







1、stream之map、collect的用法
1.1、将list中每个对象的recordId放到List<String>变量中
List<String> recordIds = list.stream().map(x->x.getRecordId()).collect(Collectors.toList());
1.2、将detailAttachesOfOne中每个对象的imageUrl用逗号分隔作为字符串返回。
private String getImagePaths(List<SafeInspectionAttach> detailAttachesOfOne){
if(detailAttachesOfOne!=null && !detailAttachesOfOne.isEmpty()){
return detailAttachesOfOne.stream().map(x->x.getImageUrl()).collect(Collectors.joining( "," ));
}
return null;
}
参考stream之map的用法_stream().map_江西昊仔的博客-CSDN博客
2、fitler用法
将detailAttaches中referenceId等于detailId的对象放到List<SafeInspectionAttach>中
List<SafeInspectionAttach> detailAttachesOfOne = detailAttaches.stream().filter(x->x.getReferenceId().equals(detailId)).collect(Collectors.toList());
3、reduce方法
3.1、方法有2个参数的,方法定义为:T reduce(T identity, BinaryOperator<T> accumulator);
3.1.1、reduce的作用是把stream中的元素给组合起来,我们可以传入一个初始值identity,它会按照我们的计算方式依次拿流中的元素和初始化值进行计算,计算结果再和后面的元素计算,例如
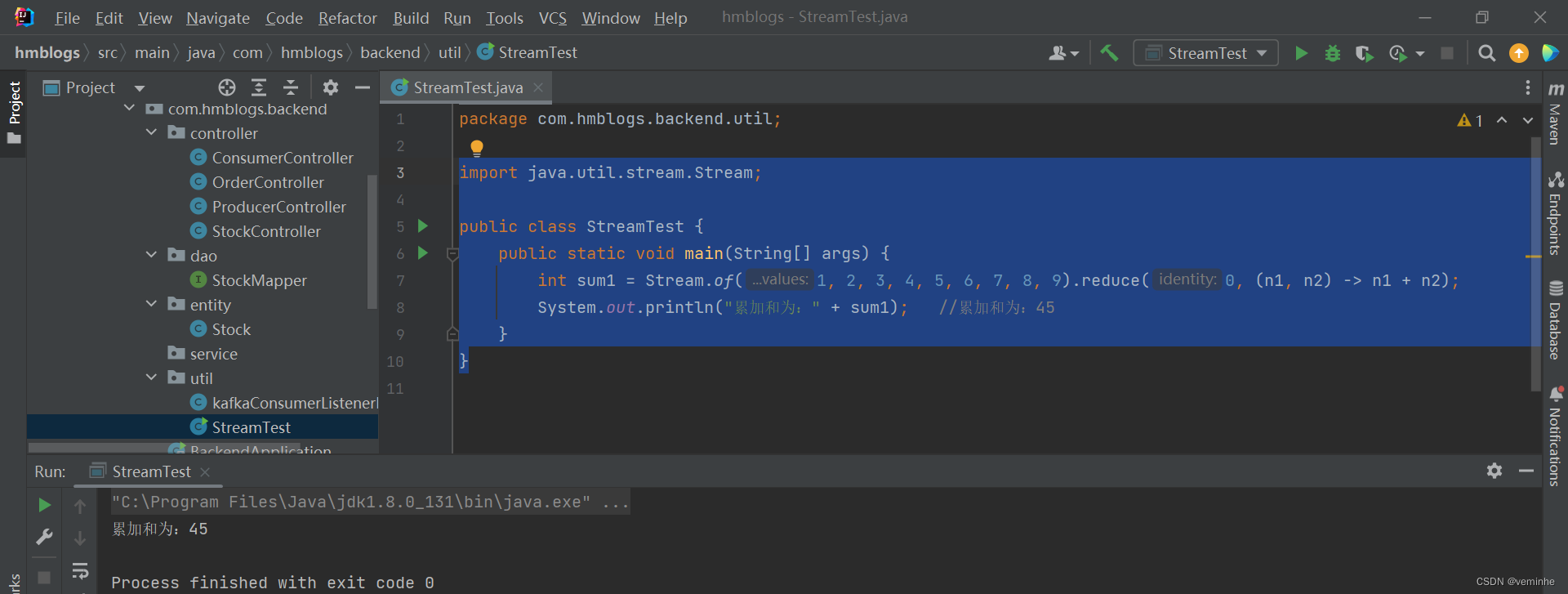
import java.util.stream.Stream;
public class StreamTest {
public static void main(String[] args) {
int sum1 = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).reduce(0, (n1, n2) -> n1 + n2);
System.out.println("累加和为:" + sum1); //累加和为:45
}
}
3.1.2、并行和串行
使用Stream.parallel()或者parallelStream()的方法开启并行模式,使用Stream.sequential()开启串行模式,默认开启的是串行模式。
并行模式可以简单理解为在多线程中执行,每个线程中单独执行它的任务。串行则是在单一线程中顺序执行。
3.1.3、并行模式下,identity的指定是有要求的
identity是reduce的初始化值,但是在并行模式下,这个值不能随意指定
import java.util.stream.Stream;
public class StreamTest {
public static void main(String[] args) {
Integer sum1 = Stream.of(1, 2, 3).reduce(100, (integer, integer2) -> integer + integer2);
System.out.println("累加和为:" + String.valueOf(sum1)); //累加和为:106
Integer sum2 = Stream.of(1, 2, 3).parallel().reduce(100, (integer, integer2) -> integer + integer2);
System.out.println("累加和为:" + sum2); //累加和为:306
}
}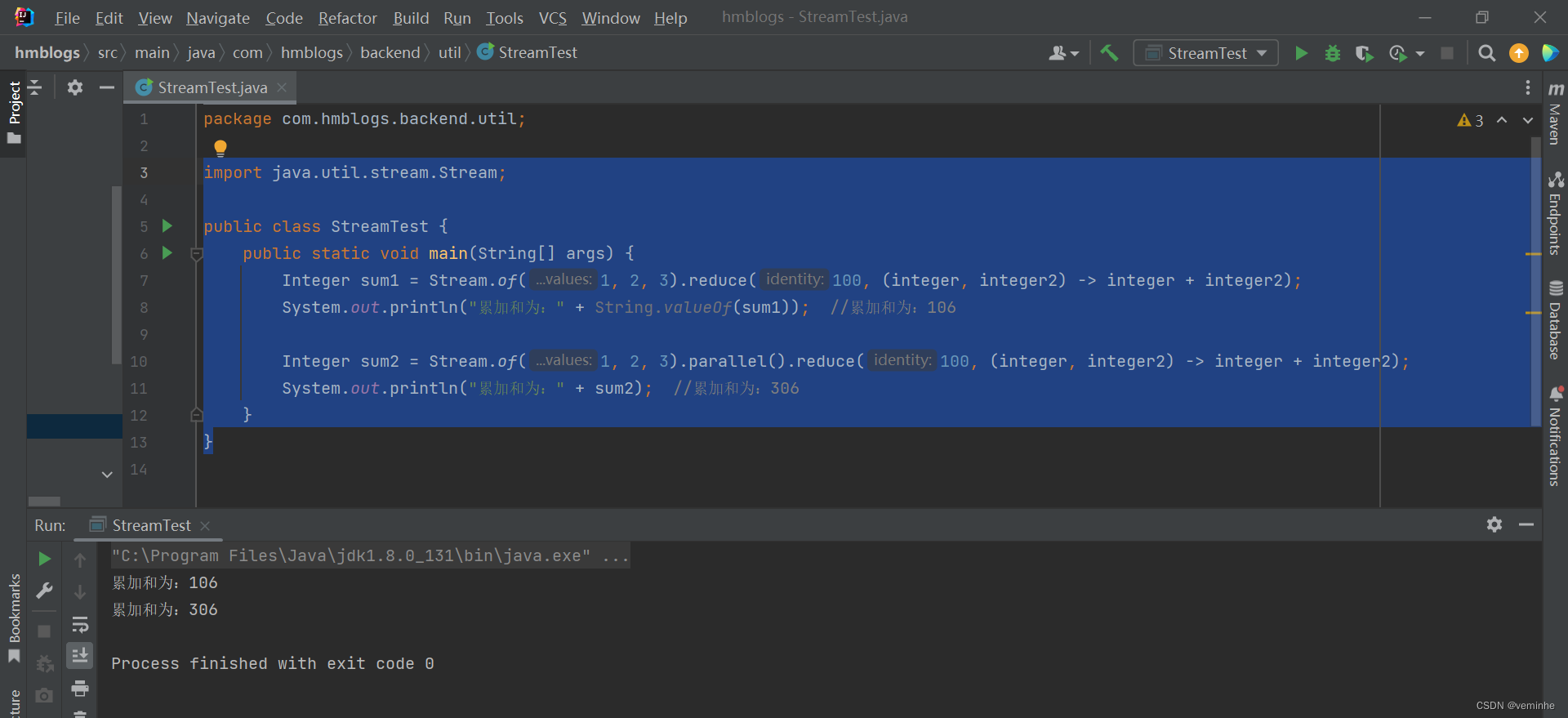
非并行计算和并行计算的结果居然不一样,我们在代码里面打印试试:
import java.util.function.BinaryOperator;
import java.util.stream.Stream;
public class StreamTest {
public static void main(String[] args) {
Integer sum2 = Stream.of(1, 2, 3).parallel().reduce(100, new BinaryOperator<Integer>() {
@Override
public Integer apply(Integer n1, Integer n2) {
System.out.println(Thread.currentThread().getName()+">>>n1>>>"+n1+",n2>>>>"+n2);
return n1 + n2;
}
});
System.out.println("累加和为:" + sum2); //累加和为:306
}
}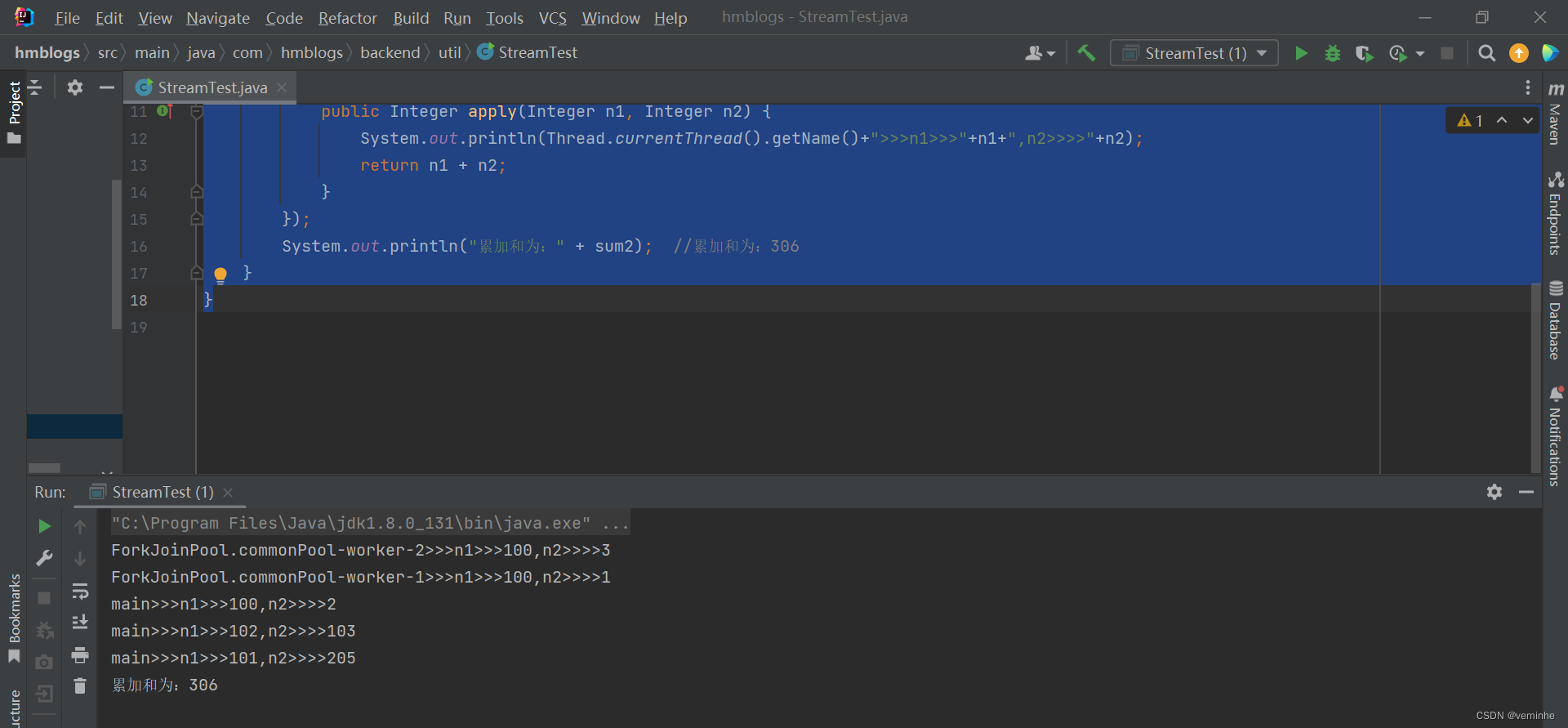 由上面的打印结果可以看出:在并行计算的时候,每个线程的初始累加值都是100,最后3个线程加出来的结果就是306
由上面的打印结果可以看出:在并行计算的时候,每个线程的初始累加值都是100,最后3个线程加出来的结果就是306
所以这里我们传入100是不对的,因为sum(100+1)!= 1。并行计算中,这里sum方法的identity只能是0。
如果我们用 0 作为identity,则stream和parallelStream计算出的结果是一样的。这就是identity的真正意图。
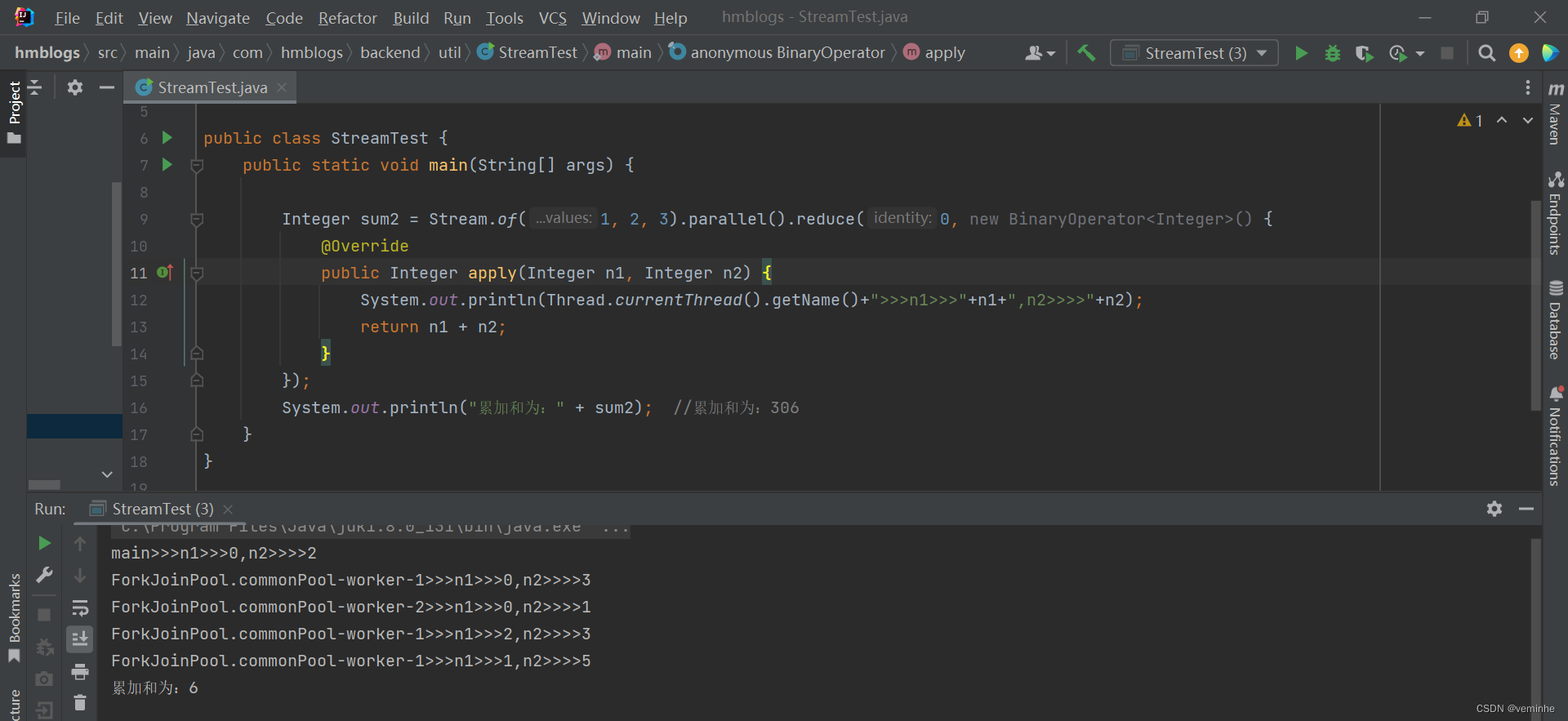
注意:计算求积时,初始值必须设置为1
3.2 、方法有1个参数的,方法定义为:Optional<T> reduce(BinaryOperator<T> accumulator);
解析:
1)该方法接受一个BinaryOperator参数,BinaryOperator是一个@FunctionalInterface,继承 BiFunction,需要实现方法:R apply(T t, U u);
2)accumulator告诉reduce方法怎么去累计stream中的数据
import java.util.Optional;
import java.util.function.BinaryOperator;
import java.util.stream.Stream;
public class StreamTest {
public static void main(String[] args) {
Optional<Integer> opt = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).reduce(new BinaryOperator<Integer>() {
@Override
public Integer apply(Integer acc, Integer n) {
return acc + n;
}
});
if (opt.isPresent()) {
System.out.println("累加和为:" + opt.get());
}
}
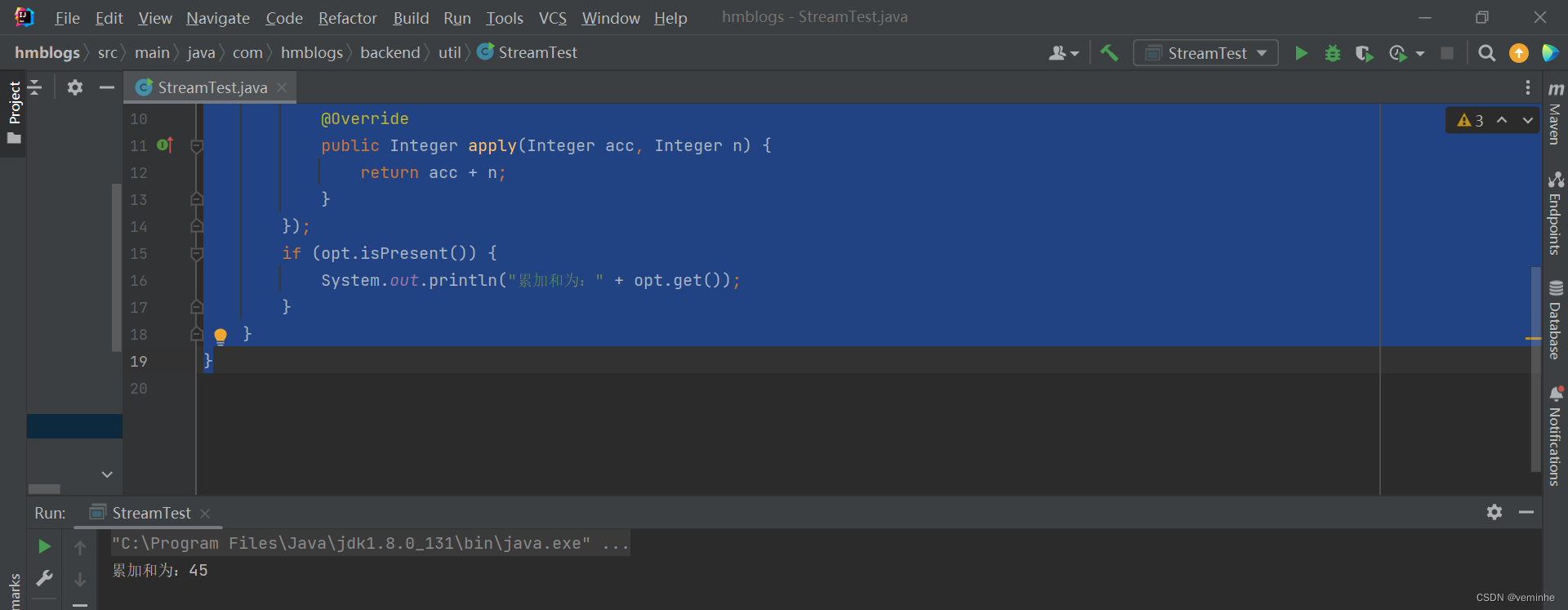
}返回值类型为Optional,这是因为Stream的元素有可能是0个,这样就没法调用reduce()的聚合函数了,因此返回Optional对象,需要进一步判断结果是否存在。
执行结果如下:
3.3、方法有3个参数的,方法定义为:<U> U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> combiner);
3.3.1、 每个参数的说明
identity:给定一个初始值
accumulator:基于初始值,对元素进行收集归纳
combiner:对每个accumulator返回的结果进行合并,此参数只有在并行模式中生效
说明:
1)和前面的方法不同的是,多了一个combiner,这个combiner用来合并多线程计算的结果
2)BinaryOperator<U> combiner 操作的对象是第二个参数BiFunction<U,? super T,U> accumulator的返回值
3.3.2、 内部的计算方式如下:
1 U result = identity
2 for(T element: this stream)
3 result = accumulator.apply(result,element)
4
5 return result;
3.3.3、 参数2和参数3的区别
大家可能注意到了为什么accumulator的类型是BiFunction而combiner的类型是BinaryOperator?
public interface BinaryOperator<T> extends BiFunction<T,T,T>
BinaryOperator是BiFunction的子接口。BiFunction中定义了要实现的apply方法。reduce底层方法的实现只用到了apply方法,并没有用到接口中其他的方法,所以猜测这里的不同只是为了简单的区分。
3.3.4、举例
例一:
串行模式,初始化值identity为0
import java.util.stream.Stream;
public class StreamTest {
public static void main(String[] args) {
int sum = Stream.of(1, 2, 3, 4)
.reduce(0, (n1, n2) -> {
int ret = n1 + n2;
System.out.println(n1 + "(n1) + " + n2 + "(n2) = " + ret);
return ret;
}, (s1, s2) -> {
int ret = s1 + s2;
System.out.println(s1 + "(s1) + " + s2 + "(s2) = " + ret);
return ret;
});
System.out.println("sum:" + sum);
}
}打印结果如下:
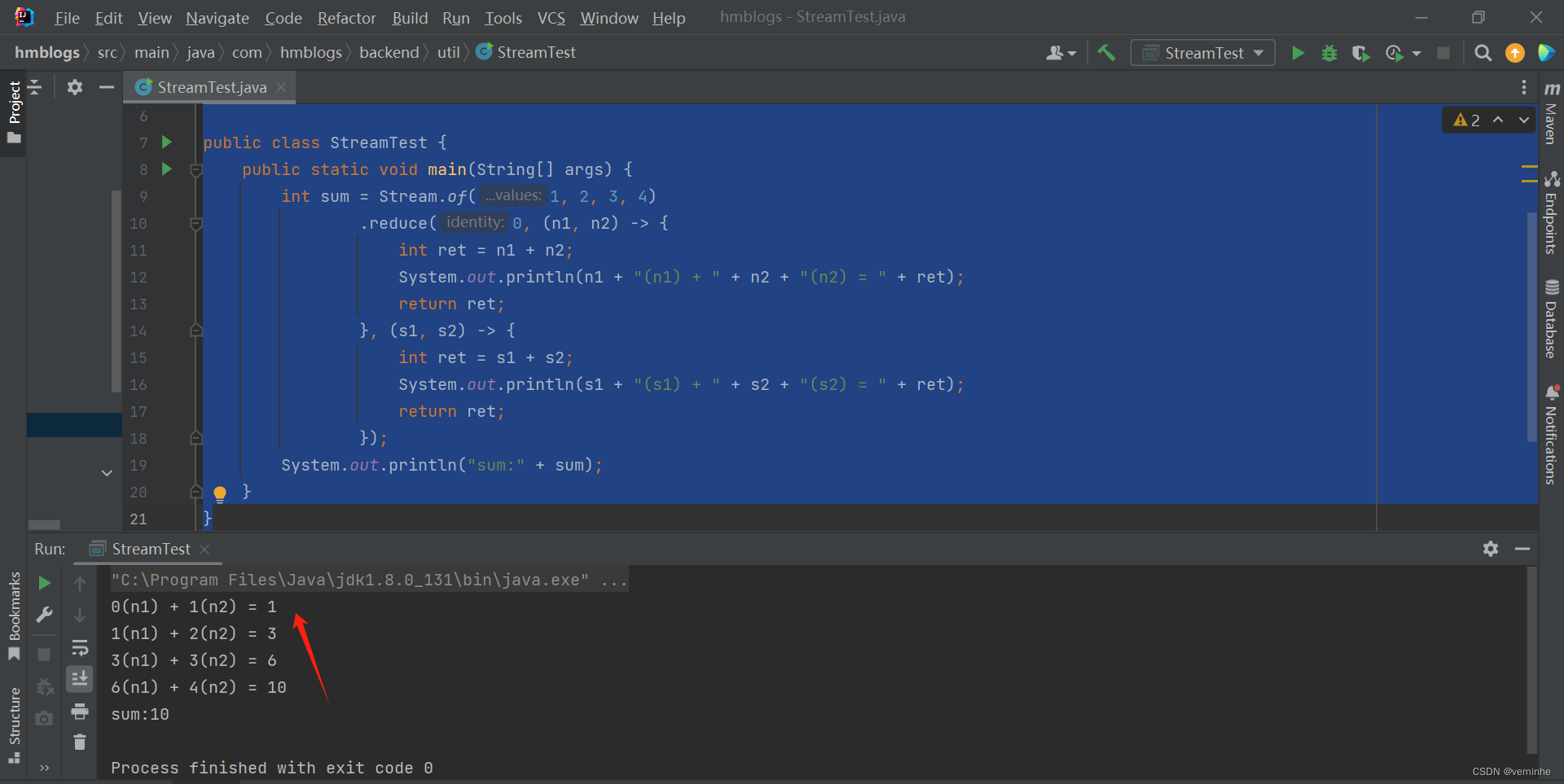
例二:
并行模式,初始化值identity为0
import java.util.stream.Stream;
public class StreamTest {
public static void main(String[] args) {
int sum = Stream.of(1, 2, 3, 4)
.parallel()
.reduce(0, (n1, n2) -> {
int ret = n1 + n2;
System.out.println(n1 + "(n1) + " + n2 + "(n2) = " + ret);
return ret;
}, (s1, s2) -> {
int ret = s1 + s2;
System.out.println(s1 + "(s1) + " + s2 + "(s2) = " + ret);
return ret;
});
System.out.println("sum:" + sum);
}
}截图如下:
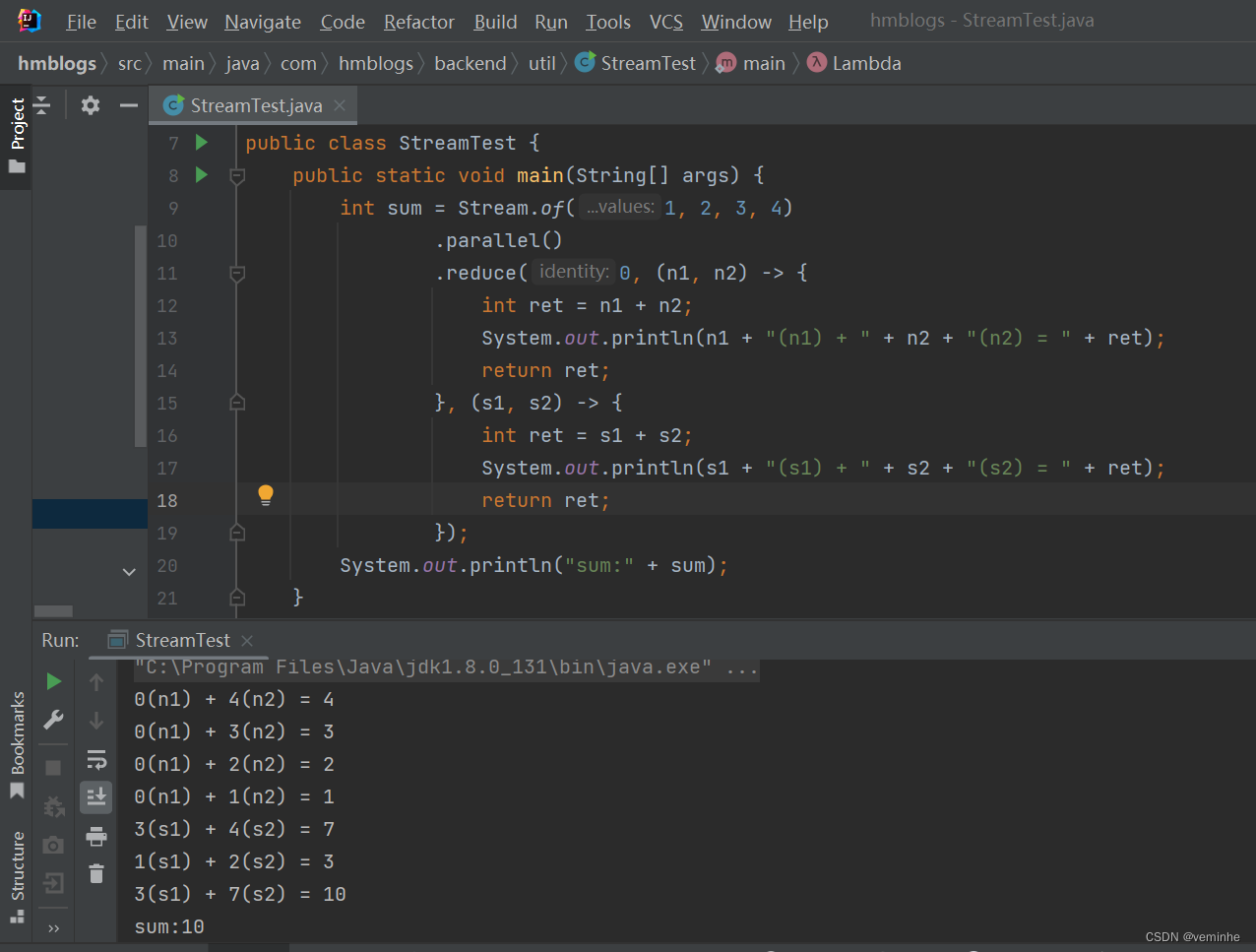
例三:
并行模式,初始化值identity为1
import java.util.stream.Stream;
public class StreamTest {
public static void main(String[] args) {
int sum = Stream.of(1, 2, 3, 4)
.parallel()
.reduce(1, (n1, n2) -> {
int ret = n1 + n2;
System.out.println(n1 + "(n1) + " + n2 + "(n2) = " + ret);
return ret;
}, (s1, s2) -> {
int ret = s1 + s2;
System.out.println(s1 + "(s1) + " + s2 + "(s2) = " + ret);
return ret;
});
System.out.println("sum:" + sum);
}
}打印截图如下:
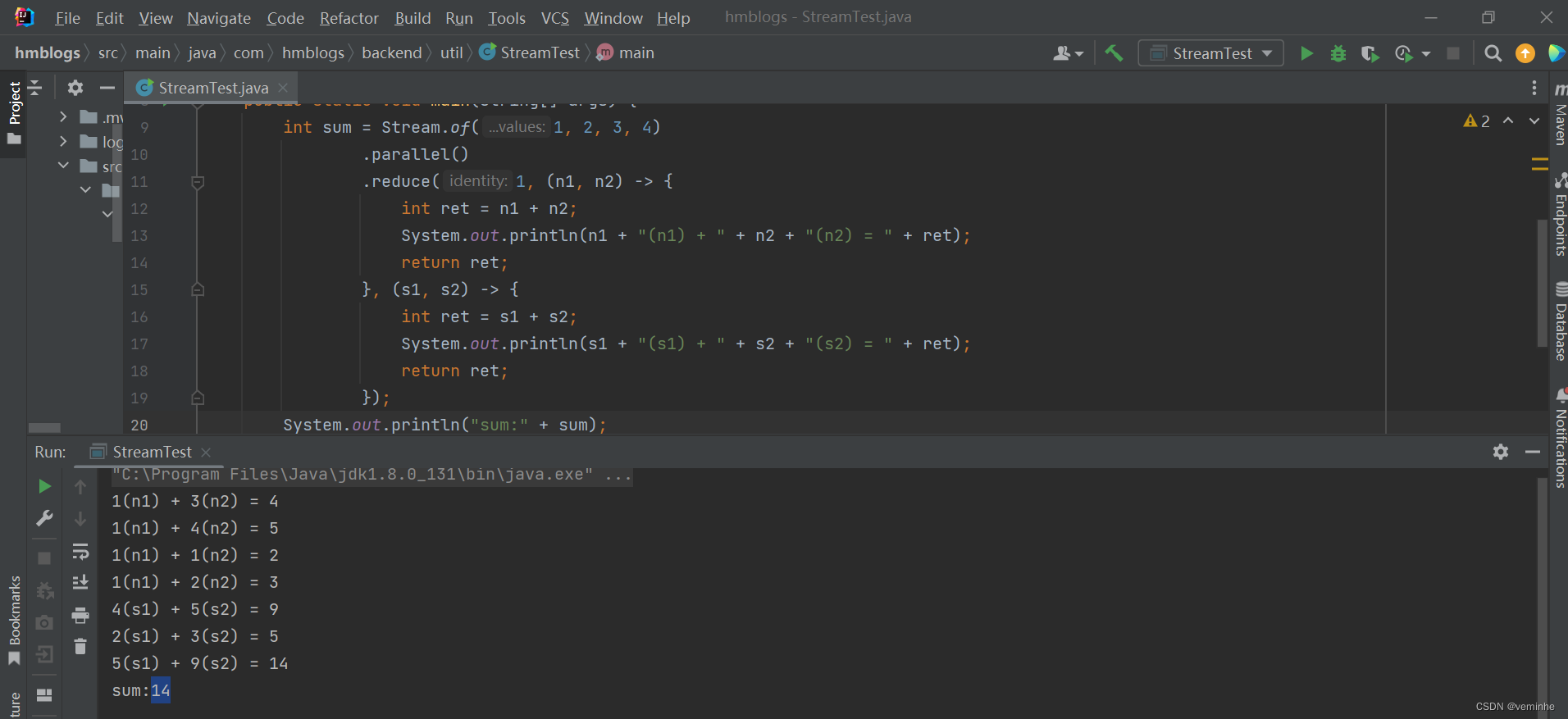
预期的结果应该是11才对,即1 + 1 + 2 + 3 + 4。可以看到在并行模式下对identity的值是有要求的。 必须满足公式:accumulator.apply(identity, t) == t
3.3.5、分析过程
这里accumulator.apply(identity, t) == t 即为:accumulator.apply(1, 1) == 1,使用数学表达式表示:
1(identity) + 1 == 1
显然这个等式是不成立的,把identity改成0则公式成立:0 + 1 == 1
紧接着,对于combiner参数,需要满足另一个公式:
combiner.apply(u, accumulator.apply(identity, t)) == accumulator.apply(u, t)
t:表示第一个参数
u:表示第二个参数
在这个例子中,我们取第一次执行combiner情况: 4(s1) + 5(s2) = 9,套用公式即为:
combiner.apply(5, accumulator.apply(1, 4)) == accumulator.apply(5, 4)
在这里u=5,identity=1,t=4
转换成数学表达式为:5 + (1 + 4) == 5 + 4
显然这个等式是不成立的,把identity改成0,等式就成立了:5 + (0 + 4) == 5 + 4
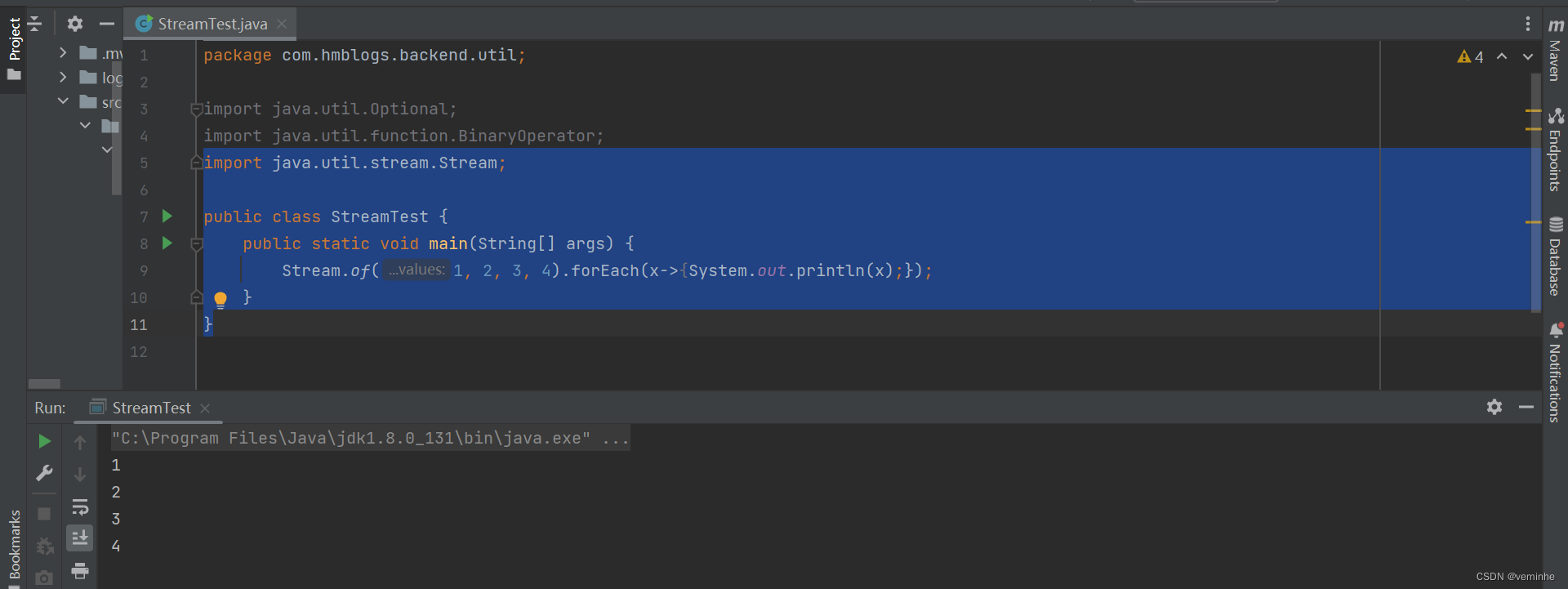
4、forEach循环
import java.util.stream.Stream;
public class StreamTest {
public static void main(String[] args) {
Stream.of(1, 2, 3, 4).forEach(x->{System.out.println(x);});
}
}打印结果如下:















 1189
1189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









