在执行的整个执行中它的执行过程是什么样子的,接下来就是对这条语句的每个过程进行详细的拆分。
整体鸟瞰
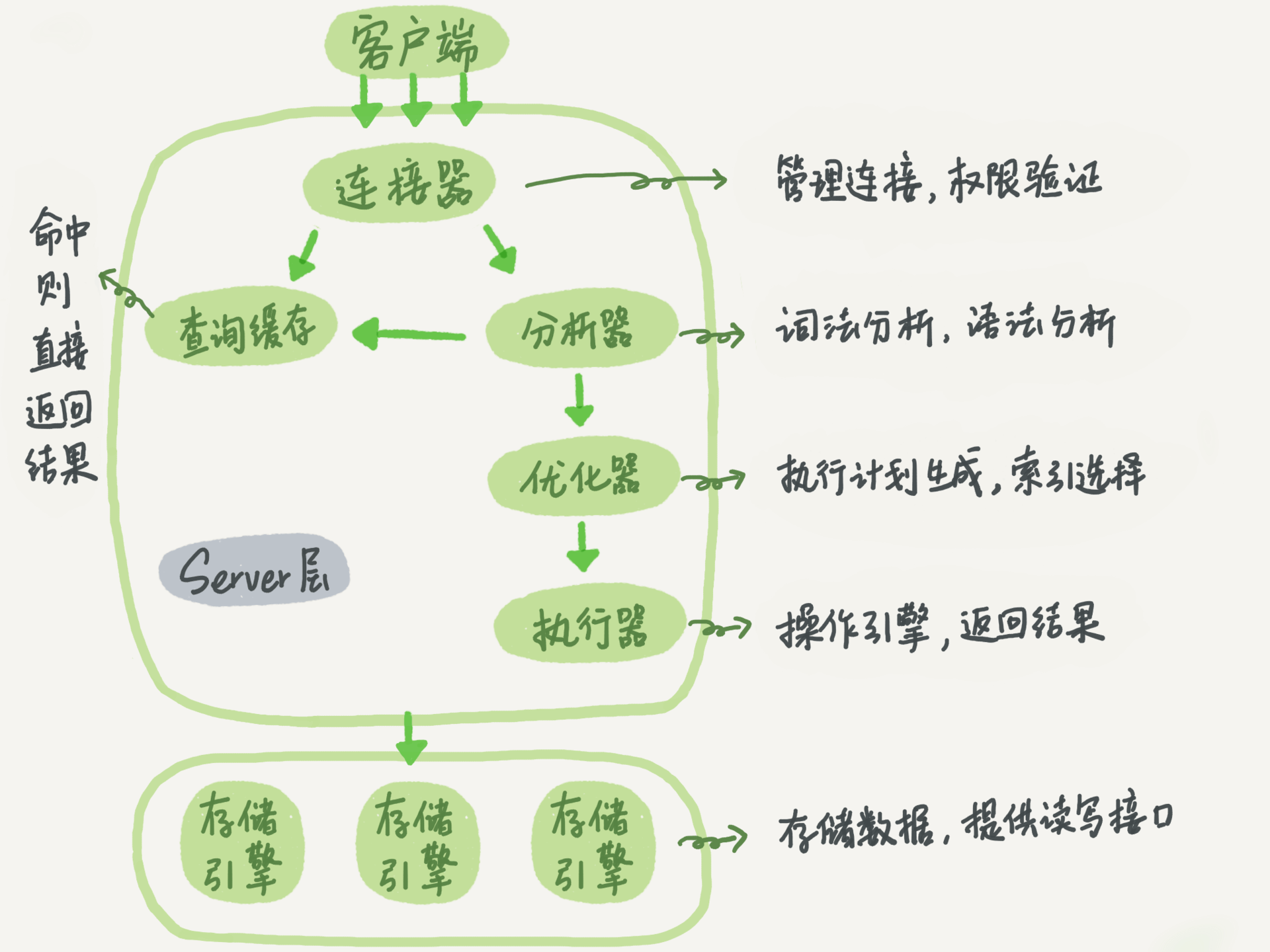
从上图可以看出整体的mysql大致可以分为两部分,server层以及存储引擎层。
server中包含mysql大部分功能,例如内置函数以及跨存储功能都在这一层实现,比如,视图,触发器,存储过程等。
存储引擎层负责数据的存储和读取,其架构是插件式的,支持INNODB\MYISAM\MEMORY等多个存储引擎。
下面会通过上面的SQL一次对每一个组件进行拆解分析。
连接器
第一步是客户端会连接到连接器,连接器判断客户端建立连接,获取权限,维持和管理链接。链接命令一般如下:
mysql -h$ip -P$port -u$user -p$pwd
在你输入如上操作之后,在完成经典的TCP三次握手之后,连接器就开始验证客户身份并到权限表查询客户权限进行鉴权操作。
链接完成后,如果不进行任何操作,这个链接就是处于空闲状态,通过show processlist命令可以看到当前所有的链接,sleep即为空闲状态。
客户端如果太长时间没有操作,连接器就会根据wait_timeout判断是否断开,默认断开时间为8小时。
数据库里面的长链接是指连接成功后,如果客户端持续请求,则使用同一个链接;短连接则意思相反。但是如果长链接太多的话可能会导致mysql出现OOM的问题,因为执行过程中的临时使用的内存是管理在链接对象里面的。这些资源会在连接断开才会释放。
解决方案如下:
- 定期断开长链接;
- 如果版本大于5.7,可以再每次执行一个比较大的操作之后,执行mysql_reset_connection来重新初始化链接资源。
查询缓存
当登录以及鉴权结束之后,我们首先会到缓存中查询相关信息,之前是不是执行过这个语句,但是不建议使用缓存,因为每次表变动都会清空缓存,可能上次的数据刚缓存,表就被改动,增加性能消耗,只是比较适合那种基础数据表。在mysql8.0之后已经完全摒弃了这个功能。
可以通过设置query_cache_type参数是否使用缓存,或者在查询的时候在查询语句上加入SQL_CACHE,实例语句如下:
select SQL_CACHE * FROM A where id = 10;
分析器
分析器主要是对当前SQL进行语义分析,分析每一个词分别代表什么,并且在这个过程中会确定当前SQL是否符合规范,并且在这个过程中也会对表以及字段进行确认。
优化器
优化器主要作用时决定我们使用查询的最优路径,例如当我们表中有多个索引,我们怎么使用索引能够较快的查询出语句,亦或者我们进行join查询的时候,我们如何查询会性能较高。
select * from t1 join t2 using(ID) where t1.c = 10 and t2.c = 20;
如上sql我们既可以取出t1表的c=10的数据,然后再根据ID关联到t2,在判断t2里面c的值是否等于20;
也可以在取出t2表的c=20的数据,然后再根据ID关联到t1,在判断t1里面c的值是否等于10;
虽然得到的结果是一致的,但是执行效率却不同。
执行器
执行器主要作用是对当前SQL根据分析器以及优化器的分析过后进行执行,在这个过程之前会先判断当前用户是否有当前表权限,然后会调用存储引擎去获取相应的数据。















 3433
3433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}