









转自:https://blog.csdn.net/xiangxizhishi/article/details/79102692
1 Storm介绍
Storm是由Twitter开源的分布式、高容错的实时处理系统,它的出现令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求。Storm常用于在实时分析、在线机器学习、持续计算、分布式远程调用和ETL等领域。
在Storm的集群里面有两种节点:控制节点(Master Node)和工作节点(Worker Node)。控制节点上面运行一个名为Nimbus的进程,它用于资源分配和状态监控;每个工作节点上面运行一个Supervisor的进程,它会监听分配给它所在机器的工作,根据需要启动/关闭工作进程。Storm集群架构如下图所示:
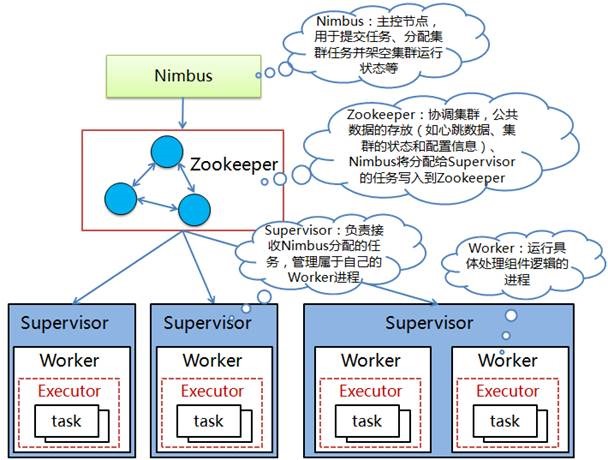
图 1 Storm集群架构
Storm集群中每个组件具体描述如下:
l Nimbus:负责在集群里面发送代码,分配工作给机器并且监控状态,在集群中只有一个,作用类似Hadoop里面的JobTracker。
l ZooKeeper:Storm重点依赖的外部资源,Nimbus、Supervisor和Worker等都是把心跳数据保存在ZooKeeper上,Nimbus也是根据ZooKeeper上的心跳和任务运行状况进行调度和任务分配的。
l Supervisor:在运行节点上,监听分配的任务,根据需要启动或关闭工作进程Worker。每一个要运行Storm的机器上都运行一个Supervisor,并且按照机器的配置设定上面分配的槽位数。
l Worker:在Supervisor上创建的一个JVM实例,Worker中运行Executor,而Executor作为Task运行的容器。
l Executor:运行时Task所在的直接容器,在Executor中执行Task的处理逻辑。一个或多个Executor实例可以运行在同一个Worker进程中,一个或多个Task可以运行于同一个Executor中;在Worker进程并行的基础上,Executor可以并行,进而Task也能够基于Executor实现并行计算
l Task:Spout/Bolt在运行时所表现出来的实体,都称为Task,一个Spout/Bolt在运行时可能对应一个或多个Spout Task或Bolt Task,与实际在编写Topology时进行配置有关。在Storm0.8之后,Task不再与物理线程对应,同一个Spout Task或Bolt Task可能会共享一个物理线程,该线程称为Executor。
Storm提交运行的程序称为Topology,它处理的最小的消息单位是一个Tuple,也就是一个任意对象的数组。Topology由Spout和Bolt构成,Spout是发出Tuple的结点,Bolt可以随意订阅某个Spout或者Bolt发出的Tuple。下图是一个Topology设计的逻辑图的例子:
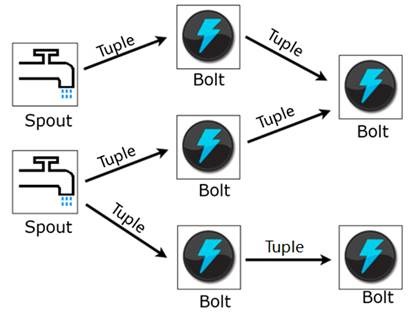
图 2 Topology设计的逻辑图
l Topology: Topology概念类似于Hadoop中的MapReduce作业,是一个用来编排、容纳一组计算逻辑组件(Spout、Bolt)的对象(Hadoop MapReduce中一个作业包含一组Map任务、Reduce任务),这一组计算组件可以按照DAG图的方式编排起来(通过选择Stream Groupings来控制数据流分发流向),从而组合成一个计算逻辑更加负责的对象,那就是Topology。一个Topology运行以后就不能停止,它会无限地运行下去,除非手动干预(显式执行bin/storm kill)或意外故障(如停机、整个Storm集群挂掉)让它终止。
l Spout: Spout是一个Topology的消息生产的源头,Spout是一个持续不断生产消息的组件,例如,它可以是一个Socket Server在监听外部Client连接并发送消息、可以是一个消息队列(MQ)的消费者、可以是用来接收Flume Agent的Sink所发送消息的服务,等等。Spout生产的消息在Storm中被抽象为Tuple,在整个Topology的多个计算组件之间都是根据需要抽象构建的Tuple消息来进行连接,从而形成流。
l Bolt:Storm中消息的处理逻辑被封装到Bolt组件中,任何处理逻辑都可以在Bolt里面执行,处理过程和普通计算应用程序没什么区别,只是需要根据Storm的计算语义来合理设置一下组件之间消息流的声明、分发和连接即可。Bolt可以接收来自一个或多个Spout的Tuple消息,也可以来自多个其它Bolt的Tuple消息,也可能是Spout和其它Bolt组合发送的Tuple消息。
l Stream Grouping:Storm中用来定义各个计算组件(Spout和Bolt)之间流的连接、分组和分发关系。Storm定义了如下7种分发策略:Shuffle Grouping(随机分组)、Fields Grouping(按字段分组)、All Grouping(广播分组)、Global Grouping(全局分组)、Non Grouping(不分组)、Direct Grouping(直接分组)、Local or Shuffle Grouping(本地/随机分组),各种策略的具体含义可以参考Storm官方文档、比较容易理解。
在Storm中可以通过组件简单串行或者组合多种流操作处理数据:
l Storm组件简单串行
这种方式是最简单最直观的,只要我们将Storm的组件(Spout或Bolt)串行起来即可实现,只需要了解编写这些组件的基本方法即可。在实际应用中,如果我们需要从某一个数据源连续地接收消息,然后顺序地处理每一个请求,就可以使用这种串行方式来处理。如果说处理单元的逻辑非常复杂,那么就需要处理逻辑进行分离,属于同一类操作的逻辑封装到一个处理组件中,做到各个组件之间弱耦合。
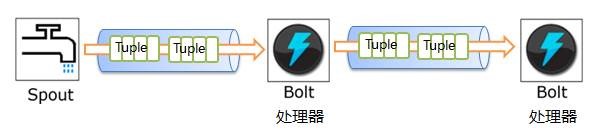
图 3 Storm组件简单串行
l Storm组合多种流操作
Storm支持流聚合操作,将多个组件的数据汇聚到同一个处理组件来统一处理,可以实现对多个Spout组件通过流聚合到一个Bolt组件(Sout到Bolt的多对一、多对多操作),也可以实现对多个Bolt通过流聚合到另一个Bolt组件(Bolt到Bolt的多对一、多对多操作)。

图 4 Storm组合多种流操作
下图是Topology的提交流程图:

图 5 Topology的提交流程图
1. 客户端通过Nimbus的接口上传程序jar包到Nimbus的Inbox目录中,上传结束后,通过提交方法向Nimbus提交一个Topology。
2. Nimbus接收到提交Topology的命令后,对接收到的程序jar包进行序列化,把序列化的结果放到Nimbus节点的stormdist目录中,同时把当前Storm运行的配置生成一个stormconf.ser文件也放到该目录中。静态的信息设置完成后,通过心跳信息分配任务到机器节点。在设定Topology所关联的Spouts和Bolts时,可以同时设置当前Spout和Bolt的Executor数目和Task数目,默认情况下,一个Topology的Task的总和与Executor的总和一致。之后,系统根据Worker的数目,尽量平均的分配这些Task的执行。其中Worker在哪个Supervisor节点上运行是由Storm本身决定的。
3. 任务分配好之后,Nimbus节点会将任务的信息提交到ZooKeeper集群,同时在ZooKeeper集群中会有Worker分派节点,这里存储了当前Topology的所有Worker进程的心跳信息。
4. Supervisor节点会不断的轮询ZooKeeper集群,在ZooKeeper的分派节点中保存了所有Topology的任务分配信息、代码存储目录和任务之间的关联关系等,Supervisor通过轮询此节点的内容,来领取自己的任务,启动Worker进程运行。
5. 一个Topology运行之后,就会不断的通过Spout来发送Stream流,通过Bolt来不断的处理接收到的数据流。
2 Spark Streaming与Storm比较
Storm和Spark Streaming都是分布式流处理的开源框架,但是它们之间还是有一些区别的,这里将进行比较并指出它们的重要的区别。
1. 处理模型以及延迟
虽然这两个框架都提供可扩展性(Scalability)和可容错性(Fault Tolerance),但是它们的处理模型从根本上说是不一样的。Storm处理的是每次传入的一个事件,而Spark Streaming是处理某个时间段窗口内的事件流。因此,Storm处理一个事件可以达到亚秒级的延迟,而Spark Streaming则有秒级的延迟。
2. 容错和数据保证
在容错数据保证方面的权衡方面,Spark Streaming提供了更好的支持容错状态计算。在Storm中,当每条单独的记录通过系统时必须被跟踪,所以Storm能够至少保证每条记录将被处理一次,但是在从错误中恢复过来时候允许出现重复记录,这意味着可变状态可能不正确地被更新两次。而Spark Streaming只需要在批处理级别对记录进行跟踪处理,因此可以有效地保证每条记录将完全被处理一次,即便一个节点发生故障。虽然Storm的 Trident library库也提供了完全一次处理的功能。但是它依赖于事务更新状态,而这个过程是很慢的,并且通常必须由用户实现。
简而言之,如果你需要亚秒级的延迟,Storm是一个不错的选择,而且没有数据丢失。如果你需要有状态的计算,而且要完全保证每个事件只被处理一次,Spark Streaming则更好。Spark Streaming编程逻辑也可能更容易,因为它类似于批处理程序,特别是在你使用批次(尽管是很小的)时。
3. 实现和编程API
Storm主要是由Clojure语言实现,Spark Streaming是由Scala实现。如果你想看看这两个框架是如何实现的或者你想自定义一些东西你就得记住这一点。Storm是由BackType和 Twitter开发,而Spark Streaming是在UC Berkeley开发的。
Storm提供了Java API,同时也支持其他语言的API。 Spark Streaming支持Scala和Java语言(其实也支持Python)。另外Spark Streaming的一个很棒的特性就是它是在Spark框架上运行的。这样你就可以想使用其他批处理代码一样来写Spark Streaming程序,或者是在Spark中交互查询。这就减少了单独编写流批量处理程序和历史数据处理程序。
4. 生产支持
Storm已经出现好多年了,而且自从2011年开始就在Twitter内部生产环境中使用,还有其他一些公司。而Spark Streaming是一个新的项目,并且在2013年仅仅被Sharethrough使用(据作者了解)。
Storm是 Hortonworks Hadoop数据平台中流处理的解决方案,而Spark Streaming出现在 MapR的分布式平台和Cloudera的企业数据平台中。除此之外,Databricks是为Spark提供技术支持的公司,包括了Spark Streaming。
5. 集群管理集成
尽管两个系统都运行在它们自己的集群上,Storm也能运行在Mesos,而Spark Streaming能运行在YARN 和 Mesos上。














 1275
1275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









