







python DataFrame结构及常用操作
Pandas模块是Python用于数据导入及整理的模块,对数据挖掘前期数据的处理工作十分有用,故此这些要好好学学。Pandas模块的数据结构主要有两:1、Series ;2、DataFrame
(一)介绍一下Series结构。
1. 概述
The Series is the primary building block of pandas and represents a one-dimensional labeled array based on the NumPy ndarray;(从书上搬来的,逃~)
大概就是说Series结构是基于NumPy的ndarray结构,是一个一维的标签矩阵(感觉跟python里的字典结构有点像)
2. 相关操作
a.创建a.1、pd.Series([list],index=[list])//以list为参数,参数为一list;index为可选参数,若不填则默认index从0开始;若添则index长度与value长度相等
import pandas as pd
s=pd.Series([1,2,3,4,5],index=['a','b','c','f','e'])
print s
>>> print s
a 1
b 2
c 3
f 4
e 5
dtype: int64a.2、pd.Series({dict})//以一字典结构为参数
import pandas as pd
s=pd.Series({'a':3,'b':4,'c':5,'f':6,'e':8})
print s
>>> print s
a 3
b 4
c 5
e 8
f 6
dtype: int64
b.取值
s[index] or s[[index的list]]
取值操作类似数组,当取不连续的多个值时可以以一list为参数
import pandas as pd
import numpy as np
v=np.random.random_sample(50)
s=pd.Series(v)
s1=s[[3,7,33]]
s2=s[1:5]
s3=s[49]
print "s1\n",s1
print "s2\n",s2
print "s3\n",s3out:
>>> print "s1\n",s1
s1
3 0.865990
7 0.523828
33 0.414595
dtype: float64
>>> print "s2\n",s2
s2
1 0.688010
2 0.474426
3 0.865990
4 0.093233
dtype: float64
>>> print "s3\n",s3
s3
0.784247740744c. head(n);.tail(n) . //取出头n行或尾n行,n为可选参数,若不填默认5
v=np.random.random_sample(50)
s=pd.Series(v)
print s.head()
print s.tail(3)
>>> print s.head()
0 0.811373
1 0.935734
2 0.378839
3 0.504579
4 0.221473
dtype: float64
>>> print s.tail(3)
47 0.520146
48 0.019284
49 0.724091
dtype: float64d、.index; .values//取出index 与values ,返回list
>>> s.index
RangeIndex(start=0, stop=50, step=1)
>>> s.values
array([ 0.81137292, 0.93573367, 0.37883921, 0.50457922, 0.22147327,
0.09006264, 0.12719384, 0.27118603, 0.7409816 , 0.33524624,
0.36469861, 0.57449298, 0.66318467, 0.57657501, 0.99264638,
0.6927176 , 0.66435956, 0.392446 , 0.45867485, 0.48974302,
0.05348471, 0.49851692, 0.07072414, 0.23676539, 0.08716939,
0.20531949, 0.47885808, 0.37940527, 0.95922879, 0.99492326,
0.52570074, 0.66845377, 0.3792169 , 0.52712225, 0.43720906,
0.48424237, 0.84413607, 0.56908045, 0.12248479, 0.2873368 ,
0.30150022, 0.65217197, 0.36276568, 0.03030543, 0.30405464,
0.70936123, 0.31237255, 0.52014629, 0.01928411, 0.72409103])
>>> type(s.values)
<type 'numpy.ndarray'>
>>> type(s.index)
<class 'pandas.indexes.range.RangeIndex'>e、Size、shape、uniqueness、counts of values
v=[10,3,2,2,np.nan]
v=pd.Series(v);
print "len():",len(v)#Series长度,包括NaN
print "shape():",np.shape(v)#矩阵形状,(,)
print "count():",v.count()#Series长度,不包括NaN
print "unique():",v.unique()#出现不重复values值
print "value_counts():\n",v.value_counts()#统计value值出现次数
>>> print "len():",len(v)#Series长度,包括NaN
len(): 5
>>> print "shape():",np.shape(v)#矩阵形状,(,)
shape(): (5,)
>>> print "count():",v.count()#Series长度,不包括NaN
count(): 4
>>> print "unique():",v.unique()#出现不重复values值
unique(): [ 10. 3. 2. nan]
>>> print "value_counts():\n",v.value_counts()#统计value值出现次数
value_counts():
2.0 2
3.0 1
10.0 1
dtype: int64f.加运算
相同index的value相加,若index并非共有的则该index对应value变为NaN
import pandas as pd
s1=pd.Series([1,2,3,4],index=[1,2,3,4])
s2=pd.Series([1,1,1,1])
s3=s1+s2
print s3
out:
>>> print s3
0 NaN
1 2.0
2 3.0
3 4.0
4 NaN
dtype: float64
>>> (二)介绍一下Series结构。
2.1 介绍 DataFrame unifies two or more Series into a single data structure.Each Series then represents a named column of the DataFrame, and instead of each column having its own index, the DataFrame provides a single index and the data in all columns is aligned to the master index of the DataFrame.
这段话的意思是,DataFrame提供的是一个类似表的结构,由多个Series组成,而Series在DataFrame中叫colums.
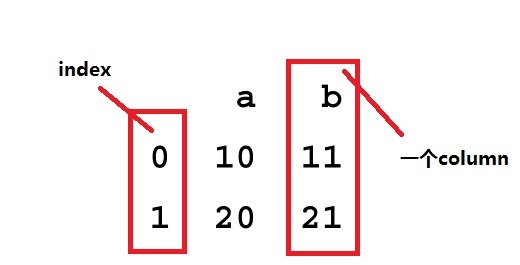
2.2 相关操作
a.create
pd.DataFrame()
参数:
1、二维array;
2、Series 列表;
3、value为Series的字典;
a.1、二维array
import pandas as pd
import numpy as np
s1=np.array([1,2,3,4])
s2=np.array([5,6,7,8])
df=pd.DataFrame([s1,s2])
print df>>> print df
0 1 2 3
0 1 2 3 4
1 5 6 7 8a.2、Series列表(效果与二维array相同)
import pandas as pd
import numpy as np
s1=pd.Series(np.array([1,2,3,4]))
s2=pd.Series(np.array([5,6,7,8]))
df=pd.DataFrame([s1,s2])
print df>>> print df
0 1 2 3
0 1 2 3 4
1 5 6 7 8
a.3、value为Series的字典结构;
import pandas as pd
import numpy as np
s1=pd.Series(np.array([1,2,3,4]))
s2=pd.Series(np.array([5,6,7,8]))
df=pd.DataFrame({"a":s1,"b":s2});
print df
>>> print df
a b
0 1 5
1 2 6
2 3 7
3 4 8注:若创建使用的参数中,array、Series长度不一样时,对应index的value值若不存在则为NaN
b.属性
b.1 .columns :每个columns对应的keys
b.2 .shape:形状,(a,b),index长度为a,columns数为b
b.3 .index;.values:返回index列表;返回value二维array
b.4 .head();.tail();
c.if-then 操作
c.1使用.ix[]
df=pd.DataFrame({"A":[1,2,3,4],"B":[5,6,7,8],"C":[1,1,1,1]})
df.ix[df.A>1,'B']= -1
print df>>> print df
A B C
0 1 5 1
1 2 -1 1
2 3 -1 1
3 4 -1 1df.ix[条件,then操作区域]
c.2使用numpy.where
df=pd.DataFrame({"A":[1,2,3,4],"B":[5,6,7,8],"C":[1,1,1,1]})
df["then"]=np.where(df.A<3,1,0)
print df>>> print df
A B C then
0 1 5 1 1
1 2 6 1 1
2 3 7 1 0
3 4 8 1 0np.where(条件,then,else)
d.根据条件选择取DataFrame
d.1 直接取值df.[]
df=pd.DataFrame({"A":[1,2,3,4],"B":[5,6,7,8],"C":[1,1,1,1]})
df=df[df.A>=2]
print df>>> print df
A B C
1 2 6 1
2 3 7 1
3 4 8 1d.2 使用.loc[]
df=pd.DataFrame({"A":[1,2,3,4],"B":[5,6,7,8],"C":[1,1,1,1]})
df=df.loc[df.A>2]
print df>>> print df
A B C
2 3 7 1
3 4 8 1e.1 groupby 形成group
df = pd.DataFrame({'animal': 'cat dog cat fish dog cat cat'.split(),
'size': list('SSMMMLL'),
'weight': [8, 10, 11, 1, 20, 12, 12],
'adult' : [False] * 5 + [True] * 2});
#列出动物中weight最大的对应size
group=df.groupby("animal").apply(lambda subf: subf['size'][subf['weight'].idxmax()])
print groupout:
>>> print group
animal
cat L
dog M
fish M
dtype: object e.2 使用get_group 取出其中一分组
df = pd.DataFrame({'animal': 'cat dog cat fish dog cat cat'.split(),
'size': list('SSMMMLL'),
'weight': [8, 10, 11, 1, 20, 12, 12],
'adult' : [False] * 5 + [True] * 2});
group=df.groupby("animal")
cat=group.get_group("cat")
print cat>>> print cat
adult animal size weight
0 False cat S 8
2 False cat M 11
5 True cat L 12
6 True cat L 12参考网址:http://blog.csdn.net/u014607457/article/details/51290582















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









