







pytorch环境
# LSTM是一种特殊的递归神经网络(RNN),通过引入门控机制克服了普通RNN的梯度消失和梯度爆炸问题
# 其核心包括三个门:输入门、遗忘门和输出门,能够高效地捕获序列数据中的长依赖性
# 数据集来源:生成一年的购物消费数据(每天的消费金额)通过时间序列的方式,利用过去的数据预测未来一周的消费趋势
# 数据生成与预处理
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset
# 生成模拟数据
# 设置随机数生成器的种子,确保每次运行代码时生成的随机数是相同的
np.random.seed(42)
days = 365
# 每日消费值 = 基准值(100) + 周期性波动(±10) + 随机噪声(±5的随机扰动)
data = 100 + 10 * np.sin(np.linspace(0, 3 * np.pi, days)) + 5 * np.random.randn(days)
# 数据集准备
# 定义df为每一天的金额数据
df = pd.DataFrame(data, columns=["amount"])
df["day"] = range(len(df))
df.set_index("day", inplace=True)
# 数据归一化
# 将数据缩放到[0, 1]
scaler = MinMaxScaler()
# 对df中的"amount"列进行归一化处理,并将结果存储在新的列"amount_scaled"中
df["amount_scaled"] = scaler.fit_transform(df[["amount"]])
# 构建时间序列数据,将原始时间序列数据转换为适合LSTM输入的数据
def create_sequences(data, seq_length):
# 初始化列表
xs, ys = [], []
# 循环创建序列
for i in range(len(data) - seq_length):
x = data[i:i + seq_length]
y = data[i + seq_length]
xs.append(x)
ys.append(y)
return np.array(xs), np.array(ys)
# 使用过去7天的数据来预测
seq_length = 7
X, y = create_sequences(df["amount_scaled"].values, seq_length)
# 数据集划分
# 取数据的80%作为训练集
train_size = int(len(X) * 0.8)
# 将前train_size个样本分配给训练集,将剩余的样本分配给测试集
X_train, y_train = X[:train_size], y[:train_size]
X_test, y_test = X[train_size:], y[train_size:]
# 转换为Tensor(使用PyTorch进行模型训练和推理的必要步骤)
X_train, y_train = torch.Tensor(X_train), torch.Tensor(y_train)
X_test, y_test = torch.Tensor(X_test), torch.Tensor(y_test)
# LSTM模型定义
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
# input_size:时间步输入特征的维度
# hidden_size:隐藏层中每个时间步的输出维度
# num_layers:LSTM网络层的数量
# output_size:模型最终输出的维度
super(LSTM, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# 初始化LSTM层
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
# 将LSTM的输出映射到最终的预测值
self.fc = nn.Linear(hidden_size, output_size)
# 前向传播
def forward(self, x):
# 初始化隐藏状态和细胞状态
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
# 将输入x和初始状态(h0, c0)传入LSTM层,得到输出out和最终状态
out, _ = self.lstm(x, (h0, c0))
# 提取LSTM输出中最后一个时间步的输出,将最后一个时间步的输出传入全连接层,得到最终预测值
out = self.fc(out[:, -1, :])
return out
# 模型初始化
input_size = 1
hidden_size = 50
num_layers = 2
output_size = 1
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 定义设备
model = LSTM(input_size, hidden_size, num_layers, output_size).to(device) # 模型移到CPU上
# 定义损失函数和优化器
# 均方误差损失函数,用于衡量预测值和真实值之间的差异
criterion = nn.MSELoss()
# 更新模型参数以最小化损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 创建数据加载器,将训练集和测试集打包成批次数据,便于模型训练和评估
train_loader = DataLoader(list(zip(X_train, y_train)), batch_size=32, shuffle=True)
test_loader = DataLoader(list(zip(X_test, y_test)), batch_size=32, shuffle=False)
# 训练过程
# 设置训练轮数和损失记录列表
epochs = 50
train_losses = []
test_losses = []
# 训练循环
for epoch in range(epochs):
model.train()
train_loss = 0
# 遍历训练数据加载器
for X_batch, y_batch in train_loader:
# 数据预处理,在数据的最后一个维度添加一个维度,以匹配模型的输入要求
X_batch = X_batch.unsqueeze(-1).to(device)
y_batch = y_batch.unsqueeze(-1).to(device)
# 清零梯度(在每次反向传播之前,将优化器的梯度清零,避免梯度累积)
optimizer.zero_grad()
# 前向传播:将输入数据X_batch传入模型,得到预测输出outputs
outputs = model(X_batch)
# 计算损失:计算预测值outputs和真实值y_batch之间的损失
loss = criterion(outputs, y_batch)
# 反向传播:计算损失对模型参数的梯度
loss.backward()
# 使用优化器更新模型参数,以最小化损失
optimizer.step()
# 累加训练损失
train_loss += loss.item()
# 计算平均训练损失(每个epoch的总损失除以批次数),并将其添加到train_losses列表中
train_losses.append(train_loss / len(train_loader))
# 验证阶段
# 设置模型为评估模式
model.eval()
# 初始化测试损失
test_loss = 0
# 禁用梯度计算,减少内存消耗并加快计算速度
with torch.no_grad():
for X_batch, y_batch in test_loader:
# 数据预处理
X_batch = X_batch.unsqueeze(-1).to(device) # 修复:.to.unsqueeze → .unsqueeze().to()
y_batch = y_batch.unsqueeze(-1).to(device)
# 前向传播
outputs = model(X_batch)
# 使用均方误差损失函数criterion计算预测值outputs和真实值y_batch之间的损失
loss = criterion(outputs, y_batch)
# 将当前批次的损失累加到test_loss中
test_loss += loss.item()
# 记录平均测试损失
test_losses.append(test_loss / len(test_loader))
# 打印训练和测试损失
print(f"Epoch {epoch + 1}/{epochs}, Train Loss: {train_losses[-1]:.4f}, Test Loss: {test_losses[-1]:.4f}")
结果
Epoch 1/50, Train Loss: 0.2825, Test Loss: 0.2802
Epoch 2/50, Train Loss: 0.1161, Test Loss: 0.0582
Epoch 3/50, Train Loss: 0.0565, Test Loss: 0.0186
Epoch 4/50, Train Loss: 0.0470, Test Loss: 0.0524
Epoch 5/50, Train Loss: 0.0460, Test Loss: 0.0420
Epoch 6/50, Train Loss: 0.0413, Test Loss: 0.0233
Epoch 7/50, Train Loss: 0.0397, Test Loss: 0.0280
Epoch 8/50, Train Loss: 0.0359, Test Loss: 0.0223
Epoch 9/50, Train Loss: 0.0322, Test Loss: 0.0189
Epoch 10/50, Train Loss: 0.0277, Test Loss: 0.0122
Epoch 11/50, Train Loss: 0.0231, Test Loss: 0.0114
Epoch 12/50, Train Loss: 0.0213, Test Loss: 0.0127
Epoch 13/50, Train Loss: 0.0213, Test Loss: 0.0126
Epoch 14/50, Train Loss: 0.0209, Test Loss: 0.0123
Epoch 15/50, Train Loss: 0.0211, Test Loss: 0.0133
Epoch 16/50, Train Loss: 0.0212, Test Loss: 0.0125
Epoch 17/50, Train Loss: 0.0209, Test Loss: 0.0121
Epoch 18/50, Train Loss: 0.0210, Test Loss: 0.0121
Epoch 19/50, Train Loss: 0.0214, Test Loss: 0.0130
Epoch 20/50, Train Loss: 0.0213, Test Loss: 0.0129
Epoch 21/50, Train Loss: 0.0208, Test Loss: 0.0119
Epoch 22/50, Train Loss: 0.0207, Test Loss: 0.0120
Epoch 23/50, Train Loss: 0.0211, Test Loss: 0.0148
Epoch 24/50, Train Loss: 0.0220, Test Loss: 0.0141
Epoch 25/50, Train Loss: 0.0206, Test Loss: 0.0138
Epoch 26/50, Train Loss: 0.0212, Test Loss: 0.0121
Epoch 27/50, Train Loss: 0.0210, Test Loss: 0.0119
Epoch 28/50, Train Loss: 0.0214, Test Loss: 0.0123
Epoch 29/50, Train Loss: 0.0205, Test Loss: 0.0130
Epoch 30/50, Train Loss: 0.0214, Test Loss: 0.0118
Epoch 31/50, Train Loss: 0.0218, Test Loss: 0.0126
Epoch 32/50, Train Loss: 0.0218, Test Loss: 0.0135
Epoch 33/50, Train Loss: 0.0209, Test Loss: 0.0125
Epoch 34/50, Train Loss: 0.0206, Test Loss: 0.0128
Epoch 35/50, Train Loss: 0.0209, Test Loss: 0.0118
Epoch 36/50, Train Loss: 0.0209, Test Loss: 0.0120
Epoch 37/50, Train Loss: 0.0209, Test Loss: 0.0132
Epoch 38/50, Train Loss: 0.0216, Test Loss: 0.0132
Epoch 39/50, Train Loss: 0.0210, Test Loss: 0.0129
Epoch 40/50, Train Loss: 0.0210, Test Loss: 0.0124
Epoch 41/50, Train Loss: 0.0212, Test Loss: 0.0136
Epoch 42/50, Train Loss: 0.0220, Test Loss: 0.0142
Epoch 43/50, Train Loss: 0.0223, Test Loss: 0.0142
Epoch 44/50, Train Loss: 0.0218, Test Loss: 0.0115
Epoch 45/50, Train Loss: 0.0204, Test Loss: 0.0119
Epoch 46/50, Train Loss: 0.0207, Test Loss: 0.0117
Epoch 47/50, Train Loss: 0.0210, Test Loss: 0.0119
Epoch 48/50, Train Loss: 0.0204, Test Loss: 0.0119
Epoch 49/50, Train Loss: 0.0207, Test Loss: 0.0117
Epoch 50/50, Train Loss: 0.0209, Test Loss: 0.0116进程已结束,退出代码为 0
# 原始数据与归一化结果
# 第一个子图:原始数据
plt.figure(figsize=(10, 10))
plt.subplot(2, 1, 1)
plt.plot(df.index, df["amount"], label="Original Data", color='blue')
plt.title("Original Data")
plt.ylabel("Amount")
plt.legend()
# 蓝色曲线展示了原始数据随时间的波动情况
# 数据呈现出明显的周期性波动,同时整体上有一些趋势性的变化
# 第二个子图:归一化数据
plt.subplot(2, 1, 2)
plt.plot(df.index, df["amount_scaled"], label="Scaled Data", color='orange')
plt.title("Scaled Data")
plt.xlabel("Scale Data")
plt.ylabel("Scale Amount")
plt.legend()
# 橙色曲线展示了归一化后的数据随时间的变化
# 归一化后的数据保留了原始数据的波动和趋势特征,数值范围被压缩到0到1之间
plt.tight_layout()
plt.show() 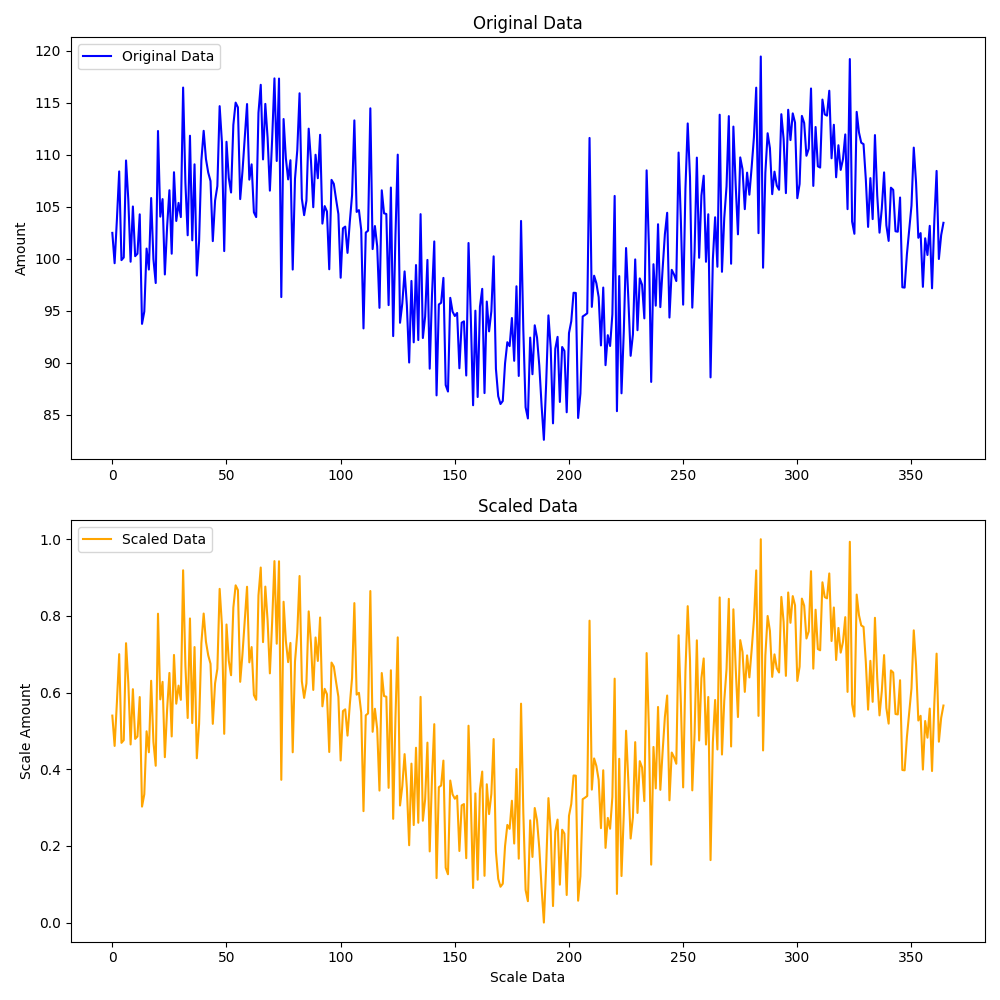
# 训练与测试损失
plt.figure(figsize=(10, 6))
plt.plot(train_losses, label="Train Loss", color='green')
plt.plot(test_losses, label="Test Loss", color='red')
plt.title("Train and Test Loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()
# 绿色曲线表示训练集上的损失
# 红色曲线表示测试集上的损失
# 拟合能力:模型在训练集上表现良好,训练损失较低,说明模型能够很好地拟合训练数据 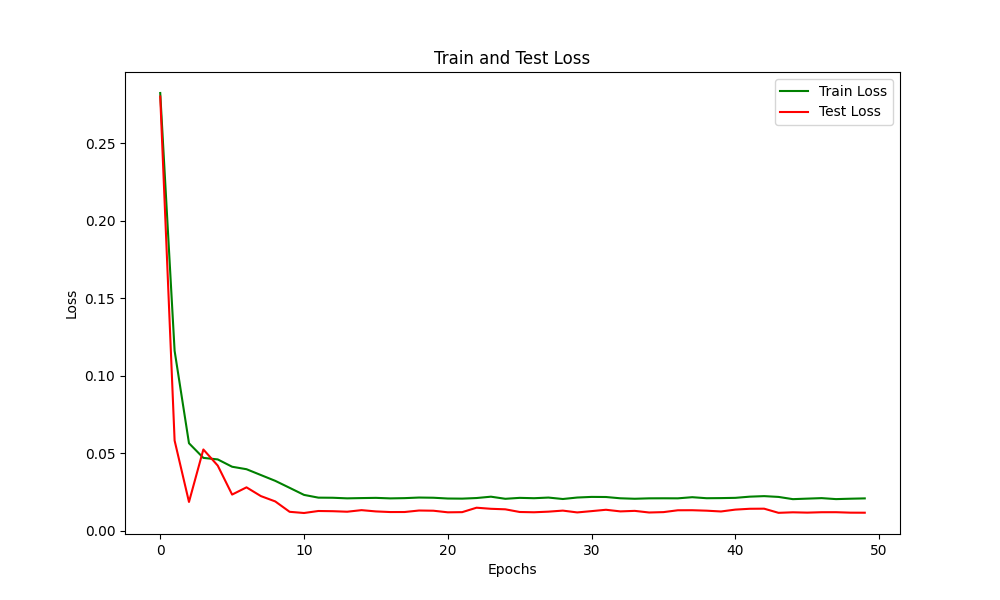
# 预测结果对比
model.eval()
with torch.no_grad():
X_test = X_test.unsqueeze(-1)
predictions = model(X_test).squeeze(-1).numpy()
plt.figure(figsize=(10, 6))
plt.plot(range(len(y_test)), y_test.numpy(), label="True Values", color='blue')
plt.plot(range(len(predictions)), predictions, label="Predicted Values", color='orange')
plt.title("True vs Predicted Values")
plt.legend
plt.show()
# 真实值曲线:y_test.numpy()是真实值数组,使用蓝色表示
# 预测值曲线:predictions是模型预测值数组,使用橙色表示
# x轴表示测试集样本的索引,测试集中的每个时间点,y轴表示归一化后的消费金额,范围从0.4到1.0
# 大部分波动一致,在峰值时存在偏差,说明模型在捕捉短期剧烈波动方面可能还不够精准 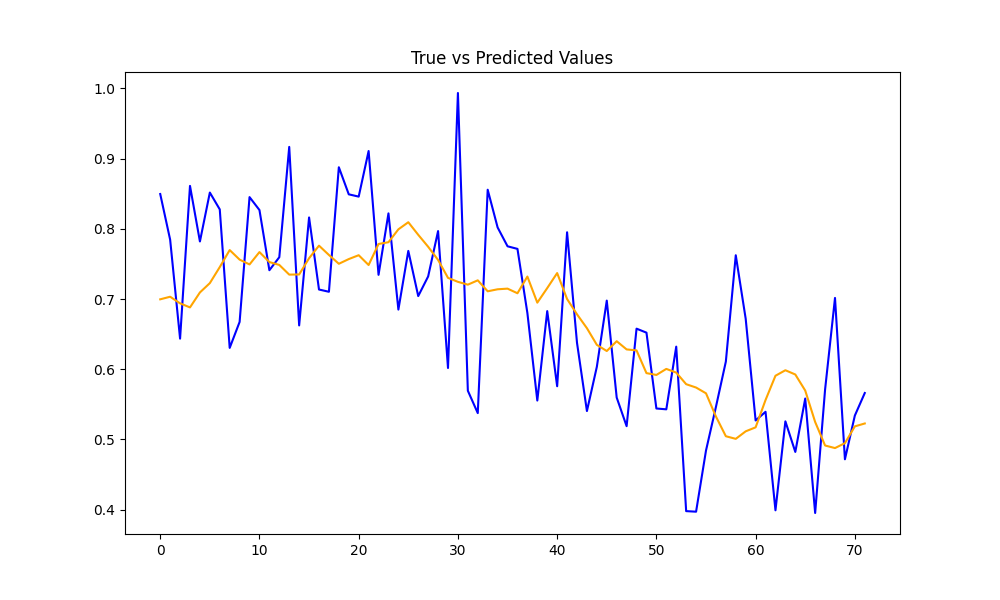
# 未来趋势预测
# 利用最后一组数据预测未来7天
future_inputs = X_test[-1].unsqueeze(0)
future_predictions = []
# 模型评估与递归预测
model.eval()
for _ in range(7):
with torch.no_grad():
# 将当前输入数据传入模型,得到预测值
pred = model(future_inputs)
future_predictions.append(pred.item()) # 将预测值转换为标量并存储
# # 更新 future_inputs,移除第一个时间步,添加预测值
pred = pred.unsqueeze(-1)
# 将新的预测值添加到future_inputs的末尾,并移除第一个时间步,以保持输入序列的长度不变
future_inputs = torch.cat((future_inputs[: ,1:, :], pred), dim=1)
# 可视化
plt.figure(figsize=(10, 6))
plt.plot(range(7), future_predictions, label="Future Predictions", color="purple", marker='o')
plt.title("Future Consumption Predictions")
plt.xlabel("Day")
plt.ylabel("Predicted Value")
plt.legend()
plt.show()
# 预测值在7天内呈现出先上升后下降再上升的趋势
# 预测值的波动与历史数据的波动特征相符,表明模型在一定程度上捕捉到了数据的变化规律 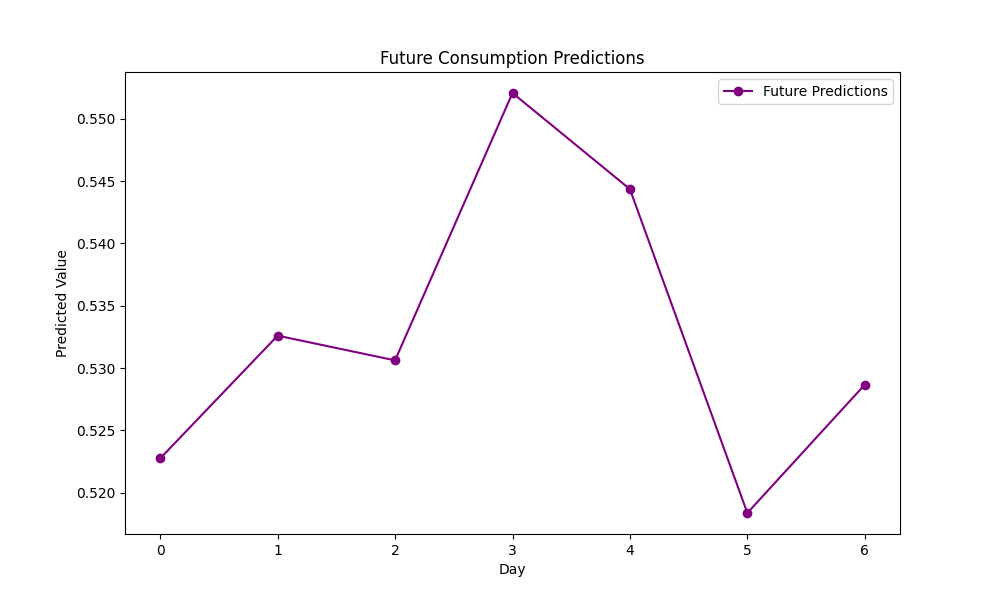



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









